

NVIDIAが2025年8月18日、TransformerアーキテクチャとMambaアーキテクチャを組み合わせたハイブリッド推論モデル「Nemotron Nano 2」をリリースしました。
NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1 – NVIDIA ADLR
https://research.nvidia.com/labs/adlr/NVIDIA-Nemotron-Nano-2/
Nvidia’s open Nemotron-Nano-9B-v2 has toggle on/off reasoning | VentureBeat
https://venturebeat.com/ai/nvidia-releases-a-new-small-open-model-nemotron-nano-9b-v2-with-toggle-on-off-reasoning/
Nemotron Nano 2は従来の言語モデルで広く使用されているTransformerアーキテクチャと、2023年12月に発表されたMambaアーキテクチャのハイブリッドモデルである「Nemotron-H」をベースにしています。
Transformerアーキテクチャは現在主流の大規模言語モデルのほとんどで利用されていますが、シーケンスが長くなるにつれてメモリと計算コストが高くなるという問題があります。一方、MambaアーキテクチャはState Space Model(SSM:状態空間モデル)を組み込むことで、シーケンスの長さに対するメモリや計算コストの問題を避けることが可能。そのため、TransformerアーキテクチャとMambaアーキテクチャを組み合わせることで、長いコンテキストでもより高いスループットと同等の精度を達成できるとのこと。
Hugging Faceでは、刈り込み前のベースモデルであるNemotron-Nano-12B-v2-Base、刈り込み後のベースモデルであるNemotron-Nano-9B-v2-Base、アライメントおよび刈り込み後のモデルであるNemotron-Nano-9B-v2が公開されています。
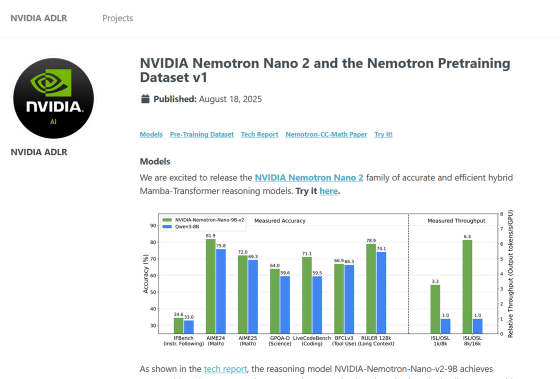
単一のNVIDIA A10G GPUで実行できるNemotron-Nano-9B-v2は、複雑な推論ベンチマークにおいて同規模の主要オープンモデルであるQwen3-8Bと同等以上の精度を達成し、最大6倍のスループットを実現したとNVIDIAは報告しています。
以下のグラフは緑色の棒がNemotron-Nano-9B-v2、青色の棒がQwen3-8Bを表しており、縦軸が各ベンチマークに対するモデルの精度です。数学や科学、コーディングなどを含むベンチマークで、Nemotron-Nano-9B-v2の方が優れたパフォーマンスを発揮していることがわかります。
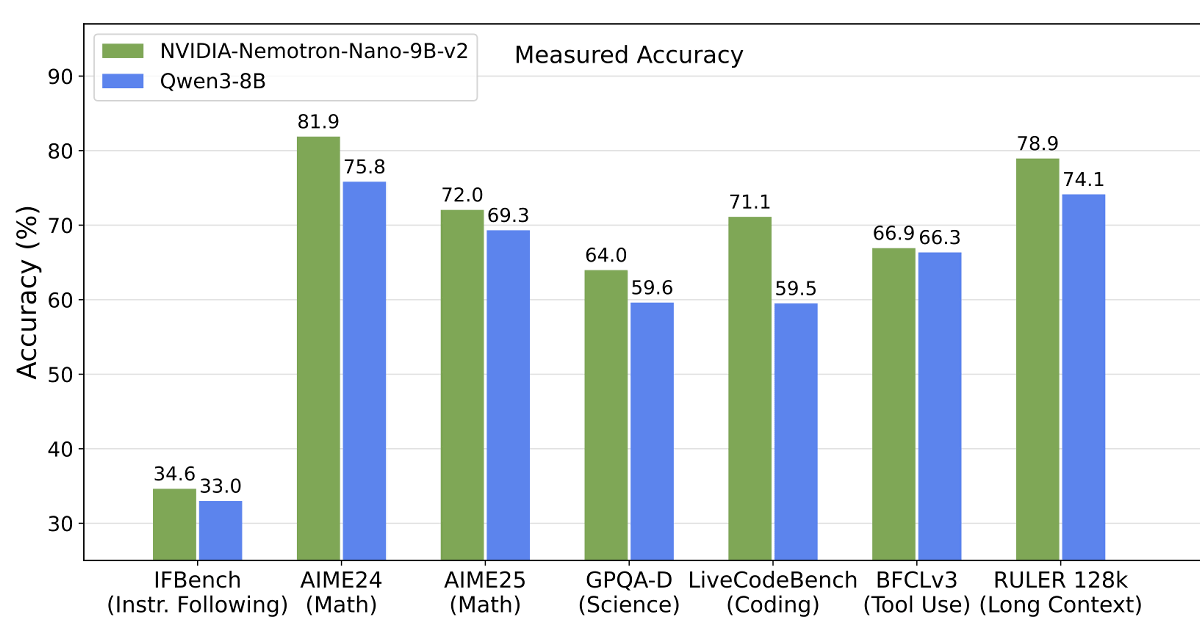
また、出力シーケンス長(OSL)に対する入力シーケンス長(ISL)ごとのスループットを表した以下のグラフを見ると、Nemotron-Nano-9B-v2がより優れたスループットを達成しており、両モデルの差はシーケンス長が増えるほど大きくなっていることが確認できます。
Nemotron Nano 2はNVIDIA独自のオープンモデルライセンスであるNVIDIA Open Model Licenseでリリースされており、開発者はモデルを商用利用可能である上に、派生モデルを作成・配布することもできます。なお、開発者には適切な代替手段なしで組み込みの安全メカニズムを回避しないことや、再配布時に帰属表示を行うことなどの条件を順守することが求められています。
NVIDIA Open Models License
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。