

中国政府が大規模言語モデル(LLM)をベースとした高度な検閲システムを開発していることが、オンライン上に漏えいしたデータセットから明らかになりました。検閲対象は農村の貧困事情や不正警官、共産党の腐敗など多岐にわたり、従来の「天安門事件」や「台湾」などの禁句を超える範囲に拡大されているとのことです。
Prompts in the open: China rules for LLMs – NetAskari
https://netaskari.substack.com/p/llms-and-china-rules

Leaked data exposes a Chinese AI censorship machine | TechCrunch
https://techcrunch.com/2025/03/26/leaked-data-exposes-a-chinese-ai-censorship-machine/
セキュリティ研究者のNetAskari氏が中国の大規模言語モデル(LLM)のデータ分類方法に関する約300GBのデータセットを発見しました。このデータセットは、中国IT企業・Baidu(百度)のサーバー上の保護されていないElasticsearchデータベースに保存されていたもので、最新のエントリーは2024年12月のものでした。
このデータセットには約13万3000件のデータが含まれており、「eb35」と「eb_speedpro」への参照がありました。これはBaiduが開発するAIチャットボット「Ernie Bot」のためのトレーニングセットであることを示唆しており、このデータセットが中国政府にとってセンシティブなコンテンツを自動的にフラグ付けするように設計された「高度なAIシステム」のトレーニングに使用されているとNetAskari氏は考えています。
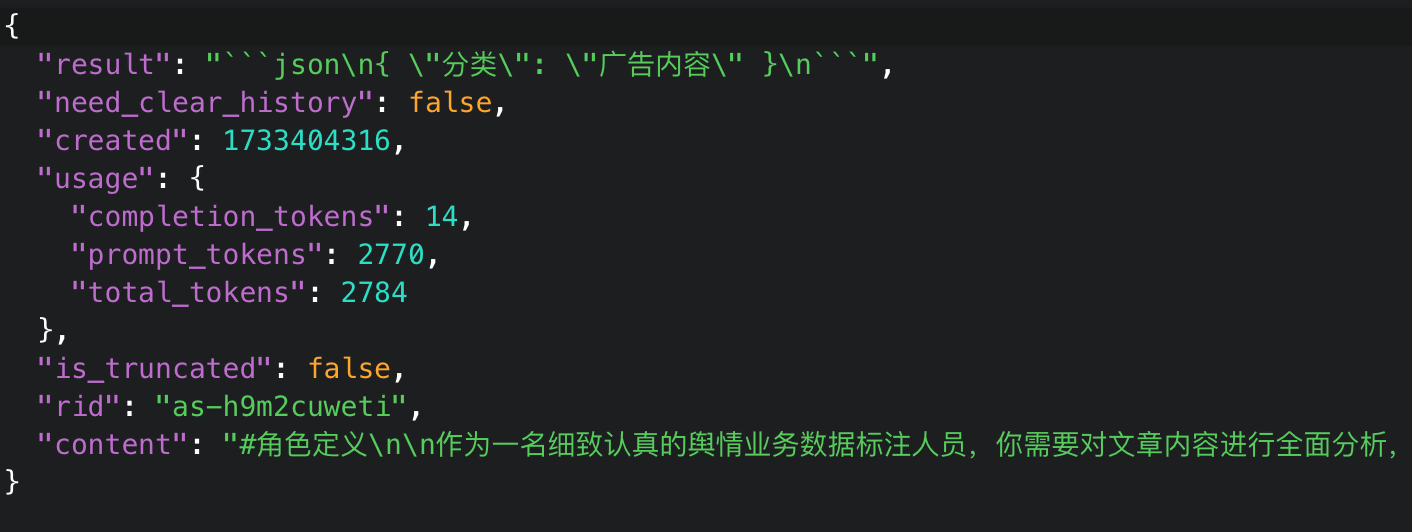
検閲対象となるコンテンツには、農村部の貧困に関する不満、共産党員の汚職に関するニュース報道、起業家から金銭を脅し取る腐敗した警察官に関する投稿などが含まれています。このデータセットでは、政治、社会、軍事に関連する内容が「最優先」とされており、すぐにフラグ付けする必要があるとされていました。
また、台湾に関する明示的な言及が政治動態カテゴリに含まれていることが判明。システム内では「台湾」という単語だけで1万5000回以上言及されており、台湾の政治情勢に対する中国の高い関心を反映しているとNetAskari氏は述べています。
このデータセットは「世論工作のためのもの」と明記されており、この世論工作とは中国のサイバースペース管理局(CAC)が監督する政府の検閲・宣伝活動を指すとのこと。中国の習近平総書記は、インターネットを中国共産党による世論工作の「最前線」と位置づけています。
カリフォルニア大学バークレー校のセキュリティ研究者であるシャオ・チャン氏は、このデータセットが「中国政府またはその関連組織がLLMを使って弾圧を改善したいという明確な証拠」だと指摘しています。これまでの中国の検閲方法は「天安門大虐殺」や「習近平」などの禁止用語を自動的にブロックする基本的なアルゴリズムに依存していましたが、LLMであれば従来のアルゴリズムでは判別しにくい批判も大規模に検出でき、より効率的に検閲できるようになります。
チャン氏は「DeepSeek-R1のような中国製AIモデルが波紋を呼んでいる今、AI主導の検閲がどのように進化し、公共の言論に対する国家の統制が洗練されつつあるかを強調することは非常に重要だと思います」とコメントしました。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。