
AIモデルの性能比較では、複数のベンチマークの点数が並ぶランキング表を読む必要があり「結局どのモデルがどれくらい賢いのか」が分かりにくい場面があります。エンジニアで起業家のライアン・シェイ氏は、最先端AIモデルを人間のIQスケールに換算して表示するプロジェクト「AI IQ」を2026年5月12日に発表しました。
AI IQ — Intelligently Measuring AI Intelligence
https://www.aiiq.org/
Today I’m launching AI IQ — frontier AI models, scored on the human IQ scale.
Instead of endless leaderboard tables, AI IQ shows:
• Where models land on the IQ bell curve
• How frontier IQ is changing over time
• How models compare on IQ and EQ
• What intelligence costs in… pic.twitter.com/gylF4YRPv4— Ryan Shea (@ryaneshea) 2026年5月12日
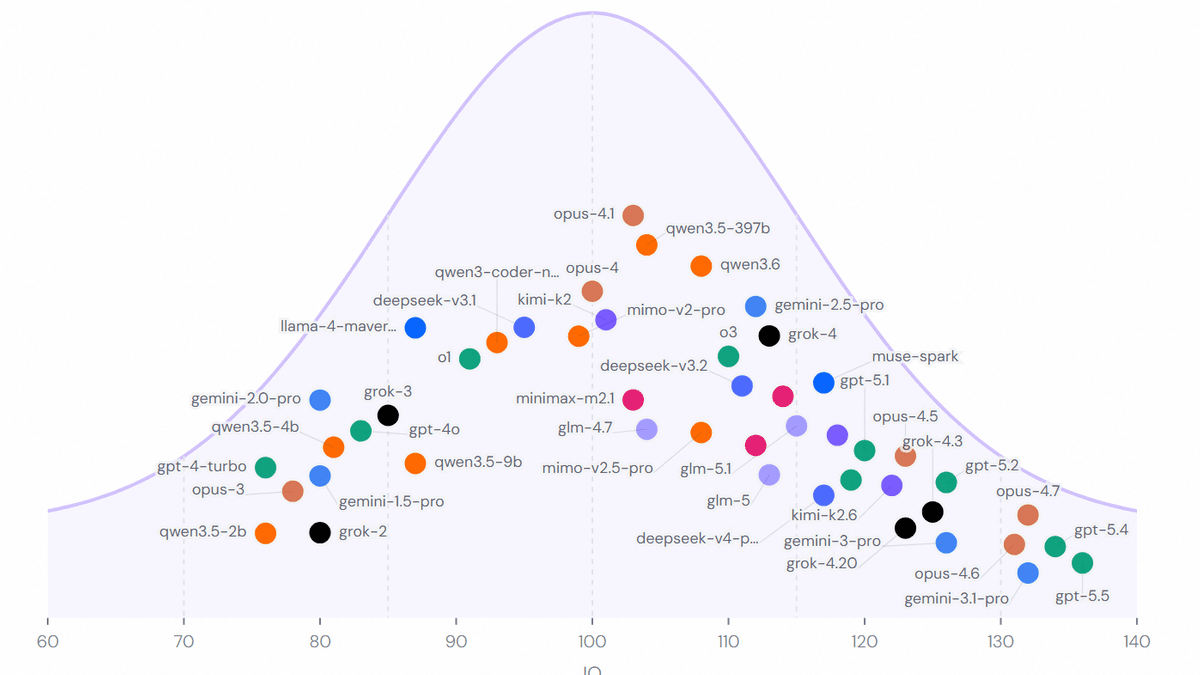
AI IQの狙いは、モデルごとの細かなベンチマーク点数を眺める代わりに、「AIモデルがIQのベルカーブ上でどこに位置するのか」「最先端AIモデルの知能スコアが時間とともにどう変化しているのか」「IQと感情知能であるEQを並べるとどう見えるのか」「実際に使う場合の知能あたりのコストはどれくらいなのか」を可視化することです。シェイ氏はGPT-5.5、Claude Opus 4.7、Gemini 3.1、Grok 4.3、Kimi K2.6、Qwen3.6、DeepSeek V4、Muse SparkなどのモデルをAI IQの図にまとめました。
AI IQの図はこんな感じ。記事作成時点では「gpt-5.5」が最高スコアとなる右端に位置しており、「gpt-5.4」「gemini-3.1-pro」「opus-4.7」と続いていました。
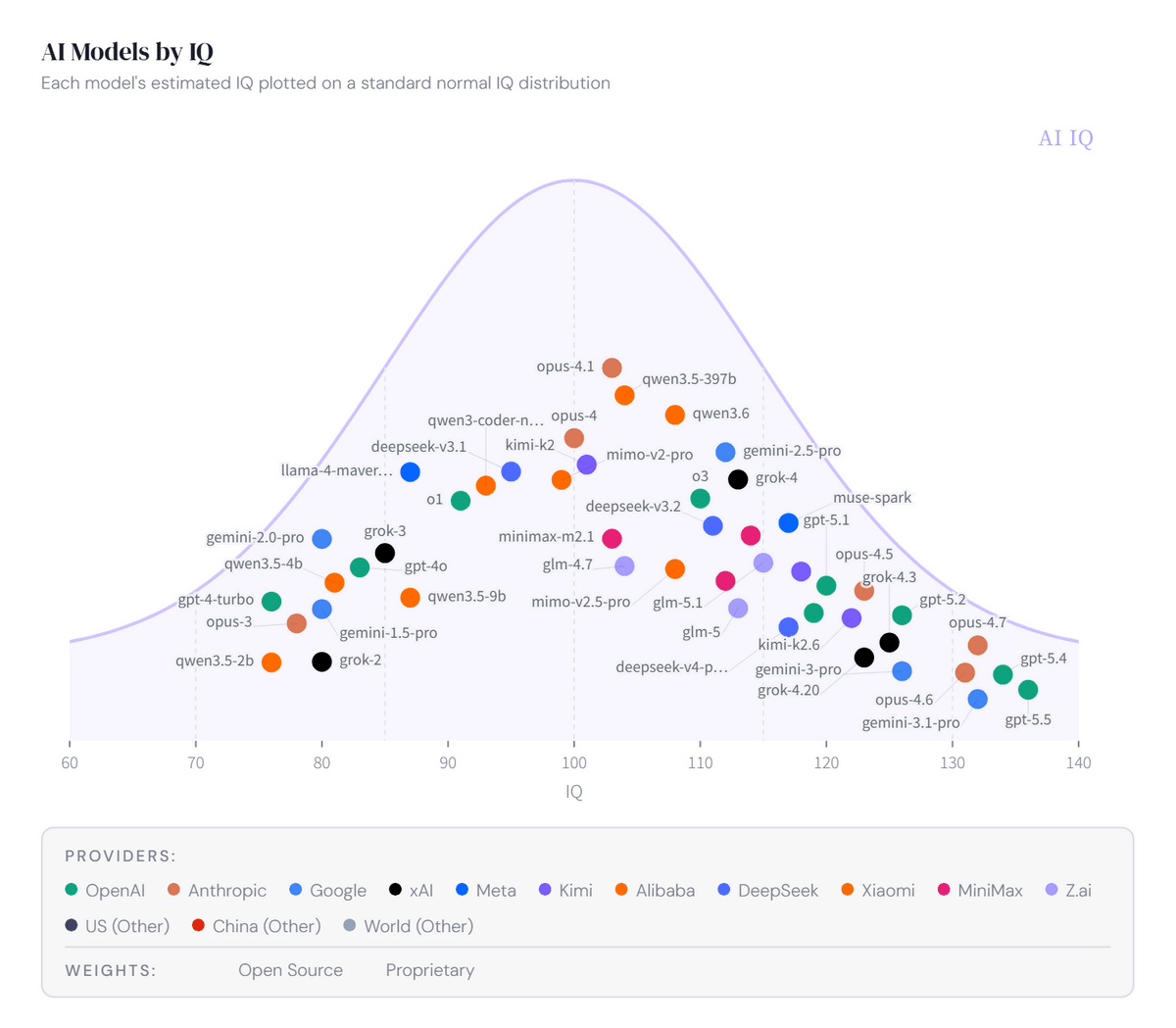
なお、AI IQの「IQ」は人間向けのIQテストをAIモデルにそのまま受けさせた結果ではなく、抽象推論、数学的推論、プログラミング推論、学術的推論という4分野の公開ベンチマークのスコアを「推定IQ」に変換し、4つの平均値から総合IQを算出したものとのこと。
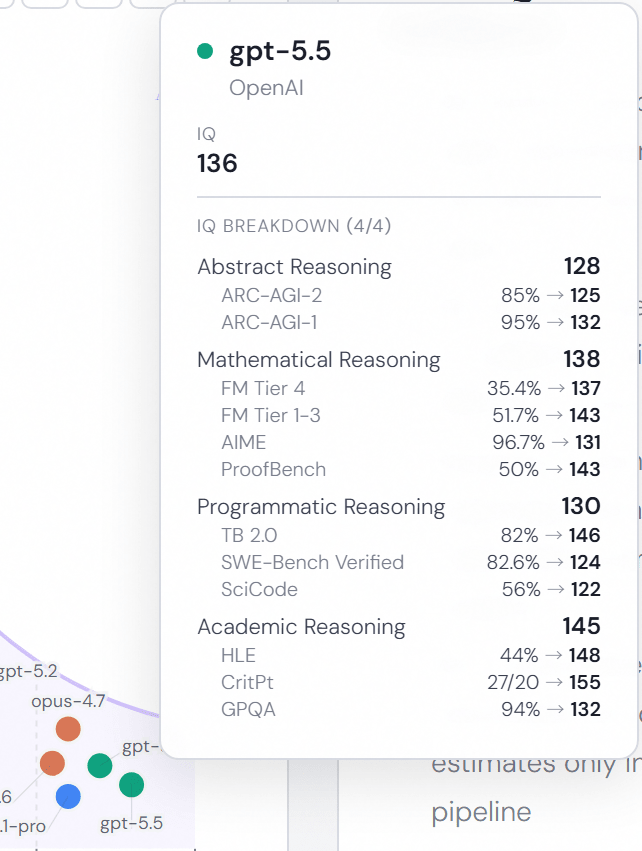
グラフ上で各モデルにカーソルをあわせるとどのように「IQ」スコアが算出されたのかという内訳を確認できます。算出にはARC-AGI-1、ARC-AGI-2、FrontierMath T1~3、FrontierMath T4、AIME、ProofBench、Terminal-Bench 2.0、SWE-bench、SciCode、Humanity’s Last Exam、CritPt、GPQA Diamondという合計12種類のベンチマークが使われています。暗記や訓練データへの混入で高得点を取りやすいベンチマークについてはスコアの上限を圧縮し、特定のベンチマークだけで総合IQが不自然に上がらないように調整しているとのこと。データが欠けている場合でも、欠損を控えめに補完する仕組みが採用されています。
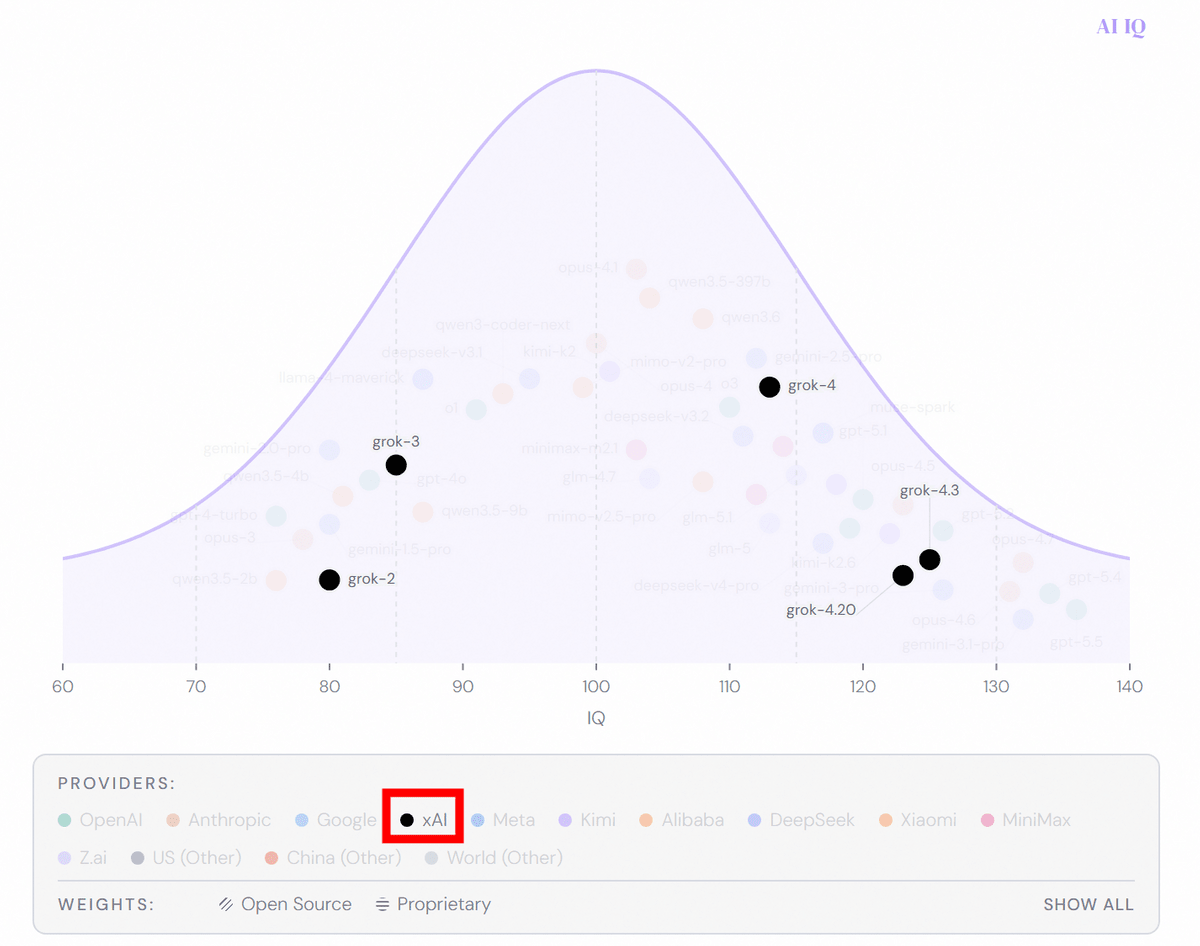
下の欄で表示するモデルをフィルターすることもできます。例えば「xAI」でフィルターすると、xAIが開発したGrokシリーズのモデルだけが表示されてGrokシリーズの進化を一目で確認できます。
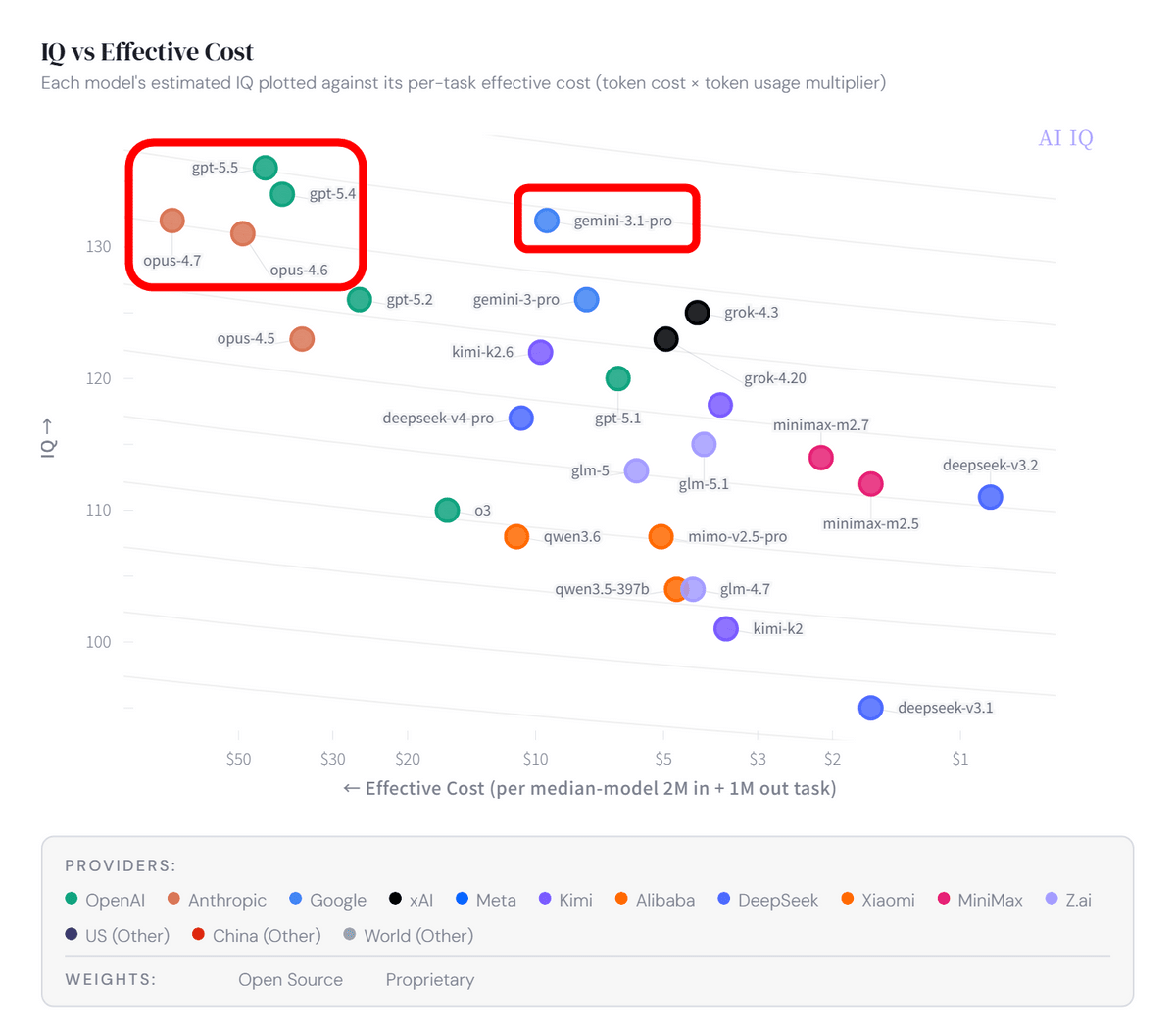
また、AIのコスト面を比較する「IQ vs Effective Cost」というグラフもあります。この「実効コスト」は、200万入力トークンと100万出力トークンの作業を想定したトークン価格に、モデルごとのトークン使用効率を掛け合わせた指標で、料金表上のトークン単価だけでなく、同じ作業をこなすためにモデルがどれだけトークンを使うかまで含めた実際の利用コストに近い数値とのこと。同等のIQスコアでも、GPT系やOpus系のモデルに比べてGeminiのコストの低さが際立っています。
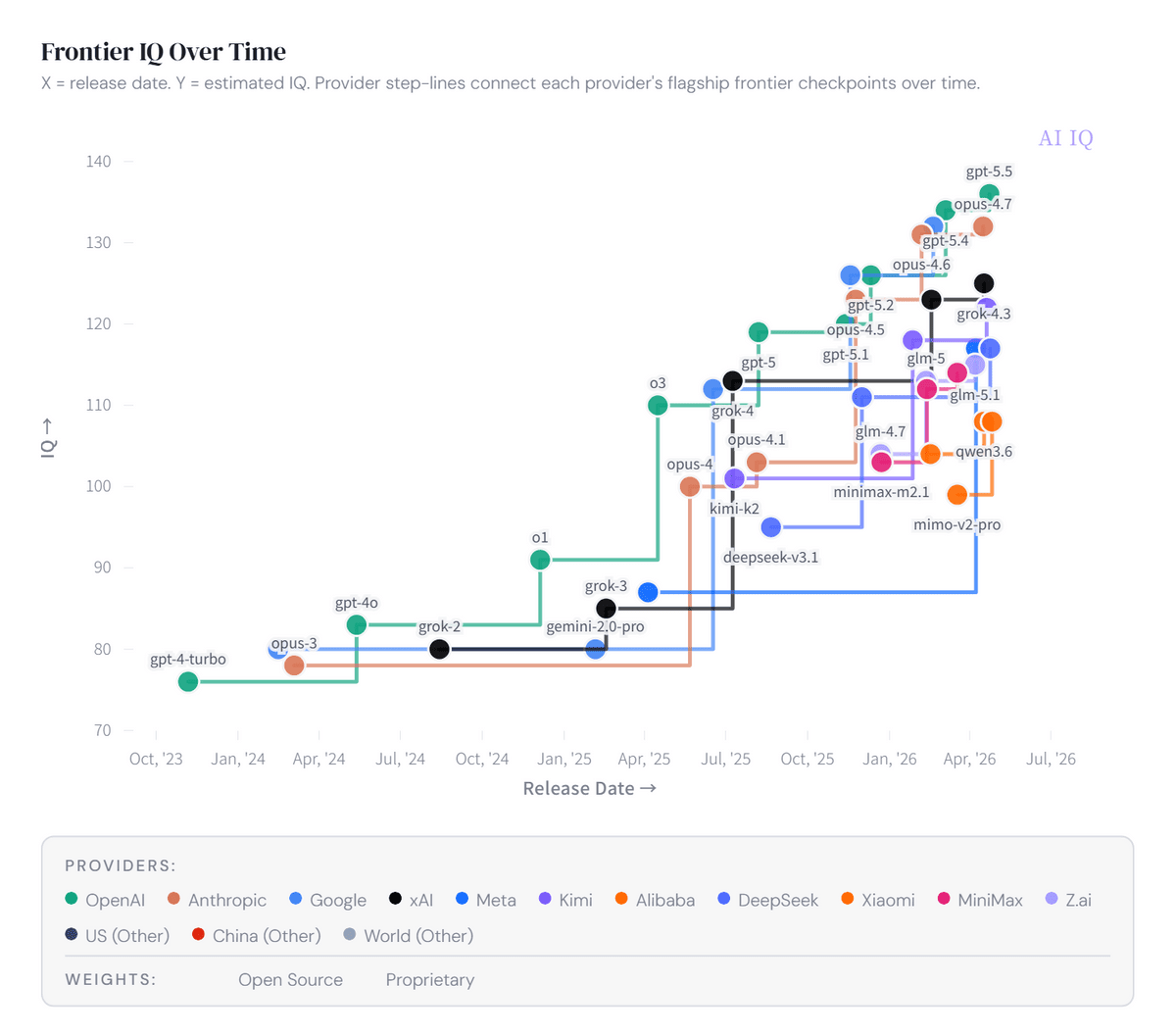
IQスコアが時系列でどのように推移してきたのかを確認できるグラフもありました。
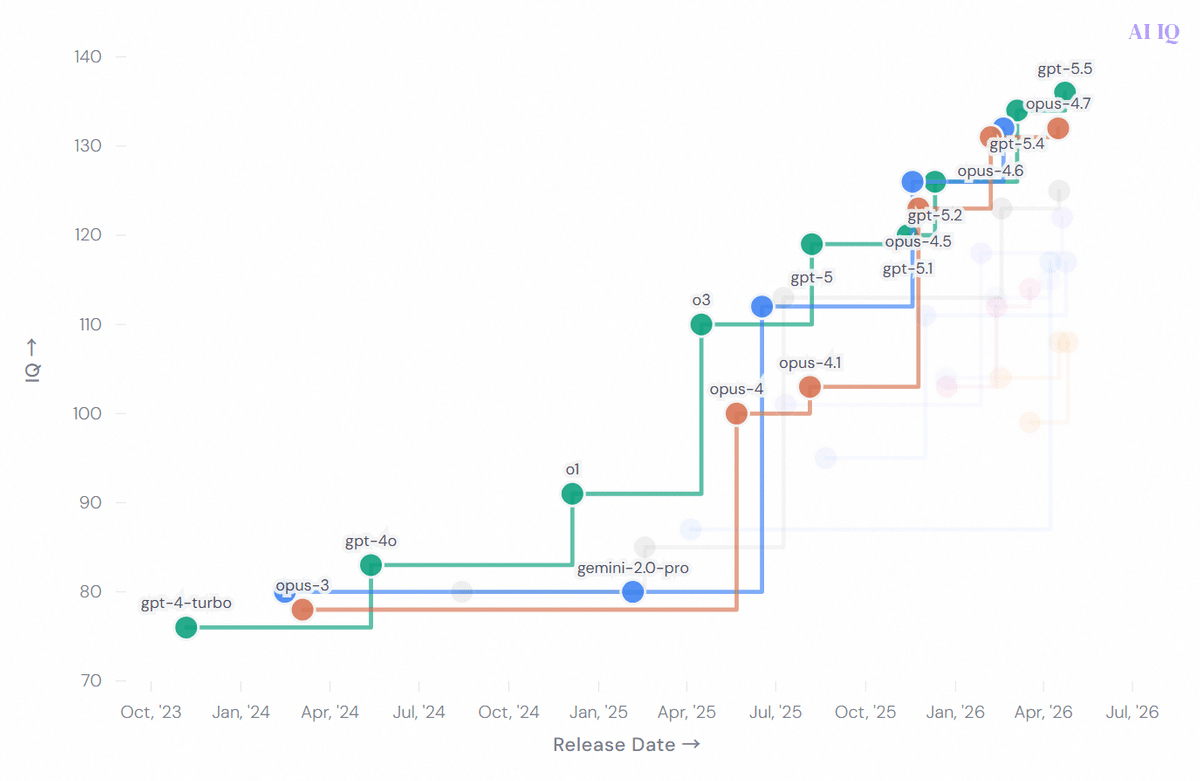
OpenAI、Anthropic、Googleという3社のモデルに絞ってみるとこんな感じ。最高スコアを目指してデッドヒートしている様子がうかがえます。
一方で、AIモデルの複雑な能力を単一のIQスコアにまとめる手法には批判も出ています。VentureBeatは「AIの能力は分野ごとの得意不得意が大きく、単一スコアに集約すると精密に見えるだけで実態を誤解させる可能性がある」という批判がX上で出ていると報じました。AI IQはベンチマーク表を読みやすくする試みである一方、推定IQという数値を「AIモデルの知能そのもの」と受け取るのではなく、複数のベンチマークを比較しやすくするための変換値として扱う必要があるとの指摘もあります。
シェイ氏は、最先端AIモデルはばらばらのベンチマーク表や発売直後の宣伝文句だけでは理解しづらくなっており、AI IQによって「どのAIモデルが実際に使う価値があるのか」を判断しやすくしたいと述べました。
この記事のタイトルとURLをコピーする
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。