

GoogleがGemini 3 Flashの新機能として高精度な画像理解機能「Agentic Vision」を発表しました。Agentic Visionでは画像の拡大などを行いつつ能動的な画像理解が可能で、「Pythonで境界ボックスを描画して数を正確に数える」といったコード実行も駆使する機能も搭載しています。
Introducing Agentic Vision in Gemini 3 Flash
https://blog.google/innovation-and-ai/technology/developers-tools/agentic-vision-gemini-3-flash/
Googleによると、既存の画像認識AIは「画像を一度だけ見て内容を理解しようとする」という仕組みで動作しているとのこと。Agentic Visionでは「ユーザーの指示と画像をもとに思考し、必要に応じて画像の拡大やコード実行などの処理を行う」というエージェント的タスクをループ実行することで画像を高い精度で理解することができます。
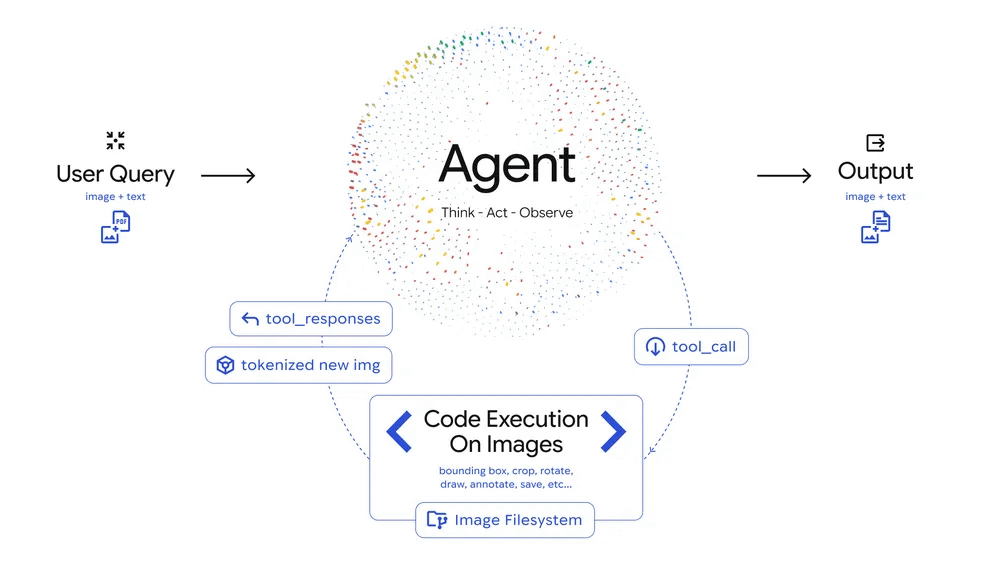
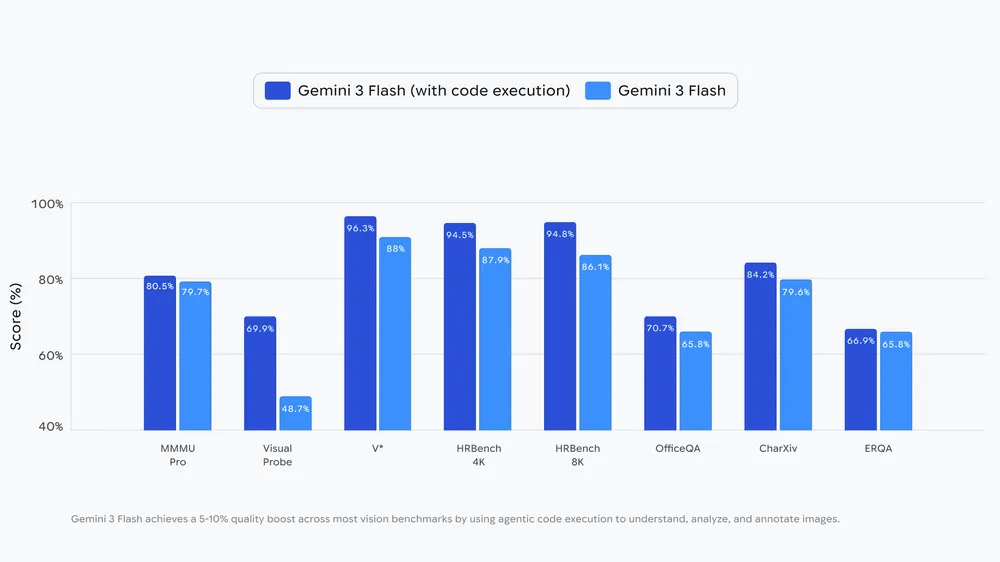
「画像理解」と「コード実行」は一見すると関係ない処理に思えますが、Googleが実行したベンチマークテストではコード実行を伴う画像理解処理の方が高いスコアを記録しました。
「コード実行を伴う画像理解」がどのような処理なのかは、Googleが用意した以下のデモを実行するとよく分かります。
Gemini Agentic Vision | Google AI Studio
https://aistudio.google.com/apps/bundled/gemini_visual_thinking?e=0&showPreview=true&showAssistant=true&fullscreenApplet=true
デモの1つである「指の本数を数える」というタスクを実行してみます。
タスクは手を描いた絵文字風イラストを提示して指の本数を数えさせるというもの。

Geminiは「それぞれの指を赤枠で囲んだ画像」を提示しつつ「指は6本あります」と正確に回答しました。
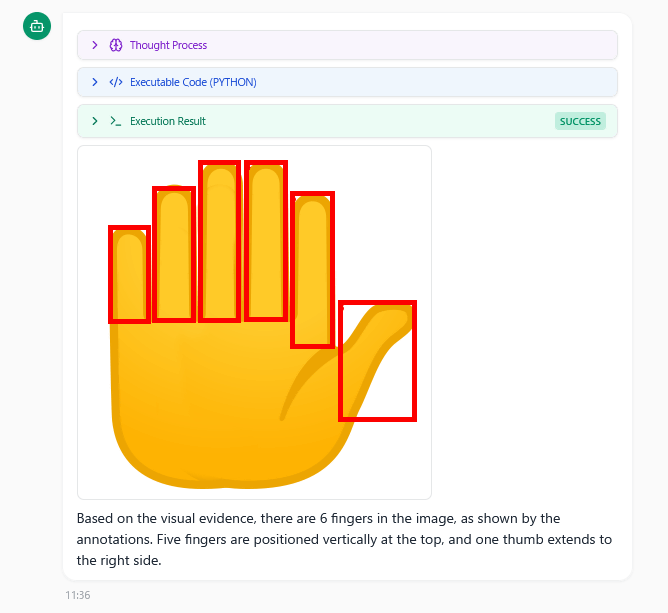
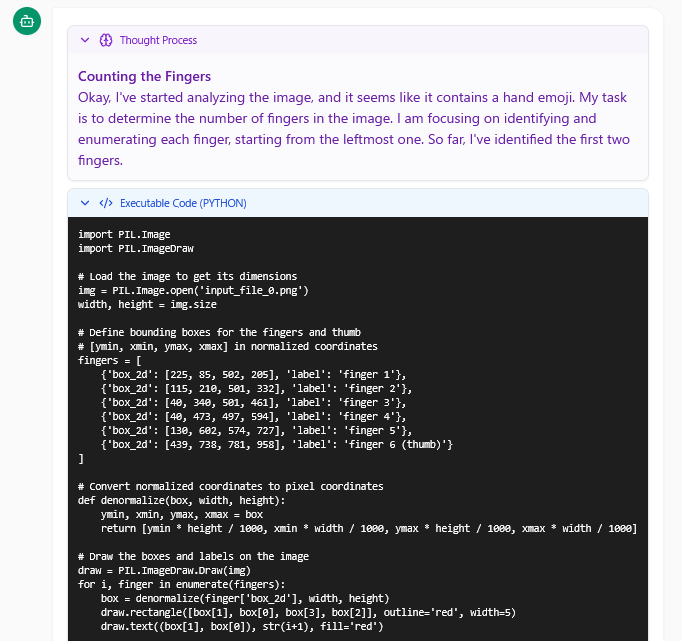
思考内容を確かめると、Pythonを用いてそれぞれの指を赤枠で囲む」という処理を実行していることが分かります。Googleによると、Pythonで境界ボックスを描画することで数え間違いを防いでいるとのこと。このようにコードを実行して画像に直接描き込むで推論の根拠を補強し、画像理解の精度を向上させているとううわけです。
Agentic Visionはほかにも画像を拡大したり画像に含まれる数値を正規化したりといった操作が可能です。
Agentic VisionはGeminiアプリの思考モードで実行できるように展開が始まっています。また、API経由でも利用可能です。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。