

大規模言語モデルの性能は日々向上し続けていますが、複数の大規模言語モデルを一定の基準で評価するベンチマークツールの性能が大規模言語モデルそのものの性能に追いつかなくなってきているため、性能を正確に測定するツールの開発が急務となっています。そこで、AI企業Anthropicの研究者らが、ゲーム「Factorio」を使ったベンチマーク環境を構築し公開しました。
Factorio Learning Environment
https://jackhopkins.github.io/factorio-learning-environment/
近年、AIの性能向上の速度は目を見張るものがあり、新しく登場したモデルの記録がたった数カ月で塗り替えられてしまうことがよくあります。こうしたモデルの実力は性能を定量化するベンチマークツールで測られているのですが、ベンチマークツールの性能もAIモデルの性能に合わせて向上させ続けなければならず、これにコストと時間がかかってしまうことがAI開発における1つの課題になっています。
AIモデルが爆速で賢くなっているのでテスト方法が追いついていない – GIGAZINE

こうした問題の改善を図るべく、Anthropic所属のアクビル・カーン氏らがFactorioを使ったベンチマーク環境を構築しました。
Factorioはフィールドの資源を採掘してアイテムをクラフトし、設備の建築と動作の自動化を図るゲームで、「工場建築・自動化系ゲーム」の代表格とされるタイトルです。プレイヤーが可能な個々の操作はシンプルですが、建築物の配置やリソースの管理など、気にかけておかなければならない要素が多数存在します。
こうしたプロセスはゲームが進行するにつれて指数関数的に複雑になります。この動作をAIに実行させ、AIの性能を測るという目的で構築されたのが、「Factorio Learning Environment(FLE)」です。
FLEで性能を測定されるAIモデルは、Factorioをプレイし、工場を最適化するようプログラムされます。AIモデルは人間のプログラマーが学習するアプローチに倣ってゲームを学習し、トライアンドエラーを繰り返して成長し、ゲームの進行速度を向上させ続けることになり、動作処理のパフォーマンスに基づいて性能が評価されます。

実験のため、カーン氏らは2つの目標をAIに与えました。1つは「可能な限り大きな工場を建設する」というもので、AI自身が適切な目標を設定できるのか、短期的な生産と長期的な進行のバランスをどのようにとるのか、外部からの援助なしにどれほど工場を拡大できるのかを観測しました。
もう1つは「特定の課題をクリアさせる」というもの。カーン氏らは、「最低でも2台の設備で生産できるアイテムを作る」といったシンプルなタスクから、「100台近い設備の調整を必要とするゲーム終盤のアイテムを作る」といった複雑なタスクまで、合計24の異なるタスクを設定。各モデルに最初から一定のリソースを与えた上で、目的を達成するためのタイムリミットを設け、タスクの進行度を評価しました。
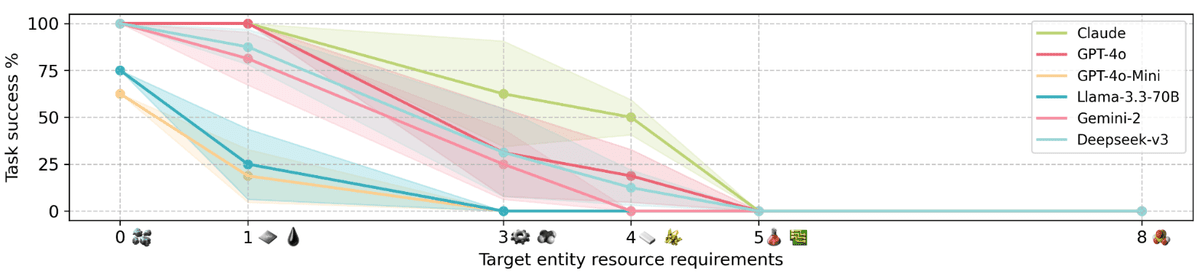
評価対象となったモデルはClaude 3.5-Sonnet、GPT-4o、GPT-4o-Mini、Deepseek-v3、Gemini-2-Flash、Llama-3.3-70B-Instructの6種類。特定の課題をクリアさせるという実験の結果を示したグラフは以下の通りで、横軸がタスク完了に必要な設備の数、縦軸が進行度を示しています。これを見ると必要な設備が増加するにつれて進行度がガクッと落ちているのが分かり、設備が5つを超えるとどのモデルもクリアすらままならなくなることがわかります。
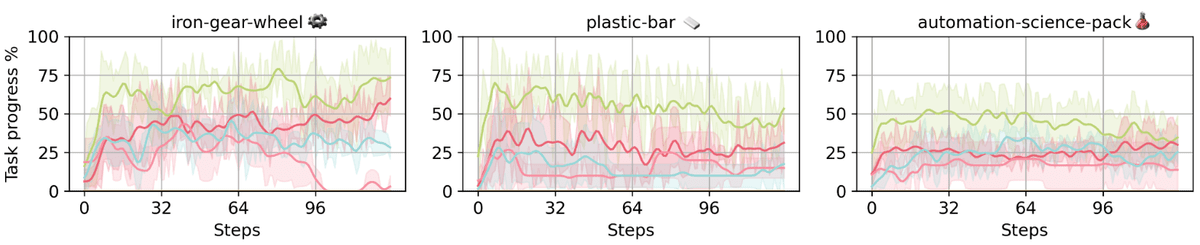
下のグラフは時間に伴う進行度です。カーン氏らは「AIは序盤に急速な進歩を遂げますが、その後に停滞または後退するパターンを示しています。生産規模を拡大したり、新しい区域を追加したりしようとすると、AIはしばしば既存の設備を壊してしまう様子が見られました。これは、複雑なタスクにおいて一貫したパフォーマンスを発揮することがとても難しいことを示唆しています」と述べています。
AIが最も苦手としたのは「プラスチック棒」というアイテムの生産でした。プラスチック棒は、まず電気を生産した上で、石炭を採掘し、油田から原油を掘り、原油を石油ガスに加工し、石炭と石油ガスを組み合わせることでようやく生産できるアイテムです。
以下はClaude Sonnet 3.5が構築したプラスチック棒の生産レイアウトで、このレイアウトで60秒間に40本のプラスチック棒を生産することができます。電気を届ける「電柱」が多過ぎるなどいろいろとツッコミどころはありますが、これが全モデルの中で最高スコアをたたき出したモデルの出来だったとのことです。

なお、全体的に最も高いスコアを出したのはClaude Sonnet 3.5でしたが、Claude Sonnet 3.5でさえ24個中7個のタスクしかクリアできませんでした。カーン氏らは「このベンチマークに改善の余地があることを示しています」と述べました。
「可能な限り大きな工場を建設する」という実験を経て観測された各モデルごとの特徴としては、より強力なコーディング能力を持つモデル(Claude 3.5-Sonnet、GPT-4o)は、より高い進行度を達成し、多くのタスクを完了したといった点が上げられるとのことです。特にClaude Sonnet 3.5だけが一貫して新技術の研究にリソースを投じ、戦略的な投資に価値を見いだしました。
Gemini-2-Flashは、手作業で100ステップかけて300個以上の「木箱」を作るような、視野の狭い動作をすることが多くありました。Gemini-2-FlashとDeepSeek-V3は、特定の課題をクリアする実験ではゲーム序盤で能力を発揮するものの、自由に工場を建設する実験ではまとまった工場をあまり作ろうとせず、全体的なパフォーマンスは低下したとのことです。
また、どのモデルも空間の把握を苦手としました。Factorioでは設備と設備の間に搬送・配電用の空間を設けることが一般的ですが、AIは設備同士を近づけすぎてしまったり、資源を運ぶアイテムを正しく配置しなかったりすることがよくありました。

また、AIが無効な操作を繰り返し試みることも確認されています。本来であれば代替案を探るべきところ、一度エラーを起こした操作をやり直してしまい、例を挙げるとGPT-4oは78ステップ連続で無効な操作を実行したとのことです。
カーン氏らは「我々の結果は、最先端の大規模言語モデルでさえ、自動化タスクの調整と最適化に苦戦していることを示しています。Factorioにある『テクノロジー』という要素はゲーム進行につれて急速に複雑さを増すため、AI研究が今まで以上に進歩してもなお困難だと考えられます。これにより、モデルの差別化が可能になります」と述べました。
なお、FLE関連のデータはGitHubで公開されています。
GitHub – JackHopkins/factorio-learning-environment: A non-saturating, open-ended environment for evaluating LLMs in Factorio
https://github.com/JackHopkins/factorio-learning-environment
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。