

Alibaba CloudのQwenチームが、音声合成モデル「Qwen3-TTS」ファミリーをオープンソースとして公開しました。Qwen3-TTSはテキストから自然で人間らしい音声を生成するだけでなく、説明文から新しい声を作るボイスデザインや、手元の短い音声から話者の声質を複製するボイスクローンまでを、同一系列のモデルとしてまとめて提供するのが特徴です。リポジトリはApache-2.0ライセンスで公開されています。
Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation!
https://qwen.ai/blog?id=qwen3tts-0115
QwenLM/Qwen3-TTS: Qwen3-TTS is an open-source series of TTS models developed by the Qwen team at Alibaba Cloud, supporting stable, expressive, and streaming speech generation, free-form voice design, and vivid voice cloning.
https://github.com/QwenLM/Qwen3-TTS
Qwen3-TTS – a Qwen Collection
https://huggingface.co/collections/Qwen/qwen3-tts?spm=a2ty_o06.30285417.0.0.29947896M5IzkF
Qwen3-TTSファミリーは2025年9月に発表された音声生成モデルで、フローマッチング(Flow-matching)を基盤とした生成AI技術を採用し、従来のモデルを凌駕する滑らかで自然な音声生成を可能にしているのが特徴。

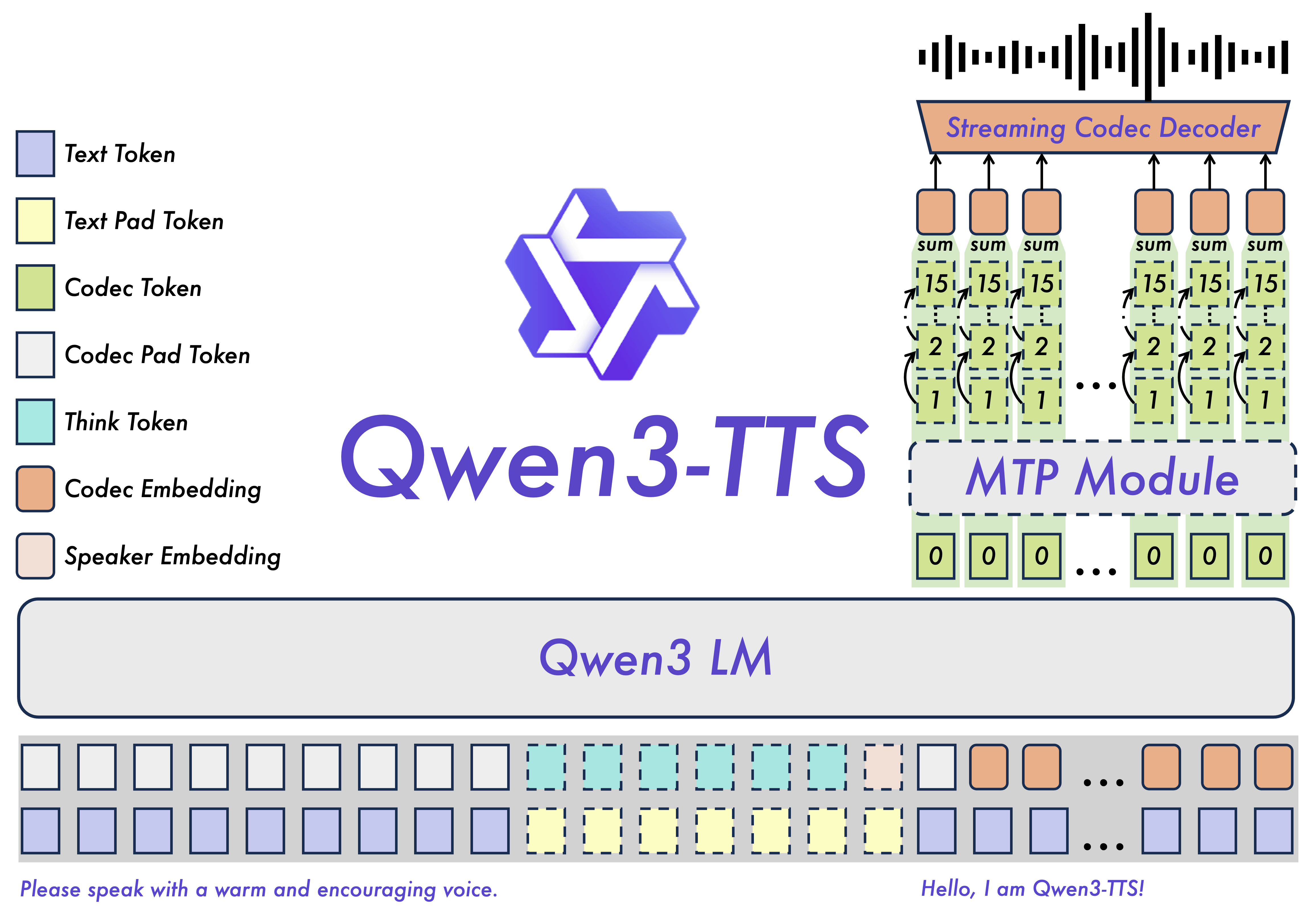
Qwen3-TTSファミリーは12Hzのトークナイザーによる音声表現を土台に、ストリーミングと非ストリーミングの両方を単一モデルで扱える「Dual-Track」型の音声生成が可能で、1文字の入力後すぐに最初の音声パケットを出力でき、合成のエンドツーエンド遅延が最小97msに達するとのこと。つまり、リアルタイム対話のような用途を強く意識した設計だと言えます。
Qwen3-TTSファミリーのモデル系統には、VoiceDesign、CustomVoice、Baseの3系統。
VoiceDesignは「落ち着いた低めの声」「明るい若年の話し方」といった自然言語の指示に基づいて声を設計するためのモデルで、音色や感情、韻律といった複数の属性を指示で制御できることを狙っています。
CustomVoiceは指示に応じたスタイル制御を行い、性別や年齢、言語や方言の組み合わせを含む9種類のプリセット声質が用意されています。
Baseはユーザーの入力音声から約3秒で素早くボイスクローンを行える土台モデルで、追加のファインチューニング用途にも使える位置づけです。
モデル規模としては、パラメーター数に応じて1.7B(17億)と0.6B(60億)が存在しており、トークナイザーとして「Qwen3-TTS-Tokenizer-12Hz」も合わせて公開されています。対応言語は中国語、英語、日本語、韓国語、ドイツ語、フランス語、ロシア語、ポルトガル語、スペイン語、イタリア語の10言語で、複数の方言系のボイスプロファイルも扱うとのこと。
Qwen3-TTSはApache-2.0ライセンスの下で、TTSモデルのQwen3-TTS-12Hz-1.7B-VoiceDesign、1.7B-CustomVoice、1.7B-Base、0.6B-CustomVoice、0.6B-Base、そして音声をコード化してエンコードとデコードを行うQwen3-TTS-Tokenizer-12Hzがオープンソースとして公開されています。Qwen3-TTSのモデル本体のほか、examplesやfinetuning、assetsといったディレクトリが含まれており、推論実行や学習、周辺素材をまとめて取り扱う前提で整備されています。
また、Qwen3-TTSのデモはHugging Faceの以下ページで公開されています。
Qwen3-TTS Demo – a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen3-TTS?spm=a2ty_o06.30285417.0.0.2994c921Jx9tMq
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。