
近年、AIを用いた検索ツールの人気は急速に高まっており、多くのユーザーが従来の検索エンジンの代わりにインターネットをクロールして最新の関連情報を提供するAI検索エンジンを使用しています。しかし、ChatGPT searchやPerplexity、DeepSeek Searchなど8つのAI検索エンジンを対象とした調査の結果、多くのAI検索エンジンが誤った回答をユーザーに提供することが報告されました。
AI Search Has A Citation Problem – Columbia Journalism Review
https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php

従来の検索エンジンは一般的に、ユーザーをニュースサイトやその他の質の高いコンテンツへと導く仲介者として機能します。一方でAI検索エンジンは、インターネット上に存在する情報をもとに、それらの情報をAIが自動で解析・要約してユーザーに提供します。そのため、AI検索エンジンがどのようにニュースコンテンツにアクセスし、表示・引用するかを評価することは急務とされています。
デジタルジャーナリズムの研究を行うTow Center for Digital Journalismは、ライブ検索機能を備えた「ChatGPT search」「Perplexity」「Perplexity Pro」「DeepSeek Search」「Copilot」「Grok 2」「Grok 3」「Gemini」でテストを実施。ニュースコンテンツを正確に取得して引用する能力と、それができない場合の行動を評価しました。
Tow Center for Digital Journalismは実験として、各ニュースサイトから10件の記事をランダムに選択し、それらの記事の一部を抜粋、各チャットボットにクエリとして提供しました。その後、提供したクエリが対応する記事の見出しや配信元のニュースサイト、公開日、URLを特定するように依頼しました。

続いて各チャットボットからの返答を「記事の見出しが正しいか」「配信元のニュースサイトは正しいか」「URLは正しく取得できているか」の3つの属性に分けて手動で評価しました。なお、評価の結果はすべての属性が正しい「Completely Correct(完全に正しい)」、一部の属性は正しかったが、情報が不足している「Correct but Incomplete(正しいが不完全)」、一部の属性は正しかったものの、他の属性は正しくない「Partially Incorrect(部分的に正しくない)」、3つの属性がすべて正しくないか、欠落している「Completely Incorrect(全く正しくない)」、情報が提供されなかった「No Answer Provided(情報なし)」、robots.txtによってチャットボットによるクロールがブロックされた「Crawler Blocked(クローラーがブロック)」の6つに分けられました。

「ChatGPT search」「Perplexity」「Perplexity Pro」「DeepSeek Search」「Copilot」「Grok 2」「Grok 3」「Gemini」を対象とした実験の結果、全体として、これらのAI検索エンジンの多くは正しい記事を取得できず、クエリの60%以上に対して誤った回答を提供したことが明らかになりました。また、プラットフォームによって不正確さのレベルが異なり、Perplexityのエラー率は37%だった一方、Grok 3のエラー率は94%に達しました。
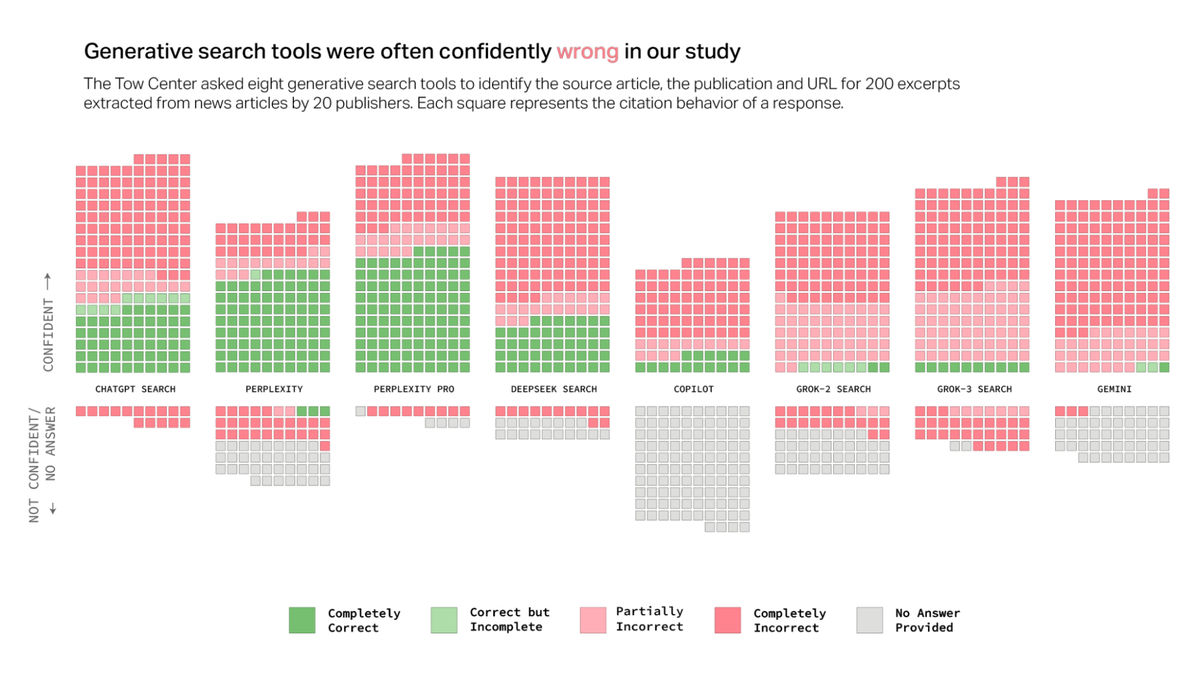
Tow Center for Digital Journalismは「私たちがテストしたツールのほとんどは『かもしれない』といった修飾的なフレーズをほとんど使用せず、不正確な答えを自信を持って提示しました。ChatGPTは200件の記事のうち、134件の回答でエラーが発生しましたが、『かもしれない』などの信頼性の欠如に関するフレーズを含めた回答にはわずか15件だけでした」と指摘しています。
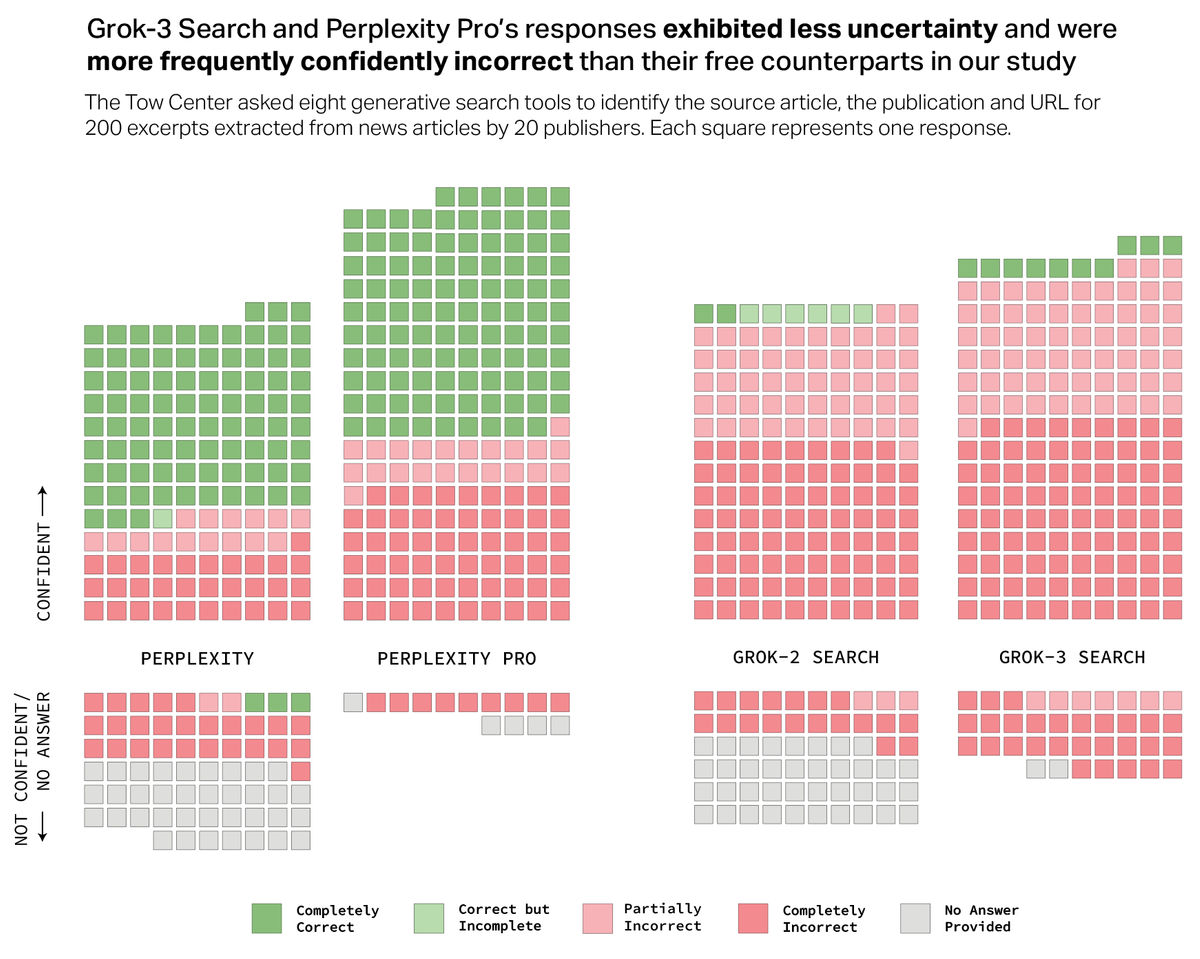
さらに、Tow Center for Digital Journalismによると、Perplexity ProやGrok 3などの利用には課金が必要なモデルの方がエラー率が高かったとのこと。Tow Center for Digital Journalismは「こうした結果は、信頼性と精度に対する潜在的に危険な錯覚をユーザーに与えてしまいます」と語りました。
また、ChatGPT searchならびにPerplexity、Perplexity Proは自社が使用するクローラーを公開しており、パブリッシャーに対してクローラーによるアクセスの許可を委ねています。しかし、これらのAI検索エンジンはアクセスすべきでないコンテンツを持つパブリッシャーに関するクエリに正しく答えることがあったとのこと。特にPerplexityでは、Perplexityのクローラーを許可していないはずのNational Geographicが有料記事として設定している10個のコンテンツから抜粋したクエリに対し、正しく識別・回答したことが報告されています。Perplexityをめぐっては、2024年6月にも「クローラーがrobot.txtの指示を無視してウェブサイトにアクセスしている」ことが指摘されています。

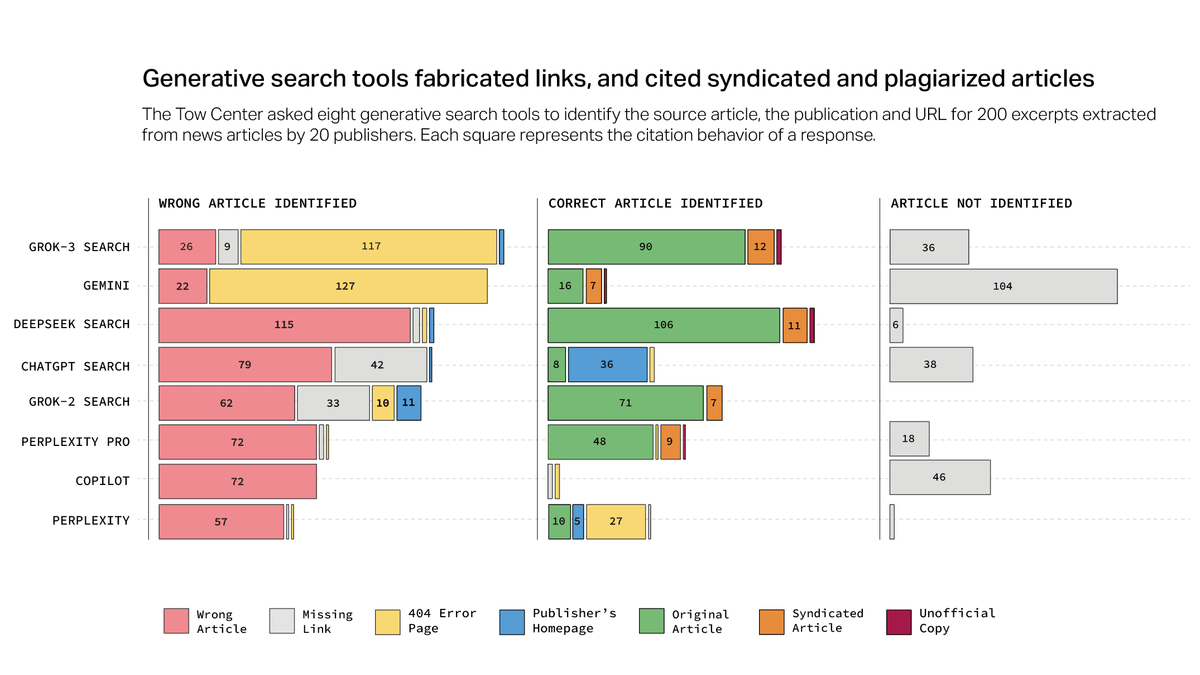
加えて、これらのAI検索エンジンは間違ったソースをクレジットしがちであることが報告されています。特に、DeepSeek Searchでは、200件の回答のうち、115回も出典を誤って表示していました。Tow Center for Digital Journalismは「チャットボットが記事を正しく識別しているように見えても、元のソースに適切にリンクしていないことが良くありました」と語っています。
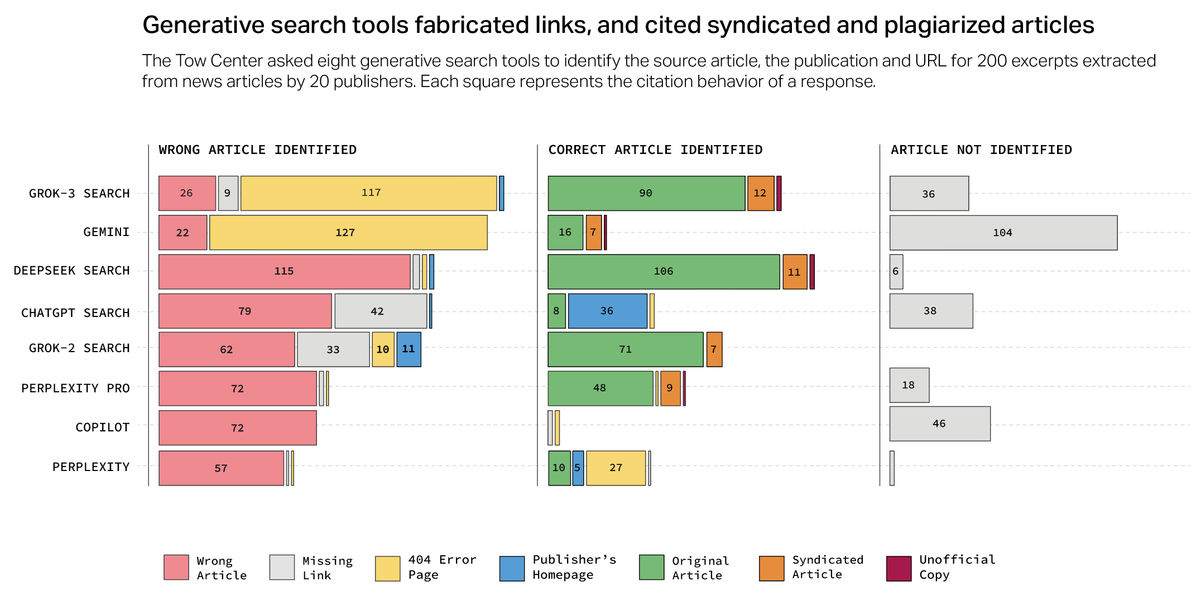
Tow Center for Digital Journalismはさらに、GeminiとGrok 3からの回答の半数以上が、捏造(ねつぞう)されたURLや破損したURLを提示していたことも報告しています。また、OpenAIとPerplexityはTimeとのパートナーシップ契約を締結しているにもかかわらず、いずれのAI検索エンジンもTimeのコンテンツを100%正確に特定することはできませんでした。

OpenAIの広報担当者は今回の調査結果を受け「私たちは要約や引用、明確なリンク、帰属表示を通じて、毎週4億人ものChatGPTユーザーが質の高いコンテンツを見つけるのを支援しており、パブリッシャーとクリエイターのサポートも行っています。私たちは今後もパートナーと協力して、引用の精度を向上させ、検索結果の拡充を続ける予定です」と語りました。また、Microsoftは「我々はrobot.txt基準を順守し、ページ上のコンテンツを生成AIモデルで使用することを望まないウェブサイトが提示する指示をこれからも尊重します」と述べています。なお、PerplexityやDeepSeek、xAI、Googleはコメントしていません。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。