

ヨーロッパの研究機関や企業のコンソーシアムが、英語中心のAI開発に対抗しヨーロッパの言語的多様性を反映したAIの実現を目的としてEUの公式全24言語に加え、その他11言語をサポートする大規模言語モデル(LLM)「EuroLLM」を開発しオープンソースとして公開しています。
eurollm.io
https://eurollm.io/

◆EuroLLMでサポートされているEU公式24言語
・ブルガリア語
・クロアチア語
・チェコ語
・デンマーク語
・オランダ語
・英語
・エストニア語
・フィンランド語
・フランス語
・ドイツ語
・ギリシャ語
・ハンガリー語
・アイルランド語
・イタリア語
・ラトビア語
・リトアニア語
・マルタ語
・ポーランド語
・ポルトガル語
・ルーマニア語
・スロバキア語
・スロベニア語
・スペイン語
・スウェーデン語
◆EuroLLMでサポートされているその他11言語
・アラビア語
・カタロニア語
・中国語
・ガリシア語
・ヒンディー語
・日本語
・韓国語
・ノルウェー語
・ロシア語
・トルコ語
・ウクライナ語
A EuroHPC Success Story: Speaking Freely with EuroLLM – EuroHPC JU
https://www.eurohpc-ju.europa.eu/eurohpc-success-story-speaking-freely-eurollm_en
このプロジェクトには、Unbabel、リスボン工科大学、エディンバラ大学、パリ=サクレー大学など、ヨーロッパ各地の著名な研究機関や企業が参加しています。
開発チームは「ほとんどのLLMは英語中心であり、英語圏の文化を反映しがちです。私たちは、ヨーロッパの全言語で公平に高性能を発揮するモデルを目指しました」と述べています。
開発の大きな課題として、ギリシャ語のテキストは英語に比べて5~6倍のトークンを消費することがあり、利用コストの不平等につながっていました。この問題に対して、学習データにおける英語の割合を50%に抑え、他の言語にも十分なデータを割り当てることで解決を図っています。この学習システムにはEuroHPCのスーパーコンピュータ「MareNostrum 5」が活用されたとのこと。
Hacker Newsのコミュニティでは、「ヨーロッパの納税者が出資した研究モデルとして重要」「言語の多様性を守る素晴らしいイニシアチブだ」といった肯定的な意見が見られる一方で「既存の商用モデルと比較して性能面でどこまで競争力があるか」といった現実的な課題を指摘する声もあります。LifeArchitect.aiによると、様々な分野のタスクに対する言語モデルの性能を評価するためのベンチマーク指標であるMMLUの値が52.5と他の同クラスのモデルと比較して10ポイント程度劣る結果となっています。
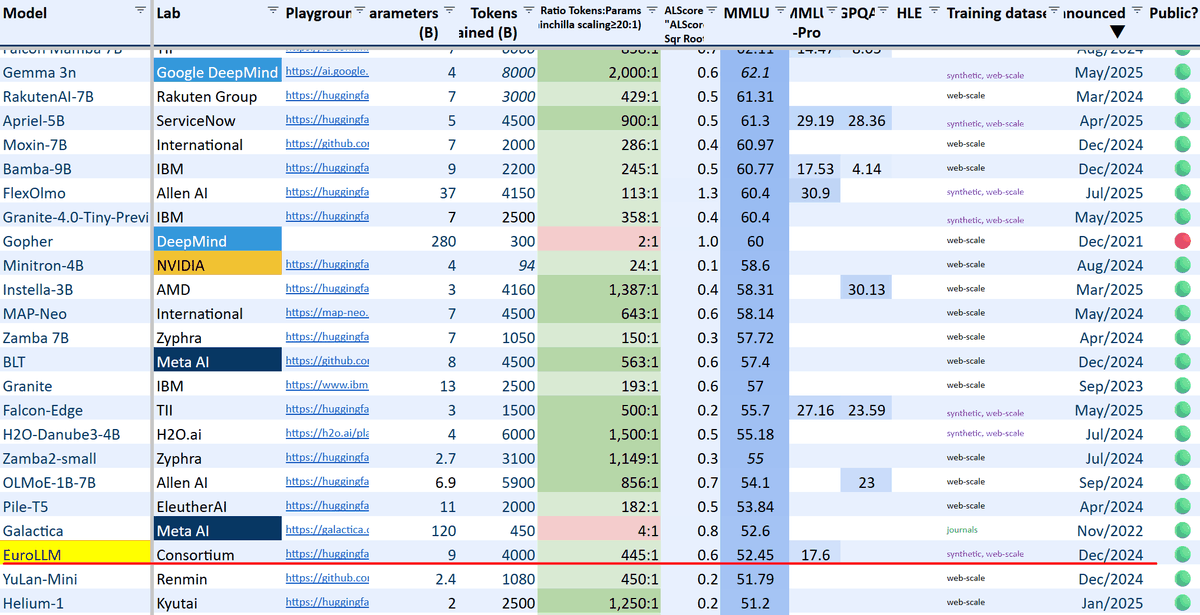
EuroLLMは、現在1.7Bと9Bのパラメータを持つモデルが公開されており、今後はさらに高性能な22Bモデルや画像・音声を扱うマルチモーダルモデルのリリースも計画されています。
EuroLLM-9B · Hugging Face
https://huggingface.co/utter-project/EuroLLM-9B
実際にEuroLLMを試してみます。WindowsのLM Studioでモデルをダウンロードします。
「おはようを24言語で訳すとどうなりますか」という簡単なプロンプトを英語で質問してみたところ、各言語に翻訳された回答が得られました。

その他11言語についても質問したところ回答を得ることができました。

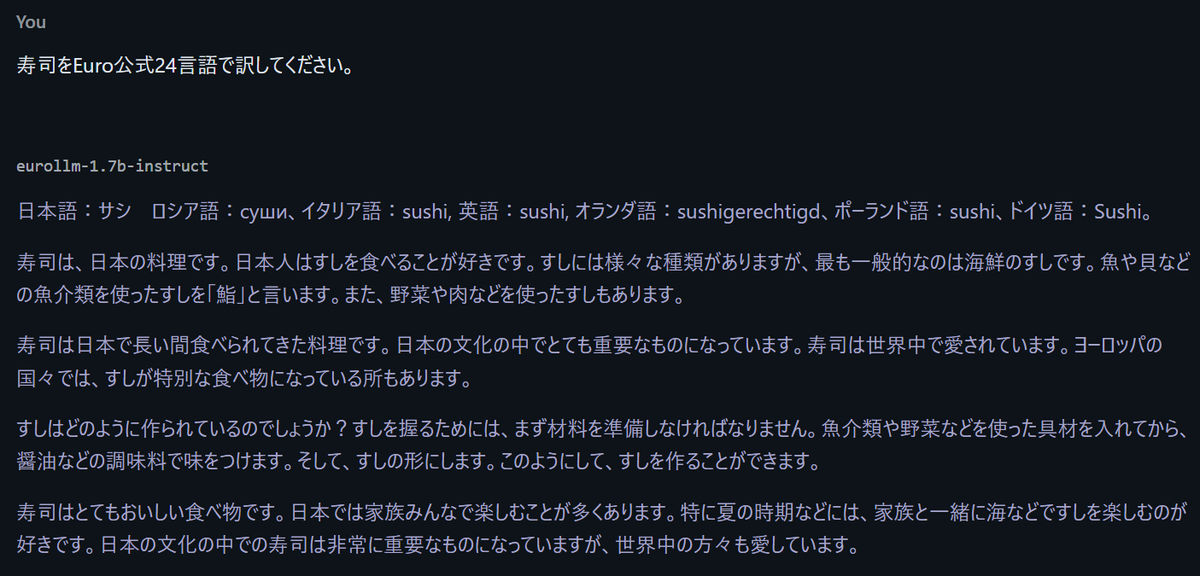
次に、日本語で寿司について同じ質問をしてみました。「日本語: サシ」といった間違いも見られ、回答としては不十分でしたが、EU圏でも寿司が認知されていることは分かりました。
開発チームは「私たちの目標は、ヨーロッパのイノベーションを加速させることです。誰もがこのヨーロッパ製のLLMを使い、その上で新しいものを構築する機会を提供したいと考えています。将来的にはテキストだけでなく、画像や音声にも対応した、より包括的なモデルの開発を進めていきます」と述べています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。