
Google Researchは大規模言語モデルとベクトル検索エンジンのための新しい圧縮技術群の1つとして、「TurboQuant」を2026年3月に発表しました。AIで大きな負担になっているメモリ使用量を減らしつつ、処理速度と検索性能も高めることを目的としたこのTurboQuantとはどういうものなのかを視覚的に理解するためのサイト「TurboQuant: A First-Principles Walkthrough」が公開されています。
TurboQuant: A First-Principles Walkthrough
https://arkaung.github.io/interactive-turboquant/
Google Researchが発表したTurboQuantがどういうものかは以下の記事にまとめられています。
AIを8倍高速化しメモリ使用量を6分の1に削減するGoogleの新アルゴリズム「TurboQuant」 – GIGAZINE

「TurboQuant: A First-Principles Walkthrough」の良いところは、TurboQuantをいきなり数式で説明するのではなく、ベクトル、内積、量子化、回転といった基礎から、画面上で動く図を使って順番に理解できるようにしている点です。サイト内のグラフはライブで動作し、数値もブラウザ上で計算されるため、読者はスライダーやドラッグ操作を通じて「なぜその処理が必要なのか」を目で追うことができます。
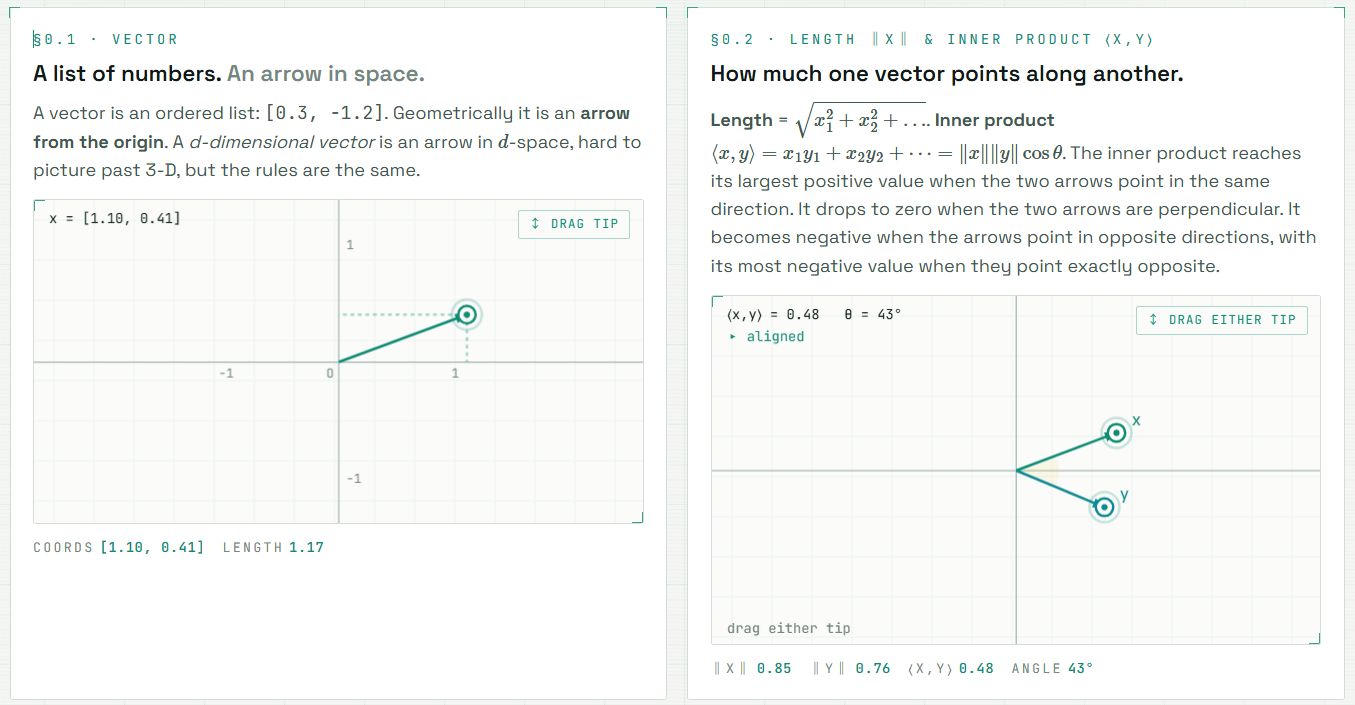
例えば、以下は「ベクトルとは数値のリストであり、空間上の矢印である」という基本的な知識、そしてベクトルの内積とは何かを視覚化しています。
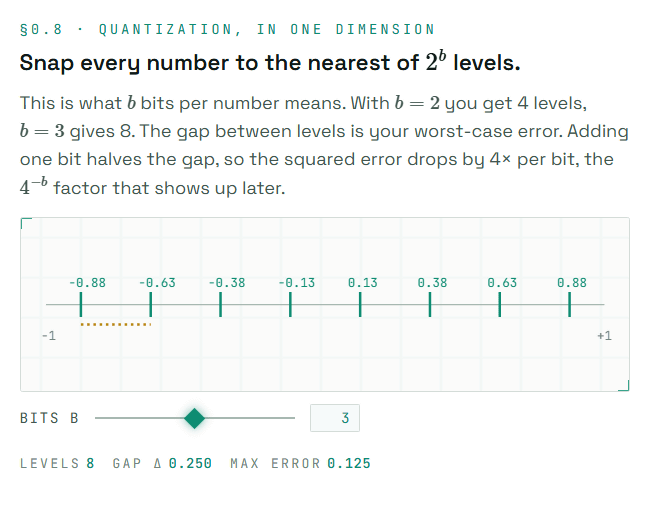
量子化とは簡単に言えば、細かい数値をいくつかの代表値に丸める処理です。たとえば1つの数値を2ビットで表すなら、使える値は4段階だけになります。数値を大幅に削れる一方で、元の値と丸めた値の間には誤差が生じます。サイトでは数値がどの段階に吸い寄せられるのかを図で見せることで、「ビット数を減らす」とは具体的に何をしているのかを視覚的に説明しています。
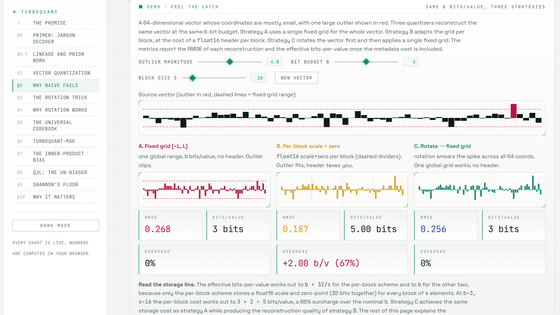
ただし、普通に丸めるだけではうまくいかない場合があります。AIモデルのベクトルには、一部の座標だけが極端に大きくなる「外れ値」が含まれることがあります。固定された範囲で数値を丸めると、こうした外れ値がつぶれてしまったり、逆に外れ値に合わせたせいで小さな値の表現が粗くなったりします。
従来の実用的な量子化手法は、この問題を避けるために、短いブロックごとにスケールやゼロ点を追加で保存します。しかし、追加情報を保存すると、実際のメモリ使用量は名目上のビット数より大きくなります。サイトでは、3ビットで保存しているつもりでも、ブロックごとの追加情報を含めると実効的には4~5ビットになる例が示されています。
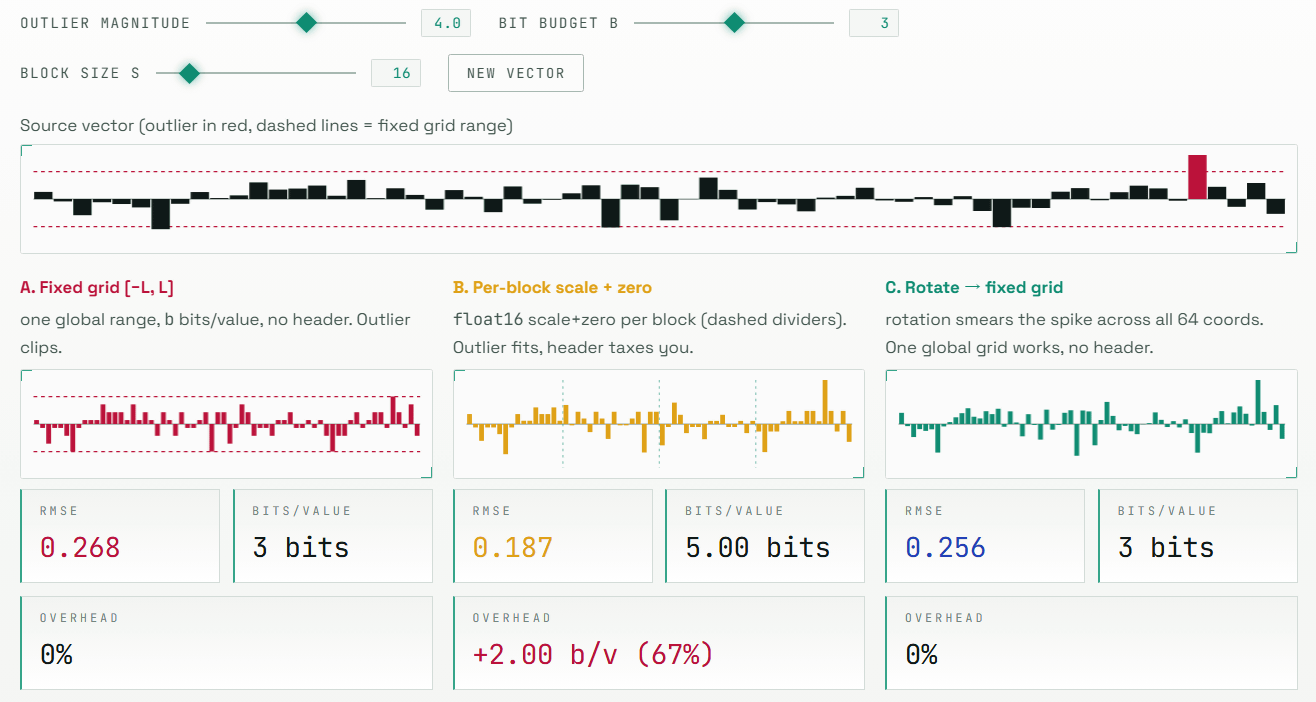
TurboQuantの中心的なアイデアは、数値を丸める前にベクトルをランダムに回転させることです。回転といっても、ベクトルの長さやベクトル同士の関係を壊すわけではありません。空間の見方を変えるだけなので、ベクトルの幾何学的な意味は保たれます。一方で、1つの座標に集中していた大きな値は、回転後には多くの座標へ分散されます。つまり、扱いにくい外れ値を、量子化しやすい形にならしてから圧縮するわけです。
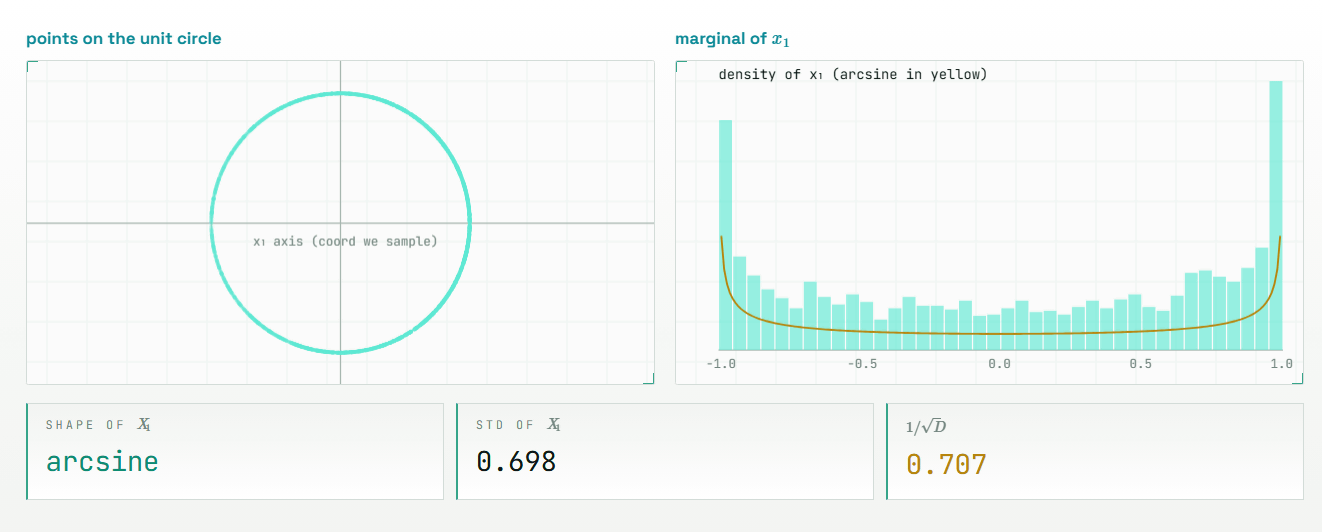
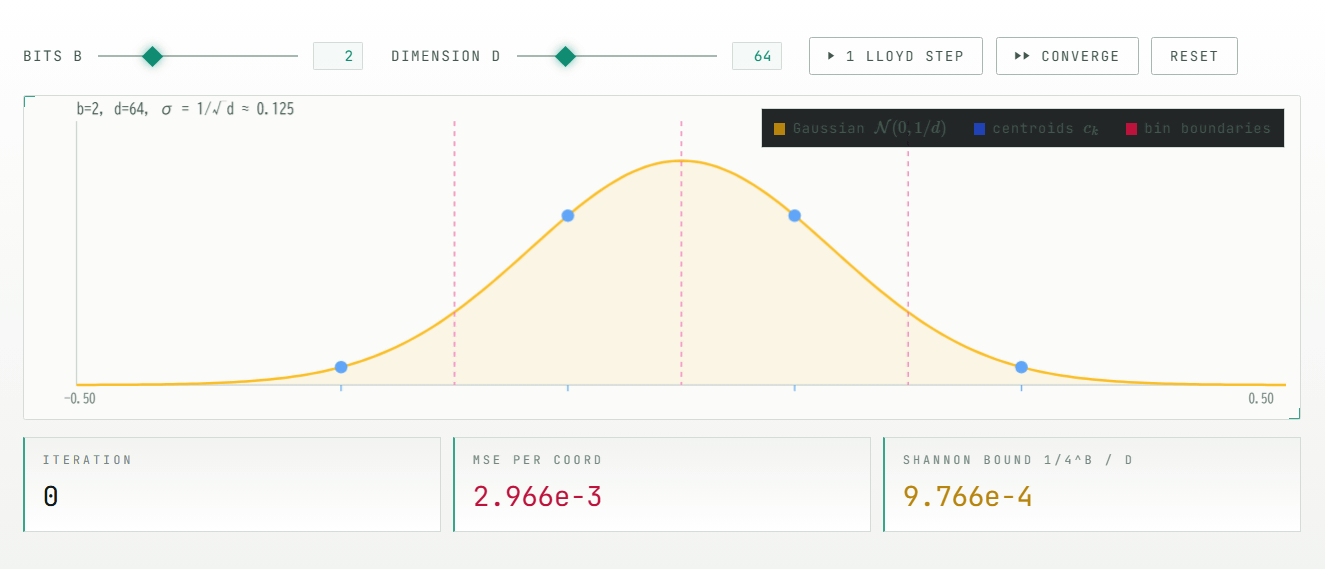
回転後の座標は似たような分布になるため、TurboQuantでは入力ごとにスケールやゼロ点を保存する必要がありません。あらかじめ作っておいた共通のコードブック、つまり代表値の表を使って、各座標を丸めればよいからです。この「追加メタデータなしで使える」という点が、従来のブロックごとの量子化手法との大きな違いです。
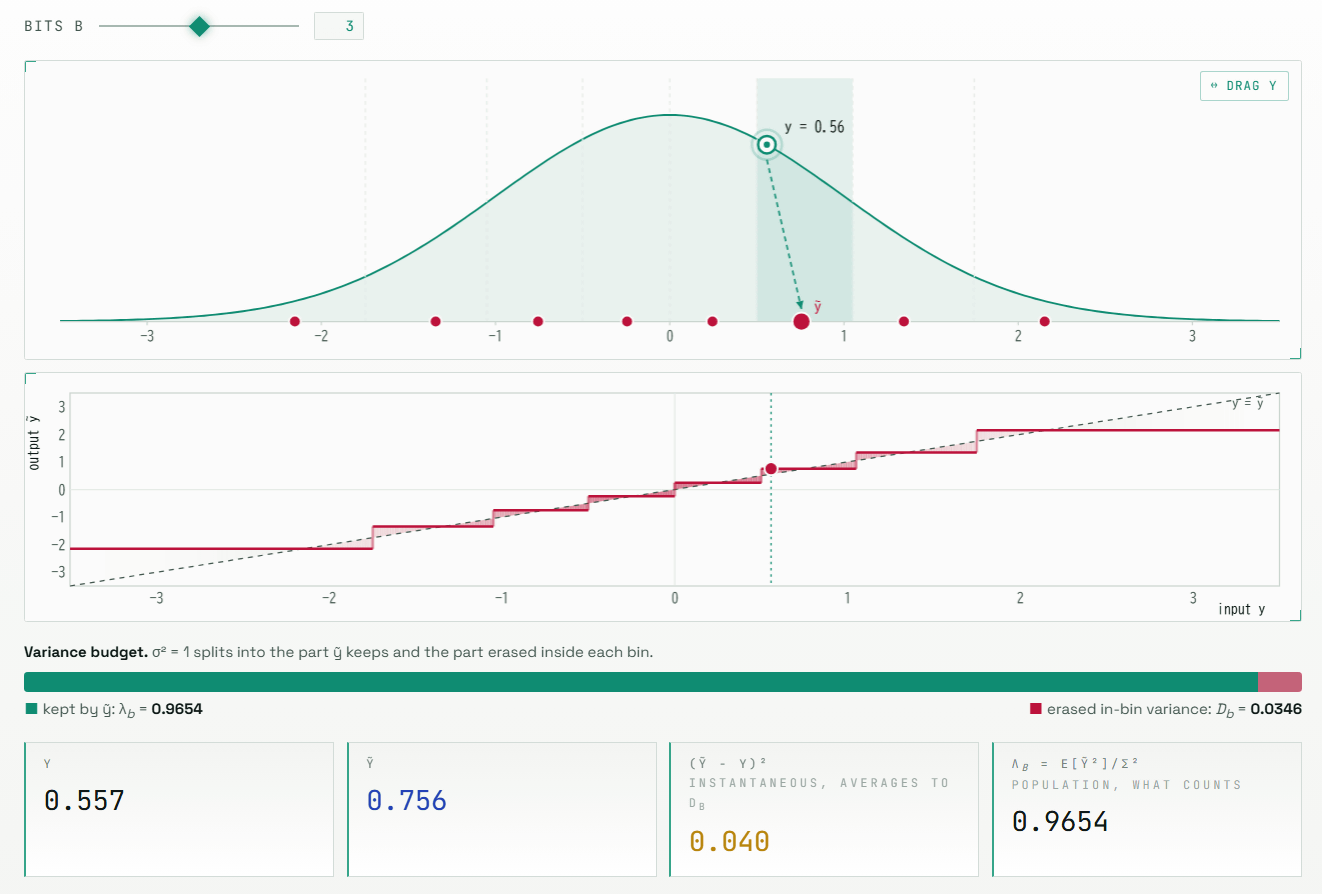
さらに、単に元のベクトルに近づけるだけではなく、attentionやベクトル検索で重要な「内積」が小さく見積もられる問題もあります。MSE(平均二乗誤差)を小さくする量子化では復元値が少しゼロ側に縮み、内積に偏りが出るため、TurboQuantでは「QJL」という補正でこの偏りを打ち消します。
「TurboQuant: A First-Principles Walkthrough」では、「普通の量子化はどこで失敗するのか」「なぜ回転が効果的なのか」「なぜ内積補正が必要なのか」といった問題を順番にたどることができます。論文や数式だけではつかみにくい高次元ベクトルの圧縮を、動く図で体験しながらゆっくりと理解することが可能です。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。