

Googleが小型AIを用いて投機的予測を実行することで大型AIの処理を高速化する技術「Multi-token-prediction(マルチトークン予測)」を発表しました。
Multi-token-prediction in Gemma 4
https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/?linkId=61725841
マルチトークン予測で Gemma 4 を高速化する | Google AI for Developers
https://ai.google.dev/gemma/docs/mtp/overview?hl=ja
既存のAIモデルは複雑な推論と単純な推論に同等規模の計算処理を必要とします。例えば「猿も木から」に続く単語は「落ちる」であると容易に推測できますが、AIは「落ちる」という単語を導くために複雑な推論と同じくらいの計算処理を実行してしまいます。
マルチトークン予測はMTPドラフターと呼ばれる小型AIを用いて次のトークンを投機的に予測し、MTPドラフターが導き出した複数のトークンを本番AIで並列検証して取り入れるという手法です。MTPドラフターはアイドル状態の計算リソースを活用して複数のトークンを予測できるほどに軽量であり、マルチトークン予測を用いることで最終的な出力の品質を損なわずに処理を高速化することができます。
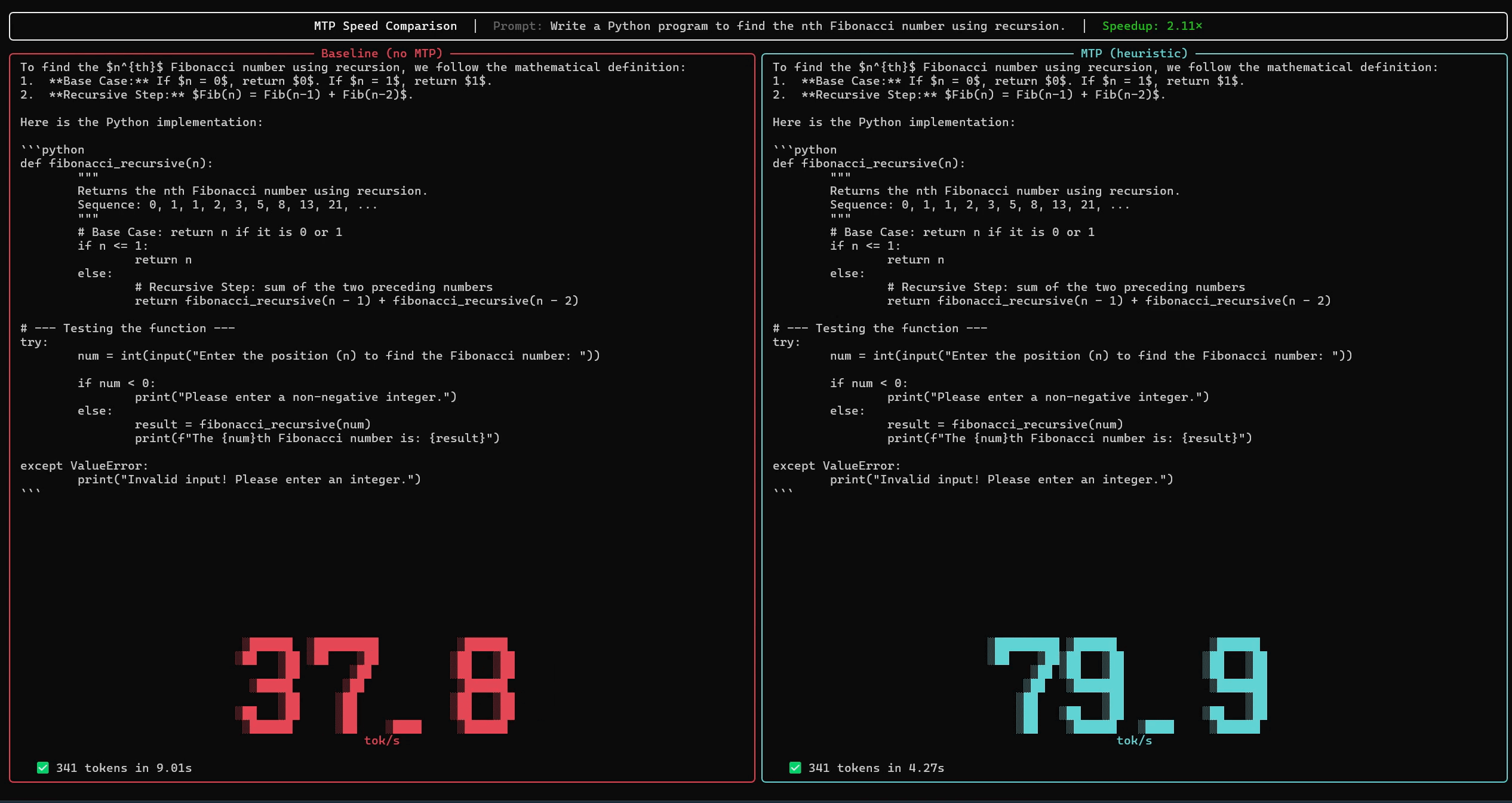
以下はNVIDIA RTX PRO 6000で「MTPドラフターなしのGemma 4 26B(左)」と「MTPドラフターありのGemma 4 26B(右)」の秒間出力トークン数を比べたものです。MTPドラフターを用いることで出力品質を保ったまま秒間処理トークン数を倍増させることができます。
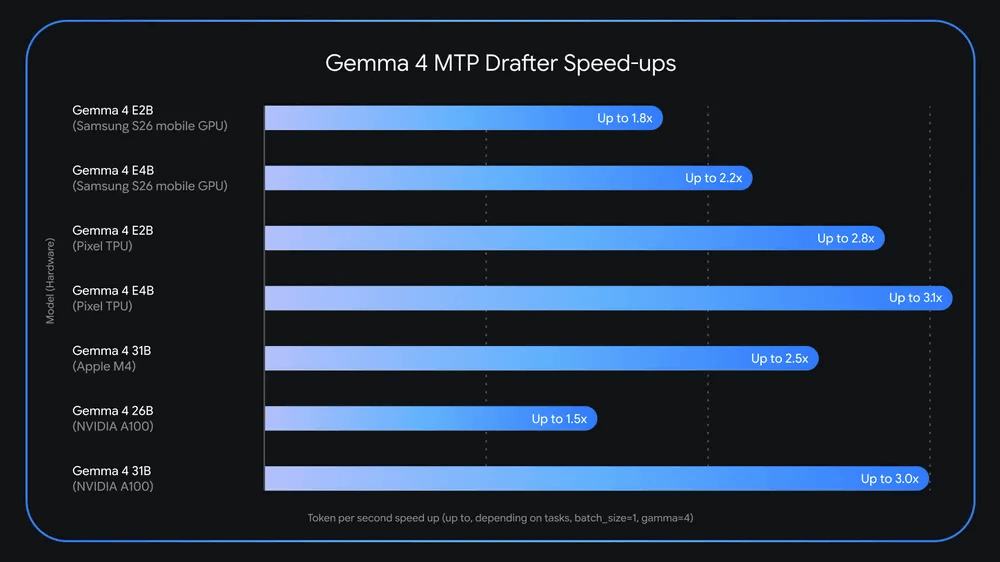
「Gemma 4 E2B」「Gemma 4 E4B」「Gemma 4 26B-A4B」「Gemma 4 31B」でMTPドラフターを用いた際の処理速度の変化を示した図が以下。Pixel TPUでGemma 4 E4Bを実行する場合、MTPドラフターを用いると処理速度が3.1倍に向上します。また、Gemma 4 31BをNVIDIA A100で実行する場合も3.0倍の速度向上が確認されています。つまり、マルチトークン予測はスマートフォンで動作する小型AIでも、データセンターで動作する大型AIでも有用な技術というわけです。
Googleは「Gemma 4 E2B」「Gemma 4 E4B」「Gemma 4 26B-A4B」「Gemma 4 31B」の4種のAIモデル向けに設計したMTPドラフターを以下のリンク先で公開しています。
google/gemma-4-E2B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-E2B-it-assistant
google/gemma-4-E4B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-E4B-it-assistant
google/gemma-4-26B-A4B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-26B-A4B-it-assistant
google/gemma-4-31B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-31B-it-assistant
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。