

画像生成AI「Stable Diffusion」の開発元として知られるStability AIが音楽生成AI「Stable Audio 2.5」を2025年9月10日にリリースしました。Stability AIは「企業のブランドイメージや告知宣伝のサウンド制作向けに設計された初の音楽生成モデル」とアピールしています。
Stability AI Introduces Stable Audio 2.5, the First Audio Model Built for Enterprise Sound Production at Scale — Stability AI
https://stability.ai/news/stability-ai-introduces-stable-audio-25-the-first-audio-model-built-for-enterprise-sound-production-at-scale
Today we’re launching Stable Audio 2.5: The first audio model built for enterprise-grade sound production 🔊
Audio influences brand engagement by 86%, but few enterprises are leveraging audio as an extension of their brand, making customized sound an untapped differentiator.… pic.twitter.com/lCiSOO4RT2
— Stability AI (@StabilityAI) September 10, 2025
Stability AIは「オーディオはブランドエンゲージメントの86%に影響を与えますが、オーディオを自社ブランドの延長として活用している企業は少なく、カスタマイズされたサウンドは未活用の差別化要因となっています」と述べ、カスタマイズ可能な高品質オーディオの重要性を説いています。Stability AIによると、Stable Audio 2.5はStable Audioシリーズ初のエンタープライズグレードのサウンド制作向けに設計されたオーディオ生成モデルで、ブランドのニーズに合わせて調整可能なダイナミックな構成への需要に応える、品質と制御の向上を実現しているとのこと。
Stable Audio 2.5の特徴は以下の通り。
・最大3分間のトラックを2秒未満で生成
Stable Audio研究チームが開発した最先端のAdversarial Relativistic-Contrastive (ARC)方式を使用して事後トレーニングされたことで、Stable Audio 2.5は最大3分間のトラックを2秒未満で生成できる高速推論を実現しています。Stability AIはARC方式について、「我々の知る限り最速のテキスト音声モデルです」と述べています。
・ダイナミックかつカスタマイズ可能な楽曲を生成
Stable Audio 2.5は音楽に最適化されており、音楽構造が改善され、イントロ、展開、アウトロの複数パートに分かれた楽曲を生成可能。また、プロンプトへの対応も向上し、「高揚感」などの気分描写や、「豊かなシンセサイザー」などジャンルを超えた音楽表現への反応が向上しています。
・オーディオインペインティングのサポートでより高度な制御を実現
テキストからオーディオ、オーディオからオーディオへのワークフローに加え、Stable Audio 2.5は「オーディオインペインティング」をサポートしています。オーディオペインティングとは、ユーザーが独自のオーディオを入力し、開始位置を指定するだけで、モデルがコンテキストに基づいてトラックの残りの部分を生成するものです。「既存の楽曲の一部を入力して続きを改変」ということができないように、著作権で保護されているコンテンツの入力を利用規約で禁止しているほか、高度なコンテンツ認識技術を用いて著作権侵害の有無をチェックしているそうです。
Stable Audio 2.5はStableAudio.comから試すことができます。また、Stability AI APIからAPIキーを入手することも可能です。
Stable Audio – Generative AI for music & sound fx
https://stableaudio.com/
Stable Audioの使用手順は、以下の記事を見るとよく分かります。
文章で指示するだけで音楽を作れる音楽生成AI「Stable Audio 2.0」が登場したので使ってみた – GIGAZINE
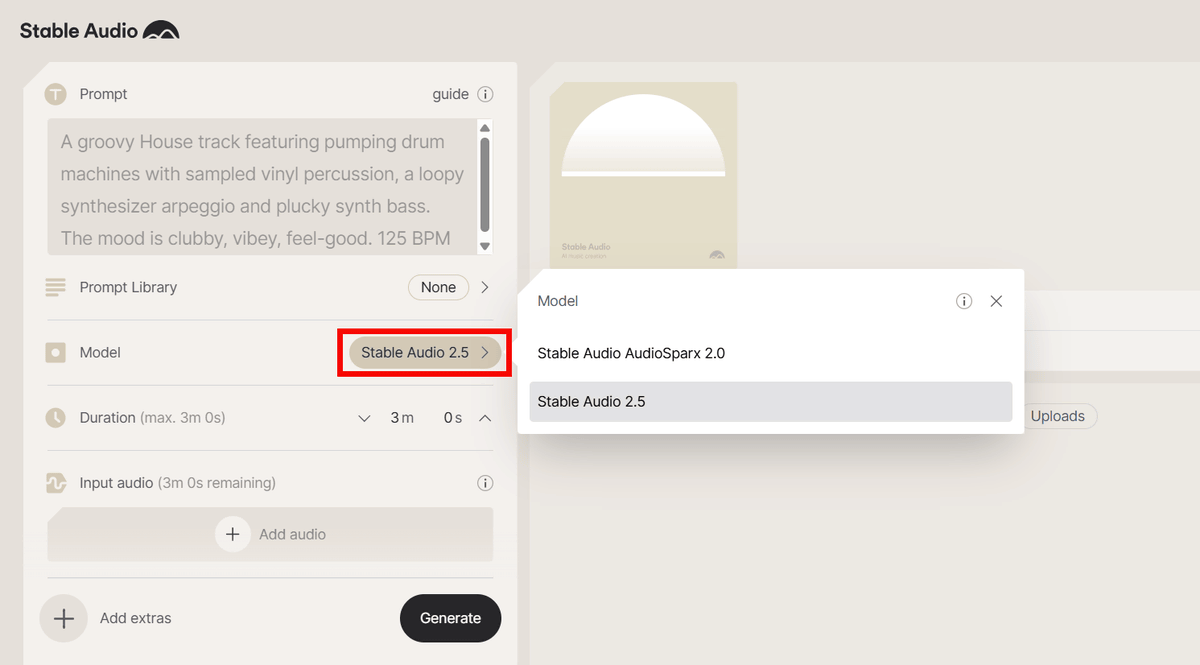
StableAudio.comにアクセスしてみたところ、モデルからStable Audio 2.5が選択できるようになっていました。
この記事のタイトルとURLをコピーする
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。