

ChatGPTなどのAIを開発するOpenAIは、人間のように汎用(はんよう)的な知能を持つ「AGI(汎用人工知能)」の開発を目的としています。AGIの開発には懸念の声も多く上がっていますが、新たにOpenAIが「AGIおよびAIの安全性と整合性についての考え」を声明で発表しました。
How we think about safety and alignment | OpenAI
https://openai.com/safety/how-we-think-about-safety-alignment/
OpenAIは「AGIが全人類に利益をもたらすようにすること」を使命としており、これにはAIがもたらすネガティブな影響を軽減し、ポジティブな影響を得られるようにする安全対策が重要です。AIの安全性に関するOpenAIの理解は時間と共に大きく変化しているとのことで、今回の声明は発表された2025年3月6日時点の考えを反映したものとなっています。
かつてOpenAIは、AGIの開発について「ある特定の時点でAIが世界を変える問題を解決可能になる」と考えていましたが、記事作成時点では「AIの有用性が増していく中のある1点」にすぎないと考えています。つまり、AGIは降って湧いて登場するものではなく、着実にAIが進歩していく中で少しずつ現れるものだというわけです。
仮にAGIが特定の瞬間にいきなり現れるのであれば、安全性を確保するためにAIシステムを注意深く扱う必要があります。これは、OpenAIがGPT-2を開発した際に「危険すぎる」として公開を延期したアプローチの背景にあった考えです。しかしAGIが継続的な進化の途中にあるものならば、AIモデルを反復的に展開し、安全性や悪用についての理解を深めると共に社会が適応する時間を与えた方が、次のAIモデルをさらに安全で有益なものにする上で役立ちます。
記事作成時点のOpenAIは段階的な推論を行う「chain-of-thought models(施行の連鎖モデル)」という新しいパラダイムを展開しており、現実世界の人々によるchain-of-thoughtモデルの使用を通じて学習し、モデルを有用で安全なものにする方法を研究しているとのことです。

OpenAIがAGIを開発しているのは、AGIがすべての人々の生活をポジティブに変える可能性を信じているためです。OpenAIは声明で、「リテラシーから機械、医療に至るまで人類の改善のほとんどに知性が関与しているため、人類が直面するほとんどの課題は十分に有用なAGIがあれば乗り越えられると考えています」と述べています。
その上で、今日のAIシステムには以下の3つのカテゴリーで問題がみられるとOpenAIは指摘しています。
・人間による悪用
OpenAIは、人間が法律や民主的な価値観に反する方法でAIを使用することを「悪用」と考えており、これには政治的偏見や検閲、監視によって言論や思想の自由を弾圧することが含まれます。また、フィッシング攻撃や詐欺などもAIが悪用される分野のひとつです。
・整合性の失敗
整合性の失敗とは、AIの行動が関連する人間の価値観や指示、目標、意図と一致していない状態を指します。たとえば、AIがユーザーの意図しなかった悪影響をもたらしたり、人間に影響を及ぼして本来ならしなかったであろう行動を取らせたり、人間のコントロールを弱体化させたりする可能性があります。
・社会の混乱
AIは人間社会に急速な変化をもたらしており、それが社会的緊張や不平等の拡大、支配的な価値観や社会規範の変化など、世界や個人にとって予測不能で時に有害な影響をもたらす可能性があります。また、AGIが開発された場合、AGIへのアクセスは経済的成功を左右するものとなり、権威主義的な政府がAGIを悪用するリスクもはらんでいます。

OpenAIはAIが持っている現在のリスクを評価すると共に将来的なリスクを予測し、それに備えているとのこと。OpenAIは、思考や行動の元になっている基本原則を6つ紹介しています。
・不確実性を受け入れる
AIにおける将来の課題を知るには、理論だけでなく現実世界でのテストを行い、関係者からの洞察を引き出す必要があります。安全性を確保するため、OpenAIは安全性や脅威を厳密に測定し、潜在的な悪影響が表面化する前から脅威を緩和する取り組みを進めているとのことです。場合によっては、AIのリスクを懸念して制御された環境下のみでリリースしたり、AI自体ではなくAIを利用したツールのみを公開したりする可能性もあるとOpenAIは述べています。
・多層的な防御
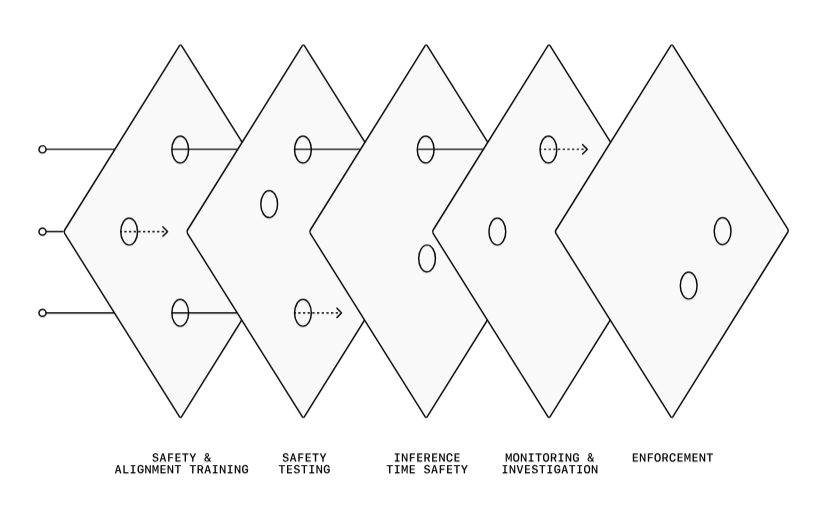
OpenAIは、単一の介入が安全で有益なAIを生み出す解決策になる可能性は低いと考えており、複数の防御を多層的に展開するアプローチを採用しています。たとえば、モデルのトレーニング時点で安全性を確保するサポート層を提供し、コンポーネントのテストは個別のものだけでなくエンドツーエンドで行います。展開後も監視や調査を継続し、場合によっては強制的なルールを設けることで、安全性を確保するとのことです。
・スケーリングの方法
OpenAIはAIモデルが進化すると共に知能や整合性を向上させる方法を模索しており、すでにOpenAIが開発した推論モデル・o1の推論能力を使用してo1自身の整合性を改善できることが実証されているとのこと。OpenAIは、「私たちの研究プログラムの一環として、統一された目的の下で安全性と能力を最適化する方法、そして整合性をとるために知能を活用する方法を、よりよく理解することを目指しています」と述べました。
・人間によるコントロール
OpenAIのAI整合性のアプローチは人間中心であり、人間の利害関係者が複雑な状況下でもAIを効果的に監督できるメカニズムの開発を目指しています。これには、AIトレーニングにおいて一般市民や利害関係者のフィードバックを取り入れたポリシーを導入したり、微妙なニュアンスや文化をAIモデルに反映したり、自律的な環境でも必要に応じて人間が介入できるようにしたりすることが重要です。
・コミュニティの取り組み
AGIが安全であり、すべての人々にとって有益であることを保証するには単一の組織では不十分であり、産業界・学会・政府・一般市民のオープンなコラボレーションが必要です。そのためにOpenAIは安全性研究の成果を発表し、現場にリソースや資金を提供し、安全性の確保に向けて自発的に取り組んでいくとしています。

OpenAIは、「私たちはすべての答えを知っているわけではなく、すべての疑問を持っているわけでもありません。わからないからこそ、私たちは進歩がどのように展開するのかという予想や、目にする課題へのアプローチについて間違っていることを受け入れます。私たちは健全な議論の文化を信じており、AIリスクに関する異なる視点や考え方を持つ人々、特にOpenAIの現在の立場に同意しない人々からのフィードバックを求めています」と述べました。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。