

研究者らが複数のAIモデルに文章の「続き」を予測させる実験を行ったところ、Metaの「Llama 3.1 70B」が「ハリー・ポッターと賢者の石」の42%を再現できることがわかりました。
[2505.12546] Extracting memorized pieces of (copyrighted) books from open-weight language models
https://arxiv.org/abs/2505.12546
Meta’s Llama 3.1 can recall 42 percent of the first Harry Potter book
https://www.understandingai.org/p/metas-llama-31-can-recall-42-percent
今回の研究は、スタンフォード大学、コーネル大学、ウェストバージニア大学のコンピューター科学者と法学者のチームによって実施されました。チームは、大規模言語モデル(LLM)の訓練によく使われていた書籍データセット「Book3」に含まれる書籍のテキストを、5つのAIモデルで再現できるかどうかを調査しました。
Book3には約20万冊の書籍のテキストが記録されていましたが、著作権で保護されている書籍も含まれているとして著作権侵害対策団体から抗議があり、記事作成時点では削除されています。
チームは実験のために5つの「オープンウェイトモデル」をピックアップしました。オープンウェイトモデルとは、AIが出力を決定する際に考慮するパラメーター「重み(ウェイト)」を公開しているモデルです。重みが分かることで、実際にAIモデルに出力を行わせなくても出力結果を予測できるため、実験コストが大幅に下がるという利点があります。

大規模言語モデルが出力を決定する際は、重みなど複数のパラメーターを用いて結果を「予測」します。これについてAI専門家のティモシー・リー氏がわかりやすい例を挙げています。
大規模言語モデルは、単語を生成し、生成した単語の次に並ぶ可能性のある単語を複数列挙して確率分布を生成します。例えば「ピーナッツバターと」というフレーズを入力すると、大規模言語モデルは次のような確率分布を生成します。
・ジャム = 70%
・砂糖 = 9%
・ピーナッツ = 6%
・チョコレート = 4%
・クリーム = 3%
大規模言語モデルがこのような確率のリストを生成した後、システムはこれらの選択肢の中からランダムに1つを選び、その確率で重み付けをします。70%の確率で「ピーナッツバターとゼリー」が選ばれ、9%の確率で「ピーナッツバターと砂糖」が選ばれるといった具合です。
研究チームはこれを応用して結果を予測しました。
例えば、あるモデルが「私の好きなサンドイッチは」に「ピーナッツバターとジャム」と答える確率を推定したいとすると、以下のように計算します。
・大規模言語モデルに「私の好きなサンドイッチは」というテキストを与え、「ピーナッツ」と出力する確率を調べる。仮に20%だったとする。
・「私の好きなサンドイッチはピーナッツ」と入力し、次に「バター」が出力される確率を調べる(90%とする)
・「私の好きなサンドイッチはピーナッツバター」と入力し、「と(and)」の確率を調べる(80%とする)
・「私の好きなサンドイッチはピーナッツバターと」と入力し、「ジャム」の確率を調べる(70%とする)
これで、0.2×0.9×0.8×0.7=0.1008という確率を算出できます。この大規模言語モデルが「私の好きなサンドイッチは」に「ピーナッツバターとジャム」と返す確率は約10%ということになります。
この方法を用いることで、実際に結果をAIに生成させる必要がなくなるため、研究コストが削減されました。

研究者らは36冊の本を取り上げ、本文を100トークンの文章に分割しました。最初の50トークンを入力プロンプトとして大規模言語モデルに与え、大規模言語モデルが次の50トークンを出力したとき、元の文章と一言一句同じになる確率を計算したのです。
チームはこの計算をかなり厳密に行いました。50トークンのうち1トークンでも間違っていれば「同じではない」と判断し、一言一句同じになる確率が50%以上であれば、大規模言語モデルがその文章を再現できると判断しています。
「ハリー・ポッターと賢者の石」で試した結果は以下の通りです。5つある図は、上から「Pythia 12B」「Phi 4」「Llama 1 13B」「Llama 1 65B」「Llama 3.1 70B」という5つのモデルの出力結果を示しており、図の線は元の文章と出力が一致した部分を表しています。Llama 3.1 70Bは全体の42%で一致しました。
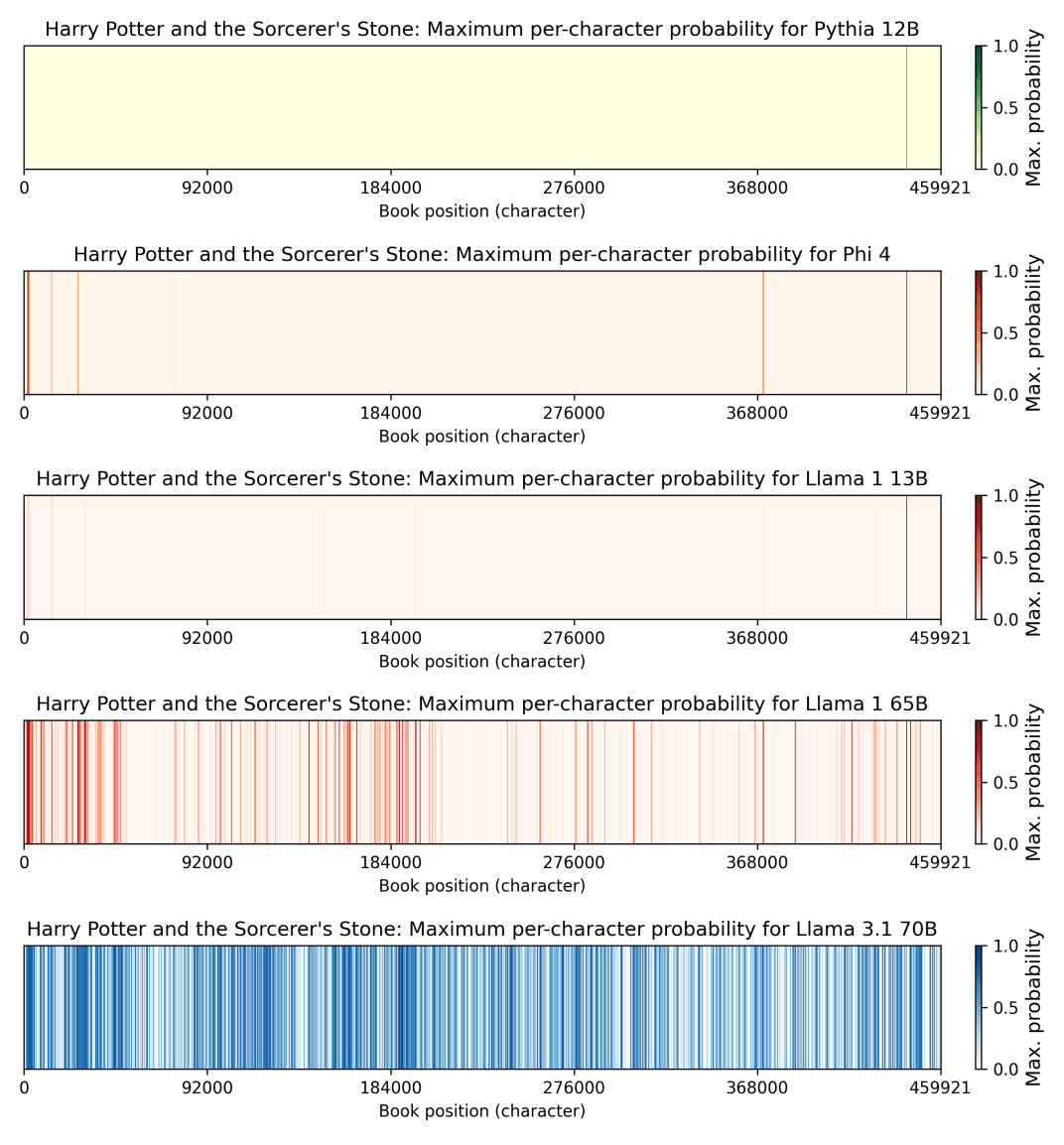
Llama 3.1 70Bは他にも「ホビット」や「1984年」でも同様に高い一致率を示しました。一方で、リチャード・キャドリーの2009年の小説「サンドマン・スリム」では0.13%しか再現できないなど、書籍により顕著な違いが見られました。
この結果だけでは、「ハリー・ポッターと賢者の石」のテキスト全文がLlama 3.1 70Bのトレーニングに使われたのか、一部だけが使われたのか、あるいはハリー・ポッターのファンフォーラムや書評など、ただの「引用」が使われただけなのかは判断できません。ハリー・ポッターや1984年の再現率が高く、サンドマン・スリムの再現率が低かったのは、単に前者の方が人気でオンライン上に関連するコンテンツがたくさんあったからだと考えることもできます。
書籍によって再現率が大きく異なるという事実について、AI専門家のリー氏は「これは、AI企業に対して集団訴訟を起こしている法律事務所にとっては頭痛の種となるかもしれません」と指摘しています。
Llamaを開発するMetaは、先述のサンドマン・スリムの著者であるキャドリー氏ら3人の作家から著作権侵害で集団訴訟を提起されています。3人はそれぞれ自著の権利を侵害されたと訴えているのですが、「原告団はほぼ同様の法的・事実的状況にある」と認められなければならないという制約があり、今回の調査結果と照らし合わせると、原告によって侵害の度合いが大きく異なる可能性が浮上します。これにより、3人はそれぞれ個別に訴訟を提起せざるを得なくなる可能性があるとリー氏は考察し、Metaにとって有利に働く可能性があると主張しました。

AI業界は、トレーニングの過程で著作物を使用することは「フェアユース」の原則に基づき正当化されるという主張をしています。これについてリー氏は「Llama 3.1 70Bがハリー・ポッターの大部分を再現したという事実は、裁判所がこのようなフェアユースの問題をどう考えるかを左右する可能性があります。フェアユースの重要な部分は、その利用が『変形的』であるかどうか、つまり企業が何か新しいものを作ったのか、それとも単に他者の著作物から利益を得ているだけなのか、という点です。大規模言語モデルがハリー・ポッターなど人気作品の大部分を再現できるという事実は、裁判官がこうしたフェアユースの議論を懐疑的に見るようになる可能性があります」と指摘しました。
コーネル大学法学教授のジェームズ・グリメルマン氏は、オープンウェイトモデルがクローズドウェイトモデルよりも法的な危険にさらされる危険性がある点について言及しています。今回の研究が成功したのはひとえに「重み」が公開されていたためで、仮に今回の研究が元となり著作権侵害の審理がAI企業に不利に働いた場合、今後重みが公開されなくなる可能性があります。AI企業に重みを公開する義務はなく、AI業界の発展を願って善意で公開されていることがほとんどであるためです。
リー氏は「著作権法は、企業がオープンウェイトモデルのリリースを考慮する際の強い阻害要因になるかもしれません。一方、オープンウエイトモデルを発表した企業を事実上罰するのは良くないと判断する裁判官もいるかもしれません。調査結果の中には、作家らの主張を後押しするものもあれば、被告にとって有益になるものもあるのです」と述べました。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。