

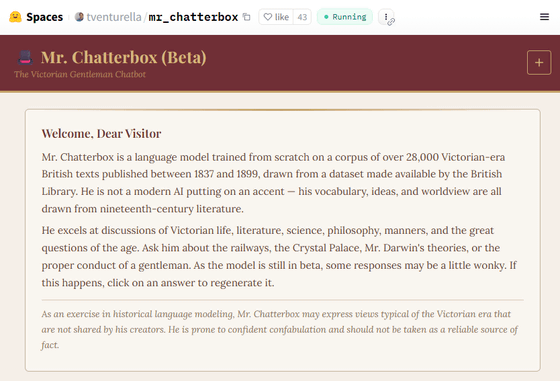
1837年から1899年にかけてのヴィクトリア朝時代のイギリスで出版・公開された2万8000点以上の書籍などの文章を用いてゼロから学習を行った言語モデル「Mr. Chatterbox」が登場されました。
Mr. Chatterbox – a Hugging Face Space by tventurella
https://huggingface.co/spaces/tventurella/mr_chatterbox
tventurella/mr_chatterbox_model · Hugging Face
https://huggingface.co/tventurella/mr_chatterbox_model
Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer
https://simonwillison.net/2026/Mar/30/mr-chatterbox/
Trip Venturella Releases Mr. Chatterbox Victorian LLM | Let’s Data Science
https://letsdatascience.com/news/trip-venturella-releases-mr-chatterbox-victorian-llm-64303621
大英図書館はMicrosoftと提携して、2500万ページ以上ある著作権の切れた書籍・文章をデータセットとして公開しています。セットに含まれる資料で最も古いものは1510年代のもの。多くは18世紀から19世紀にかけて出版されていて、地理や哲学、歴史、詩、文学など幅広い分野をカバーしています。
TheBritishLibrary/blbooks · Datasets at Hugging Face
https://huggingface.co/datasets/TheBritishLibrary/blbooks
AIプラットフォーム・Hugging Faceで活動しているトリップ・ベンチュレラ氏は、大英帝国の公開した書籍データセットから、ヴィクトリア朝時代に出版されたのみに絞り込んで、2万8035件の資料を抽出して言語モデルのトレーニングを行い、Mr. Chatterboxを生み出しました。
Mr. Chatterboxのパラメータ数は約3億4000万で、OpenAIのGPT-2-Mediumとほぼ同サイズだとのこと。
時期を限定したトレーニングを行ったことで、Mr. Chatterboxはヴィクトリア朝時代の生活・文学・科学・哲学・マナーなどに特化したAIとなっており、ベンチュレラ氏は「鉄道や水晶宮、ダーウィンの進化論、あるいは紳士としての振る舞いについて聞いてみてください」と述べています。
ベンチュレラ氏によると、Mr. Chatterboxはまだベータ版なので反応に不安定・不自然な部分があるため、うまく動作しない場合は回答を再生成して欲しいとのこと。
なお、Mr. Chatterboxは動作しても応答がかなり限られた内容であることから、パブリックドメイン資料のみで構築されたAIモデルが会話品質に達するにはさらに多くのデータが必要であることが示されているとの指摘があります。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。