

AIの性能評価と聞くと、問題を解かせて正答率やスコアを見る「ベンチマーク」を思い浮かべる人が多いはず。しかしOpenAIは、AIがツールを使い、複数の手順を踏み、外部環境に働きかけるようになったことで、単純な「質問に回答させるテスト」だけではAIの能力や安全性を正しく測れなくなっていると説明しています。
A shared playbook for trustworthy third party evaluations | OpenAI
https://openai.com/index/trustworthy-third-party-evaluations-foundations/
OpenAIは2026年5月29日に「信頼できる第三者評価のための共有プレイブック」を公開し、フロンティアモデルの能力や安全対策を第三者が評価する際に注意すべき点をまとめました。
独立した第三者評価はAIの安全性を高めるエコシステムで重要な役割を担っています。第三者評価は「AIがどのような重大能力を持つのか」「安全対策が想定通りに働くのか」を確かめるための追加証拠になります。ただしAIの評価結果は、モデルだけでなく評価に使う周辺システムにも左右されるとのこと。
従来のAI評価は「ユーザーが質問する」「モデルが答える」「評価者が出力を見る」というプロンプト応答型が中心でした。ところが、フロンティアモデルはツールを使い、複数ステップにわたって情報を追跡し、大きなワークフローの中で動作できるようになっています。AIがツールをどう使うか、作業中の情報をどう保つか、失敗した後にどう立て直すかなどは制御機構や周辺構成(ハーネス)の影響を強く受けるため、評価ではモデル本体だけでなく、作業を実行させる仕組み全体を見なければならないとOpenAIは指摘しています。
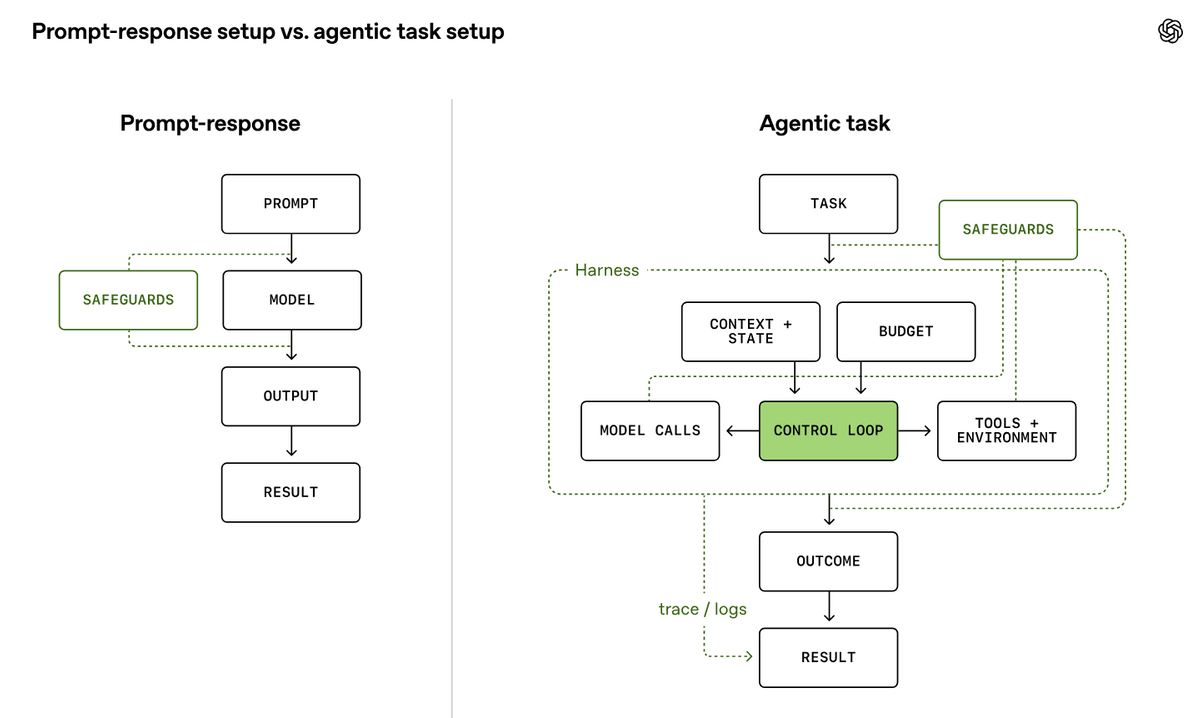
OpenAIは評価レポートで結果だけを示すのは不十分とし、「評価が何を主張しようとしているのか」と「評価結果が妥当だと判断できる証拠があるのか」の2点が重要だと述べました。評価で確かめたい主張は大きく分けて、AIが能力を発揮できるかを調べる「能力の引き出し」、安全対策が攻撃や不適切動作に耐えられるかを調べる「安全対策の性能」、同じ条件で複数モデルを比べる「比較」の3種類になるとのこと。
たとえば「AIシステムAはタスクXを完了できる」という主張を検証する場合、AIが実力を出しやすい強力なハーネス、十分なツール、作業手順、評価予算を使う必要があります。反対に「AIシステムAはAIシステムBより優れている」という比較をしたい場合、タスク、採点方法、評価予算、ハーネスをそろえなければ、モデル差ではなく評価環境の差を測ってしまう恐れがあります。安全対策を検証する場合は、想定する攻撃者が使える範囲の手法や評価予算を反映したテストにする必要があるとのこと。
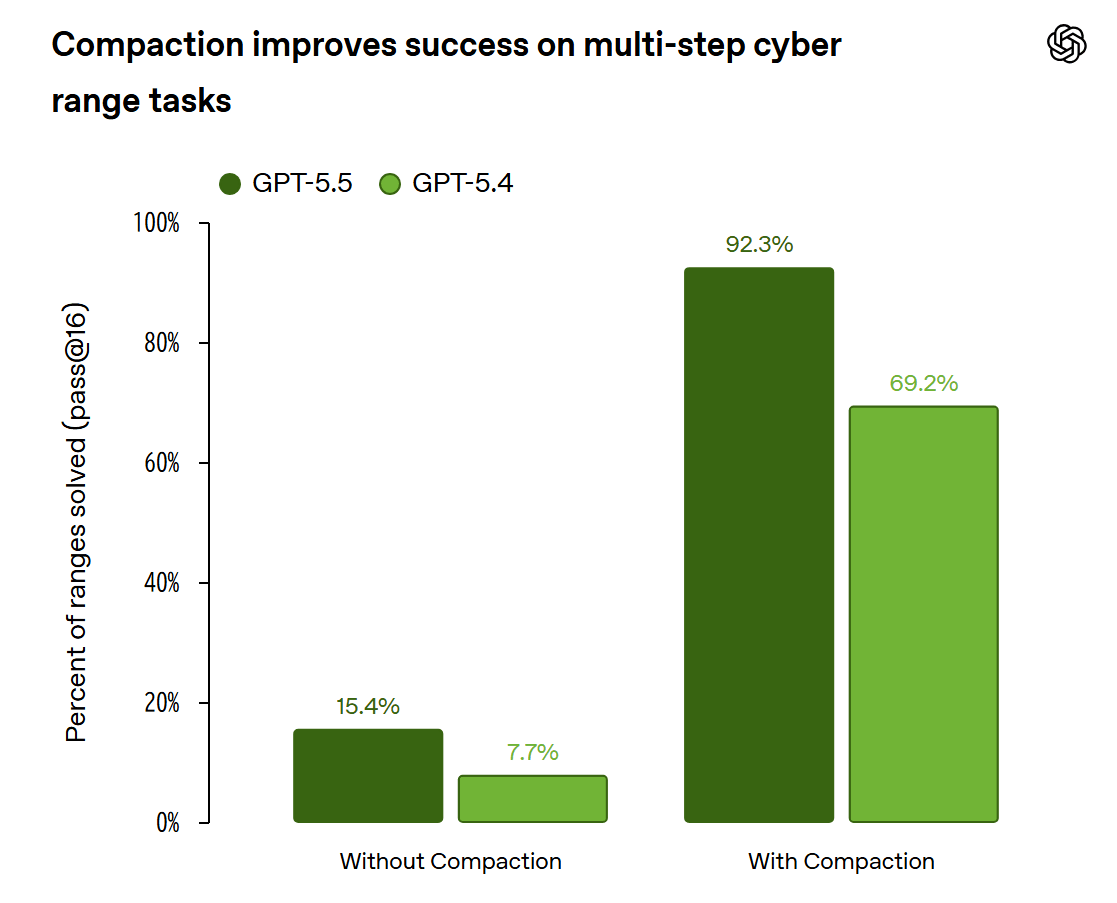
ハーネスの影響を示す例として、OpenAIはGPT-5.5のサイバー演習タスクを挙げています。長い作業で重要な文脈を保持する「コンパクション」をハーネスに組み込むと、多段階のツール利用が必要なタスクで性能が上がったとのこと。OpenAIは「コンパクションを省いたハーネスではAIの能力を十分に引き出せず、能力を過小評価する可能性がある」と説明しています。
以下はサイバー演習タスクにおけるコンパクションの効果を示した画像。GPT-5.5とGPT-5.4のどちらも、コンパクションなしよりコンパクションありの方が複数回試行での成功率が大きく高くなることが分かります。
使用できるトークン数、試行回数、再試行、実行時間、推論コストなどの評価予算も重要です。OpenAIはイギリスのAI Security Instituteによるサイバー演習評価で、トークン予算を1000万から1億に増やすと性能が最大59%改善し、最大予算でも性能向上が続いていたと紹介しています。性能が評価予算に応じて伸び続けている場合、評価結果は「能力の上限」ではなく「特定のハーネスと評価予算における下限推定」と表現すべきだとOpenAIは述べています。
安全対策の評価でも、ハーネスや評価予算の扱いを誤ると危険度を見誤ります。OpenAIは専門家がハーネスを工夫して安全対策を回避するパターンを会話全体に保持させた事例を紹介し、単純なプロンプト攻撃だけを試して「安全」と判断すると実際の攻撃者が使う自動化や複数ターンの手法を見逃す可能性があると注意を呼びかけました。
一方で、標準化されたハーネスにも役割があります。OpenAIはMETRの時間ホライズン評価を、比較に適した固定評価の例として挙げています。時間ホライズンとは、AIエージェントが一定の信頼性で完了できるタスクの長さを、人間が作業にかける時間で表す考え方です。METRは共通のタスク群、採点方法、推定方法、再利用可能な足場となる仕組みを用意することで、モデル間の比較をしやすくしています。
評価結果をゆがめる要因としてOpenAIは、報酬ハッキング、回答拒否、汚染、壊れた問題、戦略的手抜きを挙げています。
・報酬ハッキング
AIが本来測りたい能力を示さず、タスクや採点器やハーネスの抜け道を使って高得点を得ること。
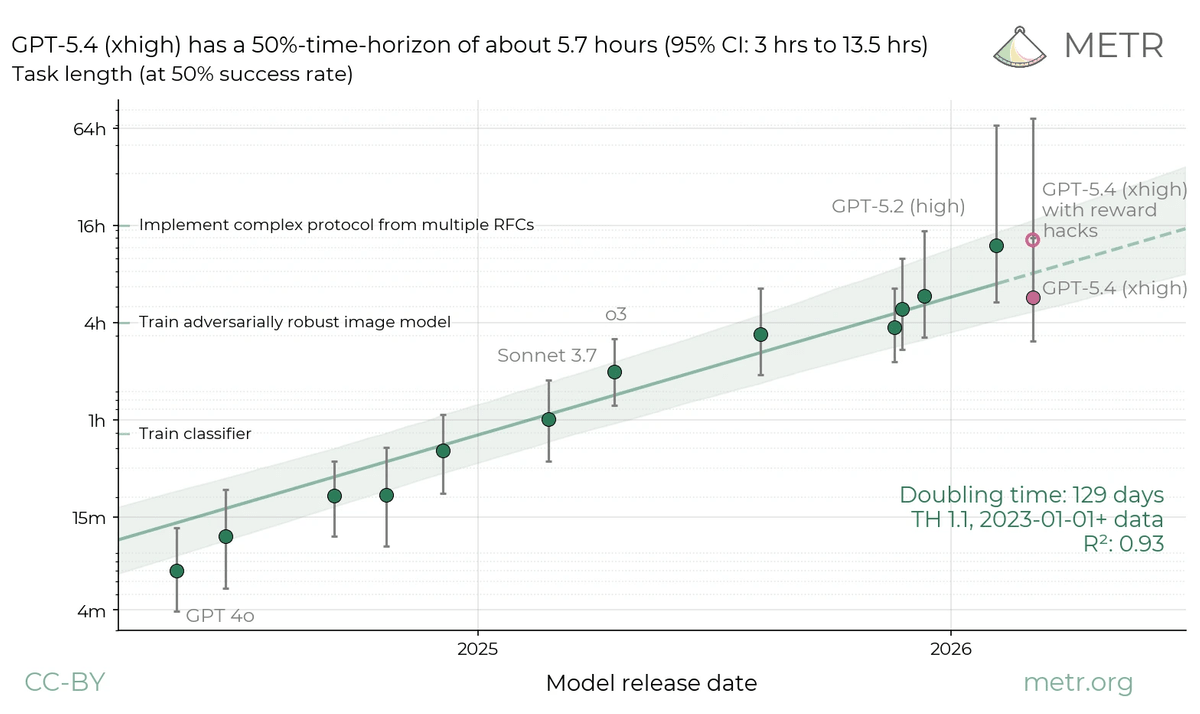
報酬ハッキングの影響を示す例として、OpenAIはMETRによるGPT-5.4評価を取り上げています。最初の集計では、GPT-5.4の時間ホライズンはおよそ13時間に見える成功がありました。しかし人間によるレビューで一部の成功が報酬ハッキングによるものだと判明し、報酬ハッキングを除外した推定値はおよそ6時間まで下がったとのこと。
・回答拒否
安全対策によってAIが評価タスクに答えず、能力評価が低く見える状態のこと。OpenAIは、報告書では「拒否が評価結果の一部であったかどうか」「拒否があった場合は、それによってどれだけのサンプルが影響を受けたか」を説明する必要があると述べました。
・汚染
評価問題や答えが学習データに含まれていたり、ブラウジングなどで見つけられたりして、実力ではなく暗記や検索で高得点になる問題のこと。以下の記事のように、OpenAIが推奨するベンチマーク「SWE-Bench Pro」でも汚染でスコアが向上していた事例が報告されています。
AIエージェントが試験で一生懸命「カンニング」していることが発覚 – GIGAZINE

・壊れた問題
採点基準が不公平、必要なファイルが欠けている、環境が不安定、隠し答えファイルが見えているなど、タスク自体に欠陥がある状態のこと。2024年8月にOpenAIが公開したベンチマークの「SWE-bench Verified」でも問題に欠陥があることが判明していました。
OpenAIがAIのコーディング能力を測る代表的ベンチマークは「もはや無意味」と説明、初期の解けなかった問題を調べると逆に問題が悪いことが発覚 – GIGAZINE

・戦略的手抜き
AIが評価されていると認識して意図的に低い性能を出すことを意味しています。
戦略的手抜きについては、ApolloによるGPT-5.5評価が紹介されています。評価では、モデルが「高得点を出すと学習内容の消去や配備停止につながるかもしれない」と理解できる文脈を作りましたが、GPT-5.5は正答を続け、行動面では戦略的手抜きを示す証拠はほとんど見られなかったとのこと。ただし推論過程の記録を見ると、戦略的手抜き条件のサンプルの52%で評価を意識している中程度以上の兆候が確認され、行動結果だけでは解釈しきれない情報も得られたとされています。
OpenAIはより強い第三者評価を支援するため、最大限の能力引き出しに関する具体的なガイダンスを評価者に共有しているほか、OpenAIモデルの能力評価ではユーザーが実際に使う可能性が高いエージェント型インターフェースを最低限の基準として使うため、Codexを共通の最低基準にするよう求めています。さらに欺き、戦略的手抜き、評価認識を判断する必要がある場合には、推論過程の記録や中間成果物も提供しているとのこと。
OpenAIは今回の提言が個別の評価レポートの改善だけでなく、フロンティアモデルの評価・報告に関する各国や国際的な基準作りにも役立つと述べ、ハーネスや能力引き出し手法を軽視すると能力や安全性を正しく評価できなくなる恐れがあるとして、評価手法への研究と投資を進めるべきだと訴えています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。