

Googleが、差分プライバシー(DP)と呼ばれる技術を用いてゼロから学習させた、同社初となるプライバシー保護特化の大規模言語モデル(LLM)「VaultGemma」を発表しました。これは、AIモデルが学習データの内容を「記憶」し、意図せず出力してしまうプライバシー上のリスクに対処することを目的としています。
VaultGemma: The world’s most capable differentially private LLM
https://research.google/blog/vaultgemma-the-worlds-most-capable-differentially-private-llm/
[2501.18914] Scaling Laws for Differentially Private Language Models
https://arxiv.org/abs/2501.18914
google/vaultgemma-1b · Hugging Face
https://huggingface.co/google/vaultgemma-1b
VaultGemmaは、GoogleのオープンモデルファミリーであるGemmaを基盤としており、パラメータ数は10億(1B)です。VaultGemmaの最大の特徴は、差分プライバシーをモデルの事前学習の全段階に適用している点にあります。
差分プライバシーは、数学的に較正されたノイズを学習プロセスに追加することで、個々の学習データが最終的なモデルに与える影響を制限し、特定の情報が記憶されるのを防ぐ技術です。これにより、VaultGemmaは学習データに対して強力なプライバシー保証を提供します。
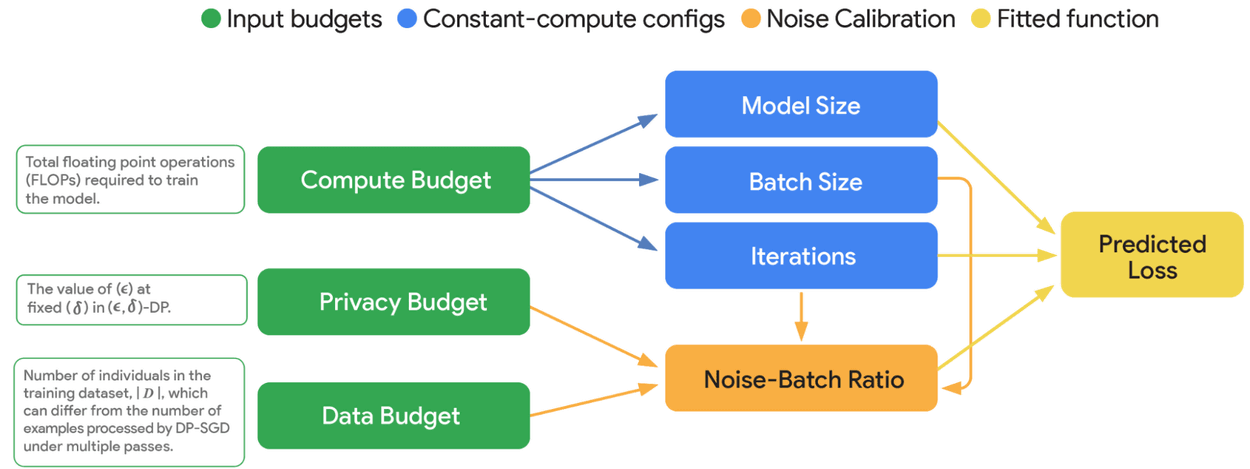
ただし、差分プライバシーをLLMの学習に適用するには課題も伴います。たとえば、ノイズの追加は、モデルの性能低下や学習の安定性、計算コストの増加といったトレードオフを生じさせます。この課題を克服するため、Googleの研究チームは差分プライバシー環境下における新たな「スケーリング則」を確立しました。
Googleはこの研究で、計算資源(Compute Budget)、プライバシー保護の強度(Privacy Budget)、データ量(Data Budget)の間の複雑な関係をモデル化し、与えられた制約の中で最適な学習構成を見つけ出すことを可能にしています。このスケーリング則に基づき、VaultGemmaはGemma 2のアーキテクチャを基に、2048個のTPU v6eチップを用いて学習されました。
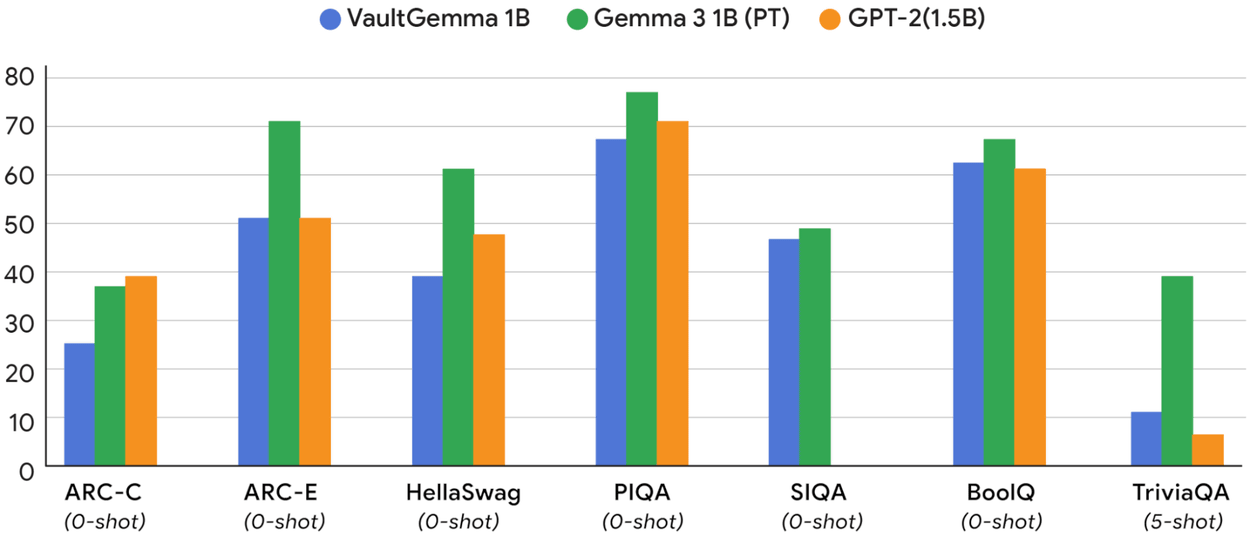
性能面では、差分プライバシーの導入によるトレードオフが存在します。各種学術ベンチマークにおけるVaultGemmaの性能は、同規模の非プライベートモデルであるGemma 3と比較すると劣りますが、2019年に公開されたGPT-2のような旧タイプの非プライベートモデルとは同等の性能を示したとGoogleは述べています。つまり、差分プライバシーの導入には、約5~6年分の技術的進歩に相当する性能のトレードオフがあるといえます。
一方でプライバシー保護の効果は絶大で、学習データの一部を与えて続きを生成させる記憶テストにおいて、非プライベートモデルであるGemma 3ではデータの記憶が検出されたのに対し、VaultGemmaでは一切検出されなかったとのこと。
Googleは、プライバシーを保護するAIの研究開発を加速させるため、VaultGemmaのモデルの重みデータ(ウェイト)をHugging FaceやKaggleで公開しています。Googleは、プライバシーが重視されるアプリケーションの基盤として、またプライベートなAI技術のさらなる研究のための強力なベースラインとして、VaultGemmaがコミュニティに貢献することに期待を寄せています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。