

「Irodori-TTS」はPC上でローカル実行できる音声合成AIで、声色を指定してセリフ音声を自由に生成することができます。GPUを搭載していないPCでも生成可能で、クラウドAIと違って生成内容や生成回数に制限がないのも特徴です。そんなIrodori-TTSのAIモデルのV3が2026年5月に登場し、「音声品質向上」「出力音声の秒数指定に対応」「ウェブUIに絵文字パレット追加」といったアップデートが施されたので実際に使ってみました。
Irodori-TTS – a Aratako Collection
https://huggingface.co/collections/Aratako/irodori-tts
GitHub – Aratako/Irodori-TTS: A Flow Matching-based Text-to-Speech Model with Emoji-driven Style Control · GitHub
https://github.com/Aratako/Irodori-TTS
・目次
◆1:Irodori-TTSのインストール
◆2:セリフ音声を生成する手順
◆3:参考音声で声色を指定
◆4:長さを指定して生成
◆5:絵文字で感情表現
◆6:説明文で声色を指定
◆1:Irodori-TTSのインストール
Irodori-TTSをPCで使うには、あらかじめプログラミング言語の「Python」、Python用パッケージ管理ツールの「uv」、バージョン管理システムの「Git」をインストールしておく必要があります。Pythonは公式サイトからダウンロードしてインストール可能で、GitとuvはWindows標準コマンドの「winget」を用いてインストール可能。Gitとuvのインストール手順は以下のIrodori-TTS-V2のレビュー記事で詳しく解説しています。
好きな声で好きなセリフを喋らせられるローカルAI「Irodori-TTS」の使い方、日本語特化でローカル動作するので無制限に生成し放題 – GIGAZINE
「Python」「Git」「uv」のインストールが完了したらIrodori-TTSのインストールを進めます。Irodori-TTSのインストールコマンドは以前と少し変化しているので改めて解説します。
まず、任意の場所にIrodori-TTSのインストール先となるフォルダを作成します。今回はCドライブ直下に「ai」という名前のフォルダを作成しました。
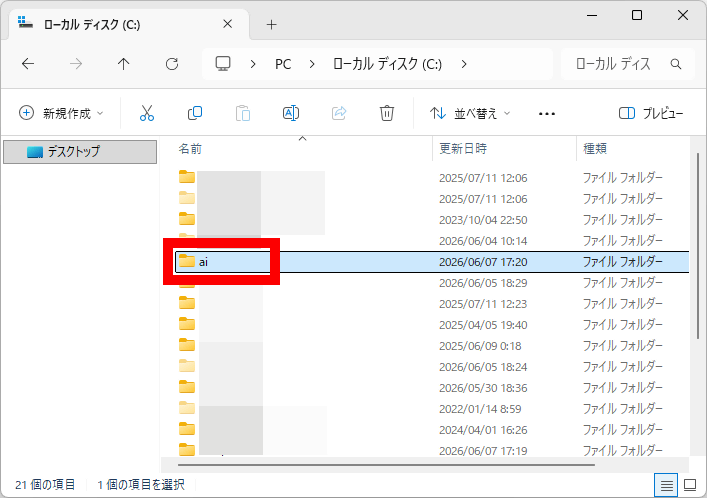
作成したフォルダを開いて右クリックメニュー内の「ターミナルで開く」をクリック。
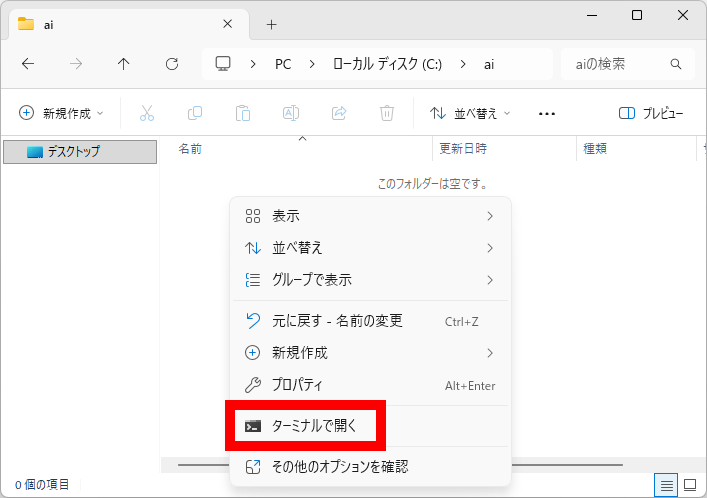
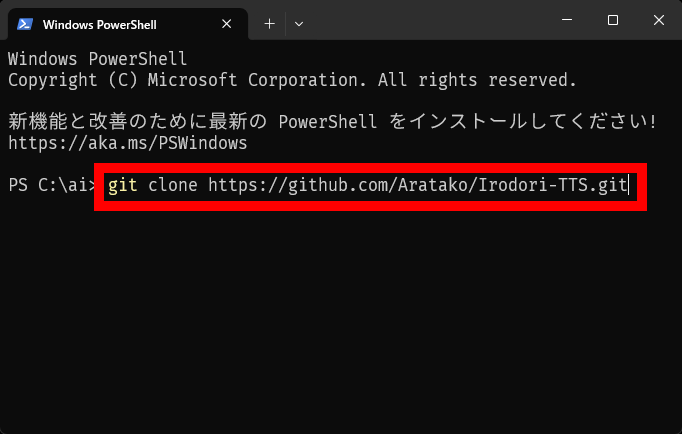
ターミナルが起動したらIrodori-TTSのインストールに必要なファイルをダウンロードするために「git clone https://github.com/Aratako/Irodori-TTS.git」というコマンドを入力してEnterキーを押します。
ダウンロードが完了したら「cd Irodori-TTS」を実行してIrodori-TTSのフォルダに移動。
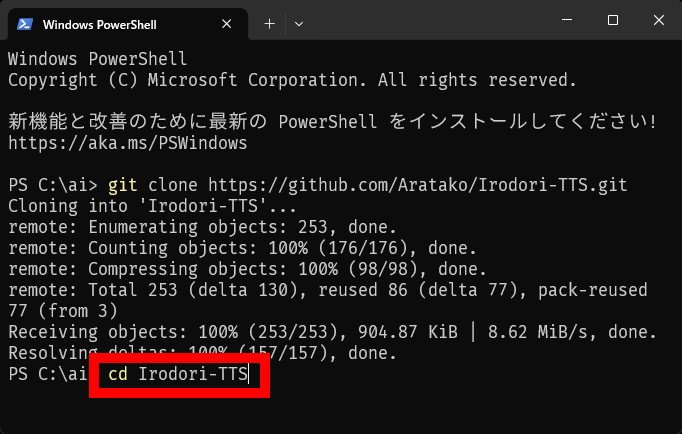
次に、環境に合わせたインストールコマンドを実行します。環境とコマンドの組み合わせは以下の通り。
WindowsもしくはLinuxでNVIDIA製GPUを使う場合:uv sync –extra cu128
LinuxもしくはWSLでAMD製GPUを使う場合:uv sync –extra rocm
WindowsもしくはLinuxでIntel XPUを使う場合:uv sync –extra xpu
CPUのみの環境やmacOSで実行する場合:uv sync –extra cpu
今回はNVIDIA製GPUを搭載したWindows PCで実行するので「uv sync –extra cu128」を実行しました。
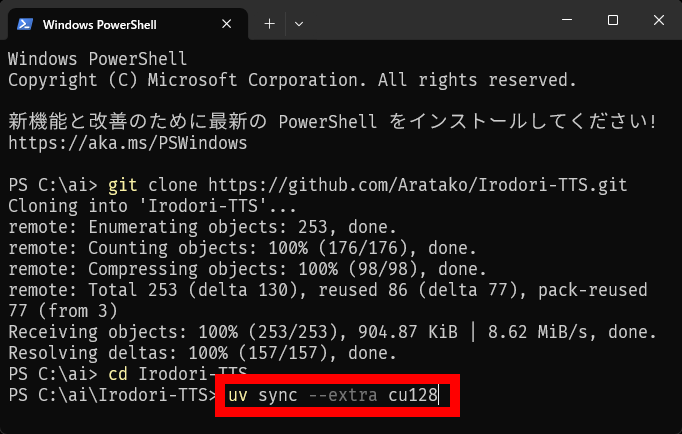
しばらく待って最下部に「C:\ai\Irodori-TTS」と表示されたらインストール完了です。
◆2:セリフ音声を生成する手順
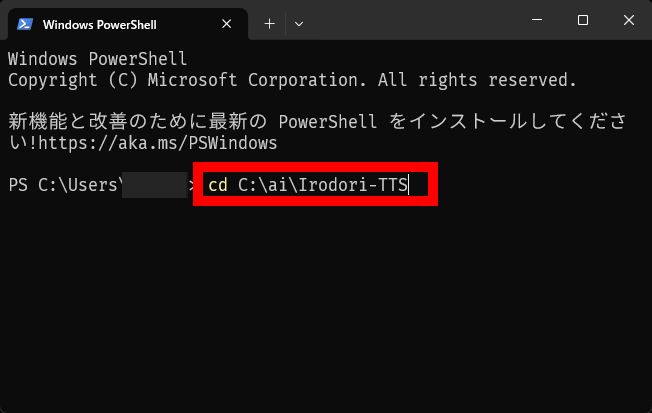
Irodori-TTSはコマンドラインで実行できるほか、ブラウザ上でウェブUIを開いてマウス操作で実行することもできます。ウェブUIを開く手順は次の通り。最初にターミナルを起動して「cd C:\ai\Irodori-TTS」を実行してIrodori-TTSのフォルダに移動します。
続いて「uv run –no-sync python gradio_app.py –server-name 0.0.0.0 –server-port 7860」を実行してIrodori-TTSのサーバーを起動します。V3の登場に合わせて実行環境にもアップデートが施されており、環境を固定するために「–no-sync」というオプションが必要になりました。
しばらく待って「Running on local URL ○○○」と表示されたら準備完了。
ブラウザを起動してアドレスバーに「localhost:7860」と入力。
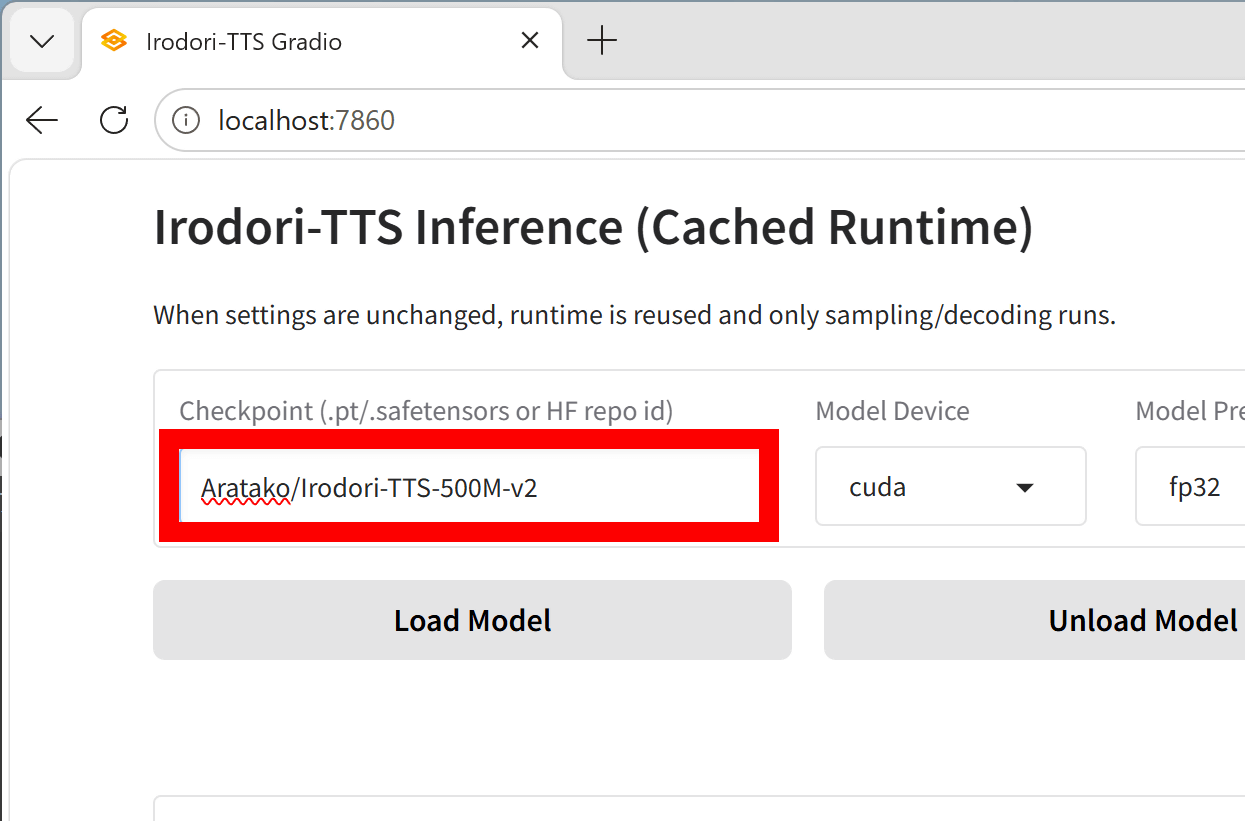
これがIrodori-TTSのウェブUIです。「Load Model」をクリックすると「Irodori-TTS-500M-v3」をダウンロードして読み込めます。
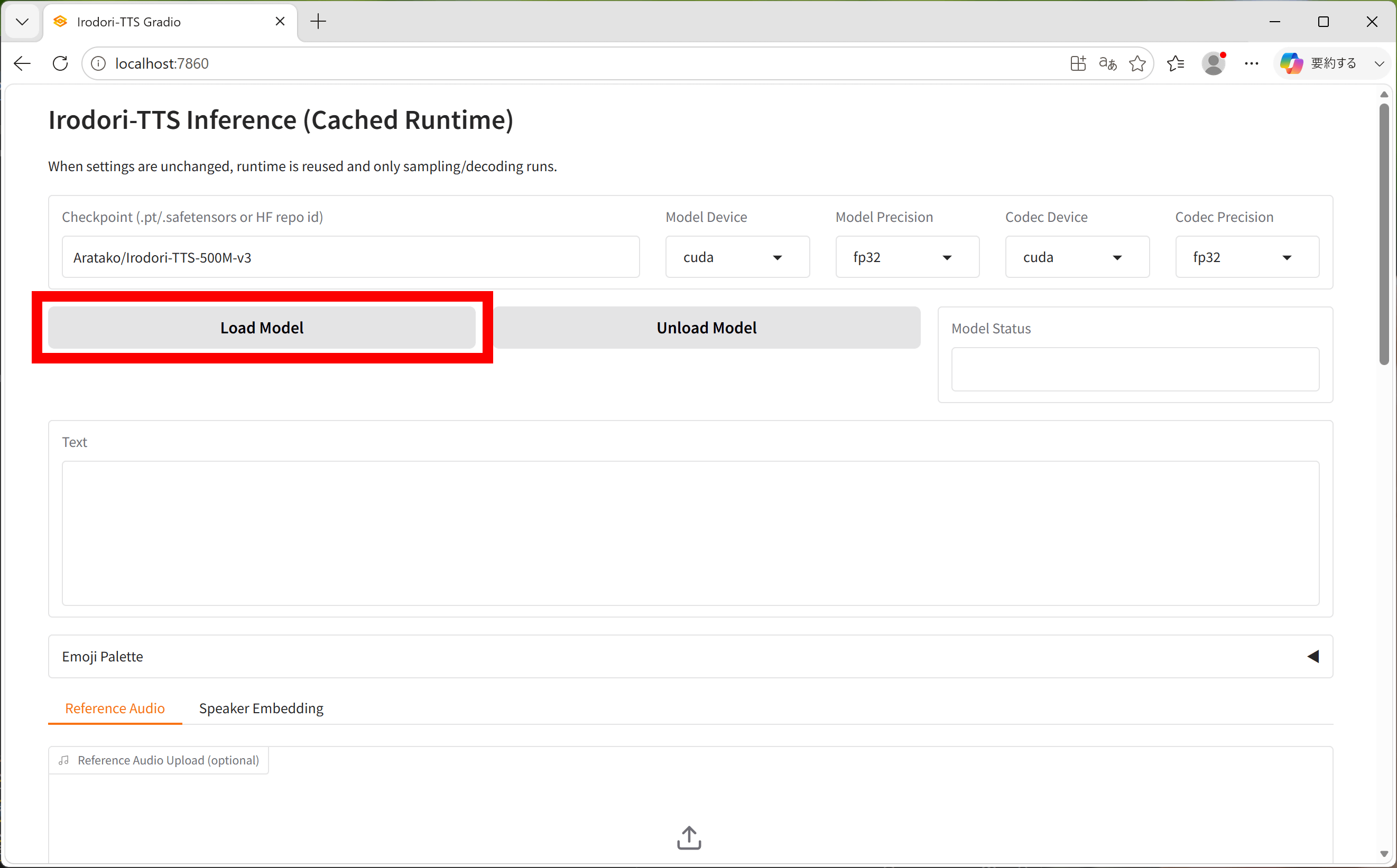
モデルの読み込みが完了したら「Text」の欄にセリフを入力。
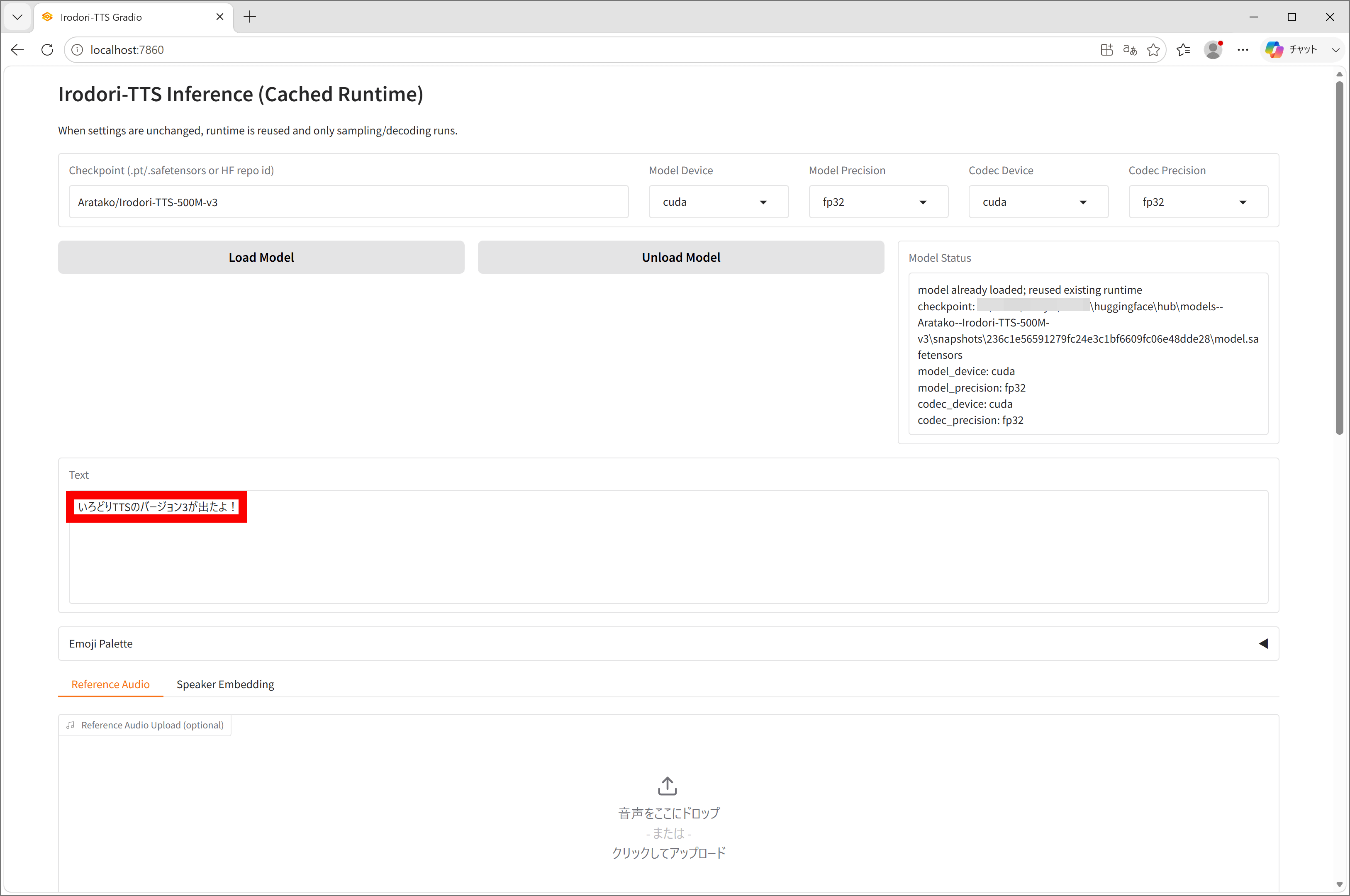
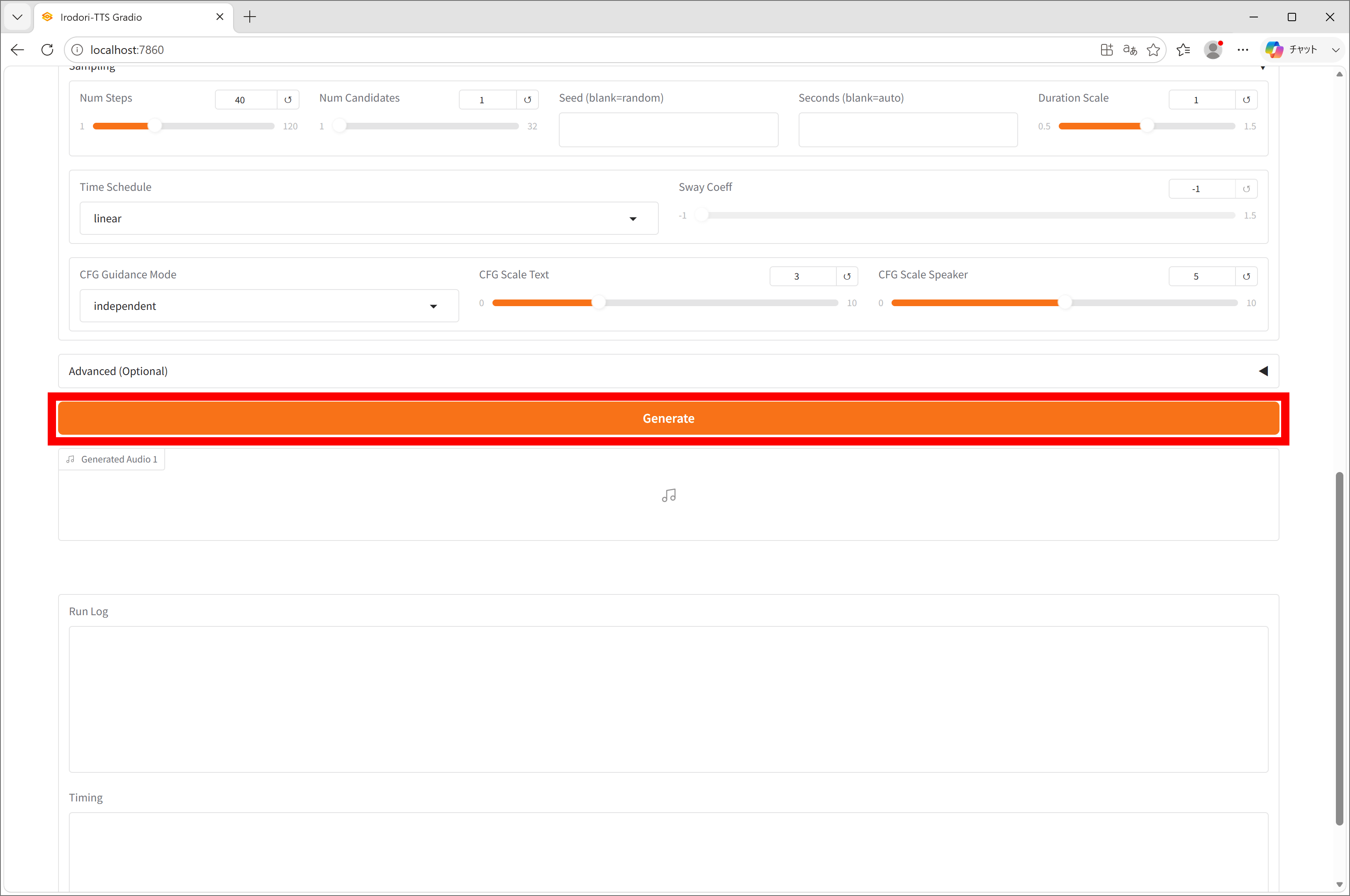
下方向にスクロールして「Generate」をクリックすると生成処理が始まります。
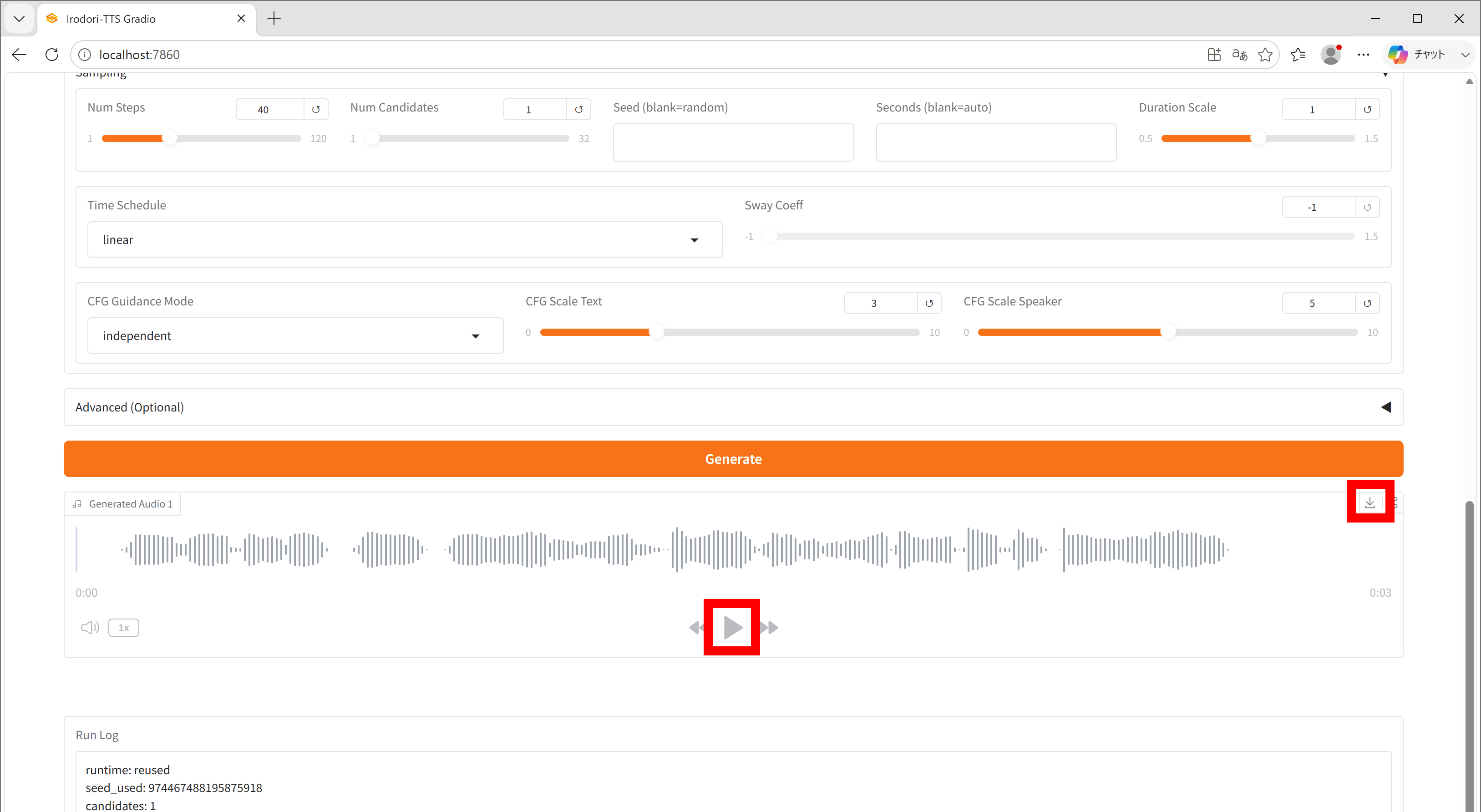
生成が完了したら再生ボタンで再生可能。ダウンロードボタンをクリックすると保存できます。
実際にセリフ音声を生成する様子を動画で記録してみました。GeForce RTX 5070Tiを搭載したWindows PCだと数秒で音声を生成できます。
ローカル音声合成AI「Irodori-TTS-v3」でセリフ音声を生成 – YouTube
なお、生成した動画はダウンロードボタンをクリックせずとも「C:\ai\Irodori-TTS\gradio_outputs\」にすべて保存されています。
Irodori-TTS-v3は音声品質が向上した一方で、フォーマルな音声に寄っている印象なので、アニメっぽい声で生成したい場合はIrodori-TTS-v2に切り替えるのもありです。Irodori-TTS-v2で生成したい場合は左上の「Checkpoint」の欄を「Aratako/Irodori-TTS-500M-v2」に書き換えればOKです。
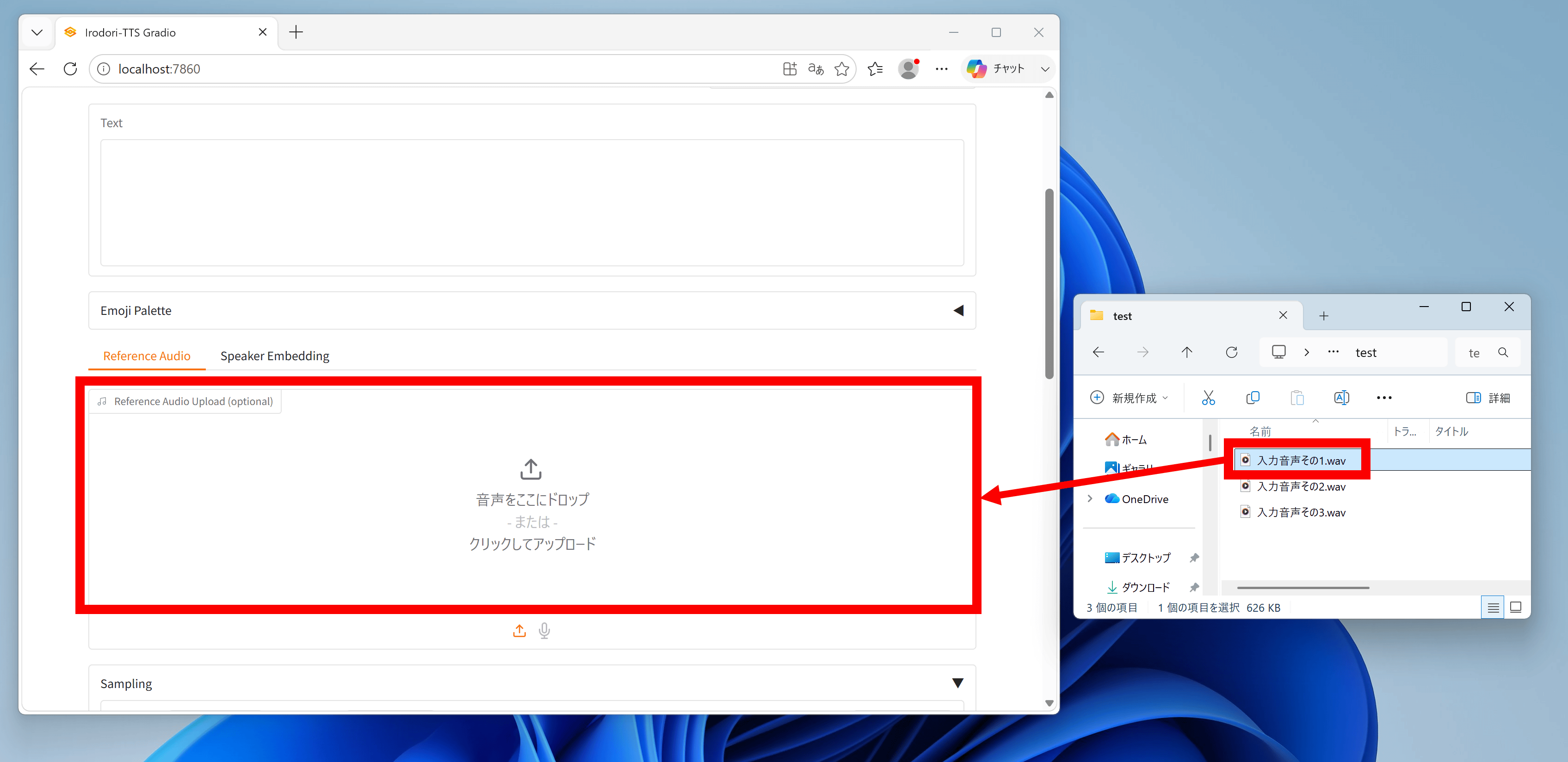
◆3:参考音声で声色を指定
「Reference Audio Upload」の欄に参考音声ファイルをドラッグ&ドロップすると参考音声と同じ声色で音声を生成できます。
参考音声を用いた生成の例が以下。元の音声の声色をかなり再現できています。
ローカル音声合成AI「Irodori-TTS-v3」で声色を指定してセリフ音声を生成 – YouTube
◆4:長さを指定して生成
「Seconds」の欄に秒数を入力することで、生成音声の長さを指定することもできます。
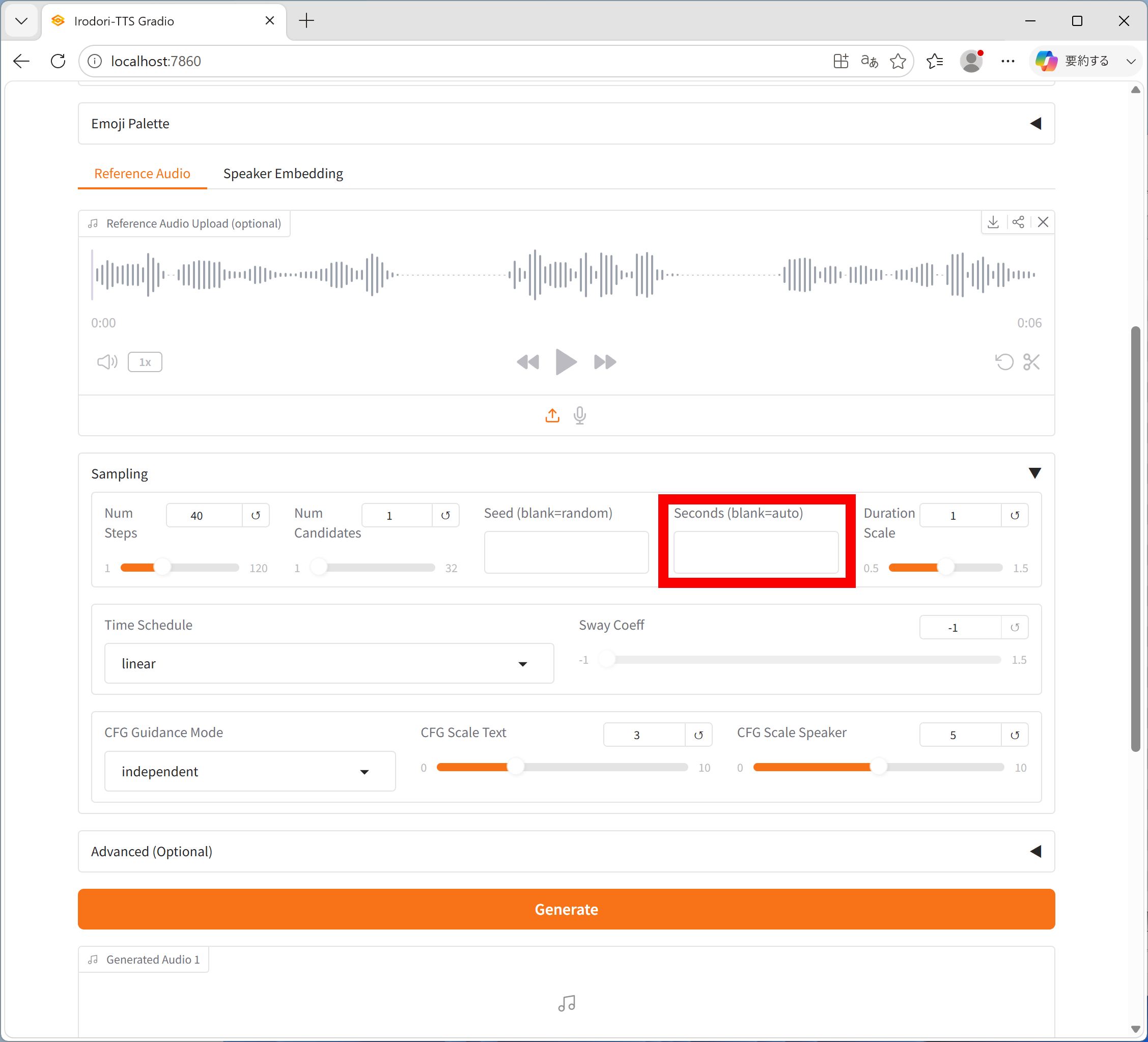
長さ指定の例が以下。短い秒数だと早口になり、長い秒数だとゆっくり話すようになりました。短すぎたり長すぎたりすると音声が破綻することもあります。
ローカル音声合成AI「Irodori-TTS-v3」で長さを指定してセリフ音声を生成 – YouTube
◆5:絵文字で感情表現
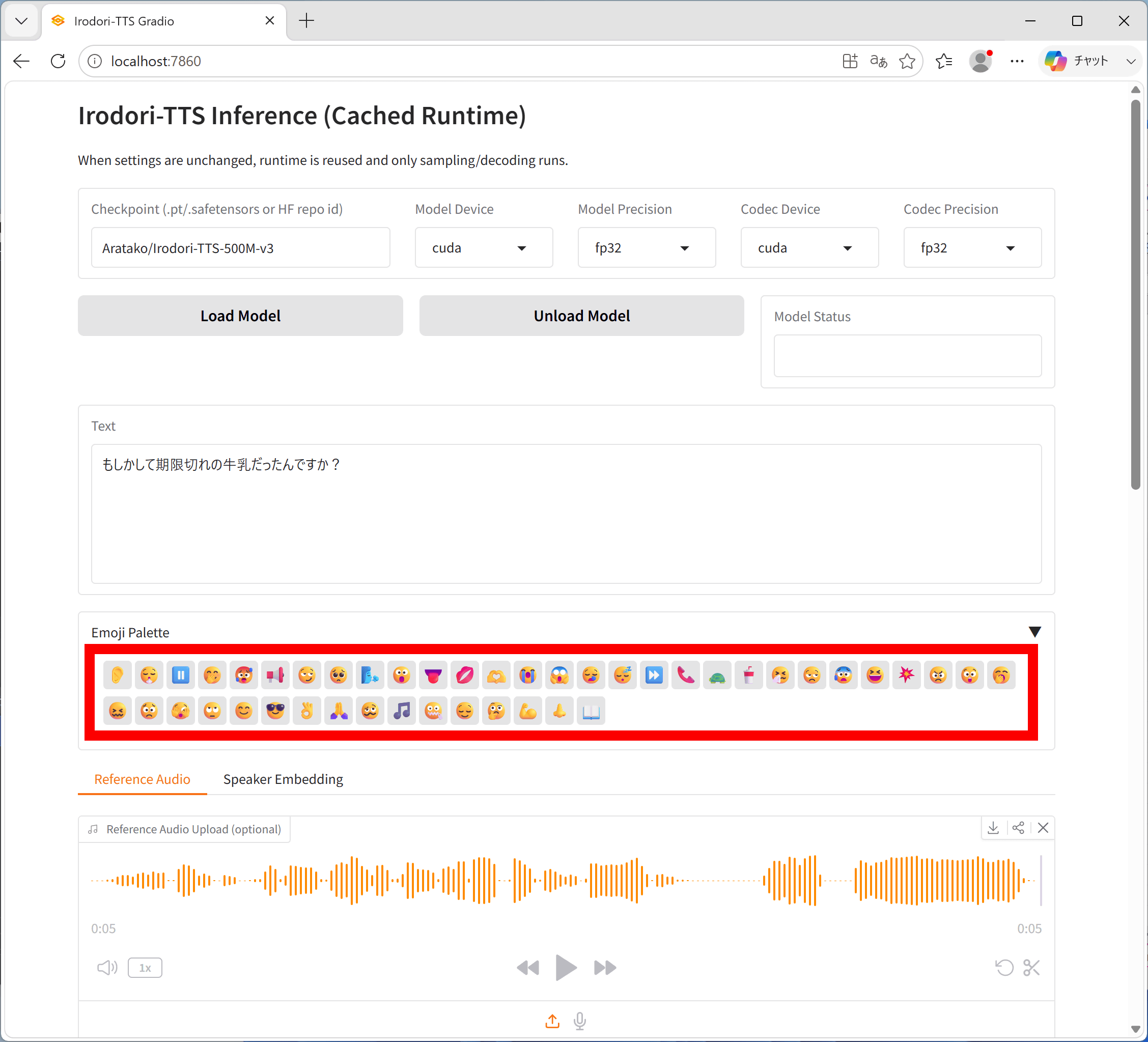
Irodori-TTSはセリフに絵文字を混ぜることで感情を指定することもできます。2026年5月のアップデートでウェブUIに絵文字パレットが追加されて入力が簡単になりました。絵文字パレットはセリフ入力欄の下部にある「Emoji Palette」をクリックすると開きます。
これが絵文字パレットです。「😏」でからかうような声にしたり、「😪」で眠そうな声にしたりと色んな絵文字に対応しています。
絵文字で感情を制御する例が以下。「驚き」「怒り」「電話越し」「喘ぎ」「鼻歌」「舌打ち」など数多くの絵文字に対応しているので絵文字リストを参考にいろいろ試してください。
ローカル音声合成AI「Irodori-TTS-v3」で感情を指定しながらセリフ音声を生成 – YouTube
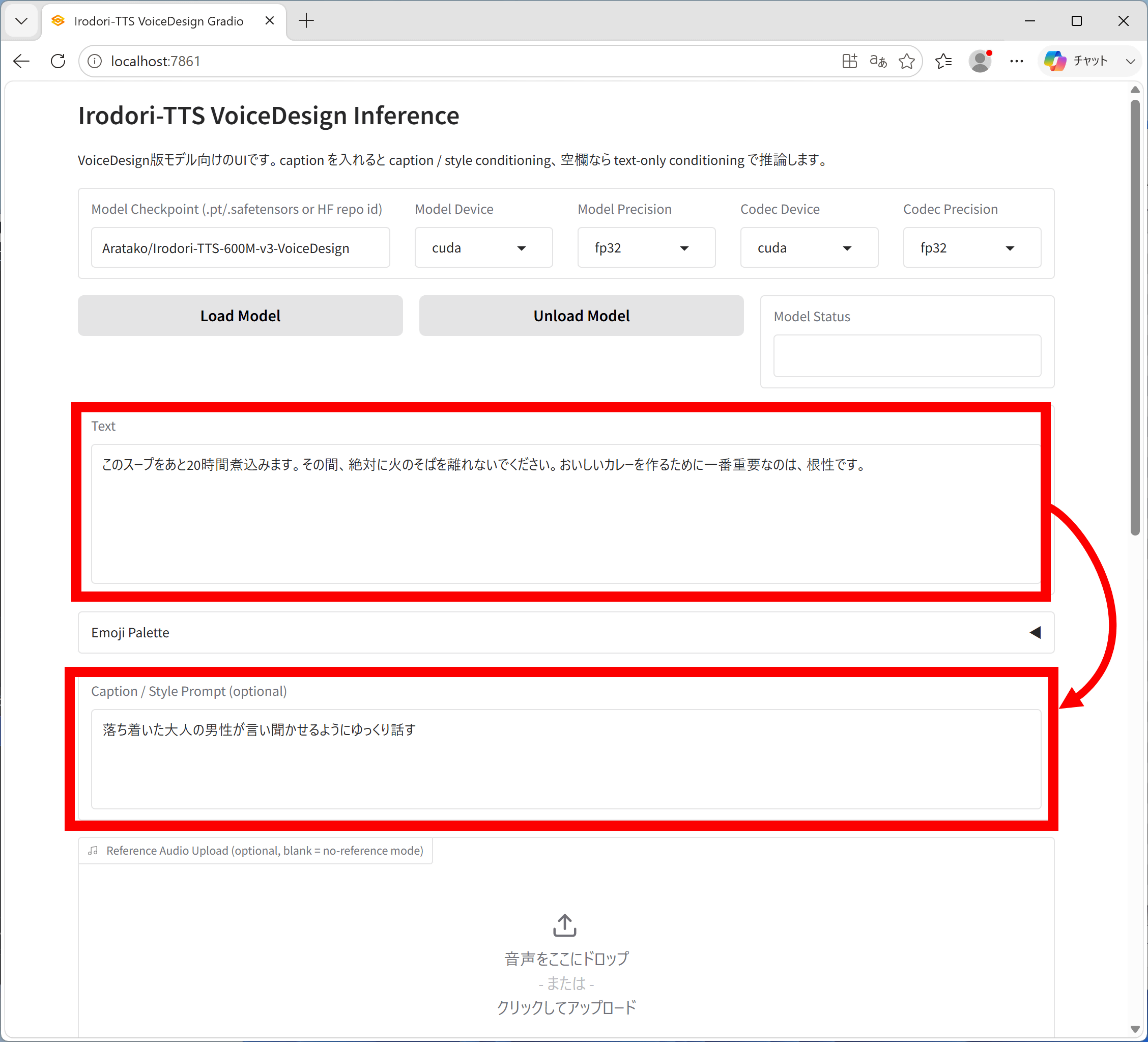
◆6:説明文で声色を指定
「Irodori-TTS-600M-v3-VoiceDesign」を使えば、声色を説明文で指定することができます。VoiceDesign版をウェブUIで実行するには以下のコマンドを1行ずつ実行すればOK。
cd C:\ai\Irodori-TTS
uv run --no-sync python gradio_app_voicedesign.py --server-name 0.0.0.0 --server-port 7861
「Text」にセリフ、「Caption」に声色の説明文を入力して生成します。
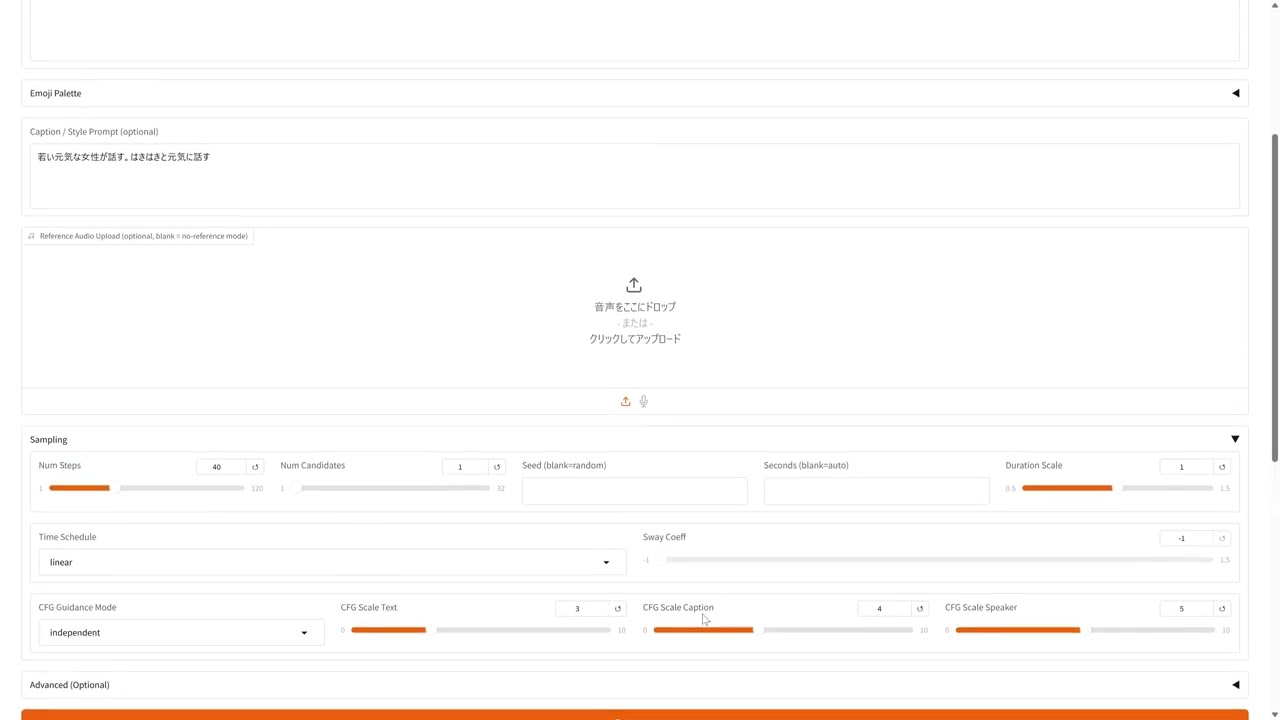
Irodori-TTS-600M-v3-VoiceDesignでの生成例が以下。参考音声を用意できない場合も説明文を用いてある程度の制御が可能です。
ローカル音声合成AI「Irodori-TTS-v3–VoiceDesign」で声色を指定しながらセリフ音声を生成 – YouTube
Irodori-TTSのソースコードやLoRA作成に役立つ情報は以下のリンク先にまとまっています。
GitHub – Aratako/Irodori-TTS: A Flow Matching-based Text-to-Speech Model with Emoji-driven Style Control · GitHub
https://github.com/Aratako/Irodori-TTS
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。