

Googleが次世代推論AI「Gemini 2.5」シリーズを発表し、その第1弾としてマルチモーダルモデルであるGemini 2.5 Pro Experimentalをリリースすることを明らかにしました。Googleは、強力な推論機能とコード機能を備えたGemini 2.5 Pro Experimentalが「最もインテリジェントなモデル」であるとアピールしています。
Gemini 2.5: Our newest Gemini model with thinking
https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/
従来の大規模言語モデルは数学的な問題やコーディングなど、論理力を問われる複雑なタスクを苦手としていました。しかし、推論モデルは答えを出す前に追加の計算能力と時間をかけて事実確認と問題の推論を行うことで、数学的な問題やコーディングなどでも高い精度の出力を可能とします。
OpenAIが2024年9月に初のAI推論モデルとなる「OpenAI o1」を発表して以来、AI企業は自社のモデルでOpenAI o1に匹敵するかそれを上回る推論能力を獲得しようと競い合ってきました。記事作成時点でOpenAI以外にもAnthropicやxAI、DeepSeekなどが推論モデルを開発しています。
Googleもこれまでに推論モデルを開発しており、2024年12月に初の推論モデルとなる「Gemini 2.0 Flash Thinking」をリリースしました。これは、マルチモーダルモデルであるGemini 2.0 Flashに「思考プロセスを生成する機能」を追加したモデルです。
今回発表されたGemini 2.5シリーズは、このGemini 2.0 Flash Thinkingよりも推論能力とコーディング能力が強化されているとGoogleは述べています。
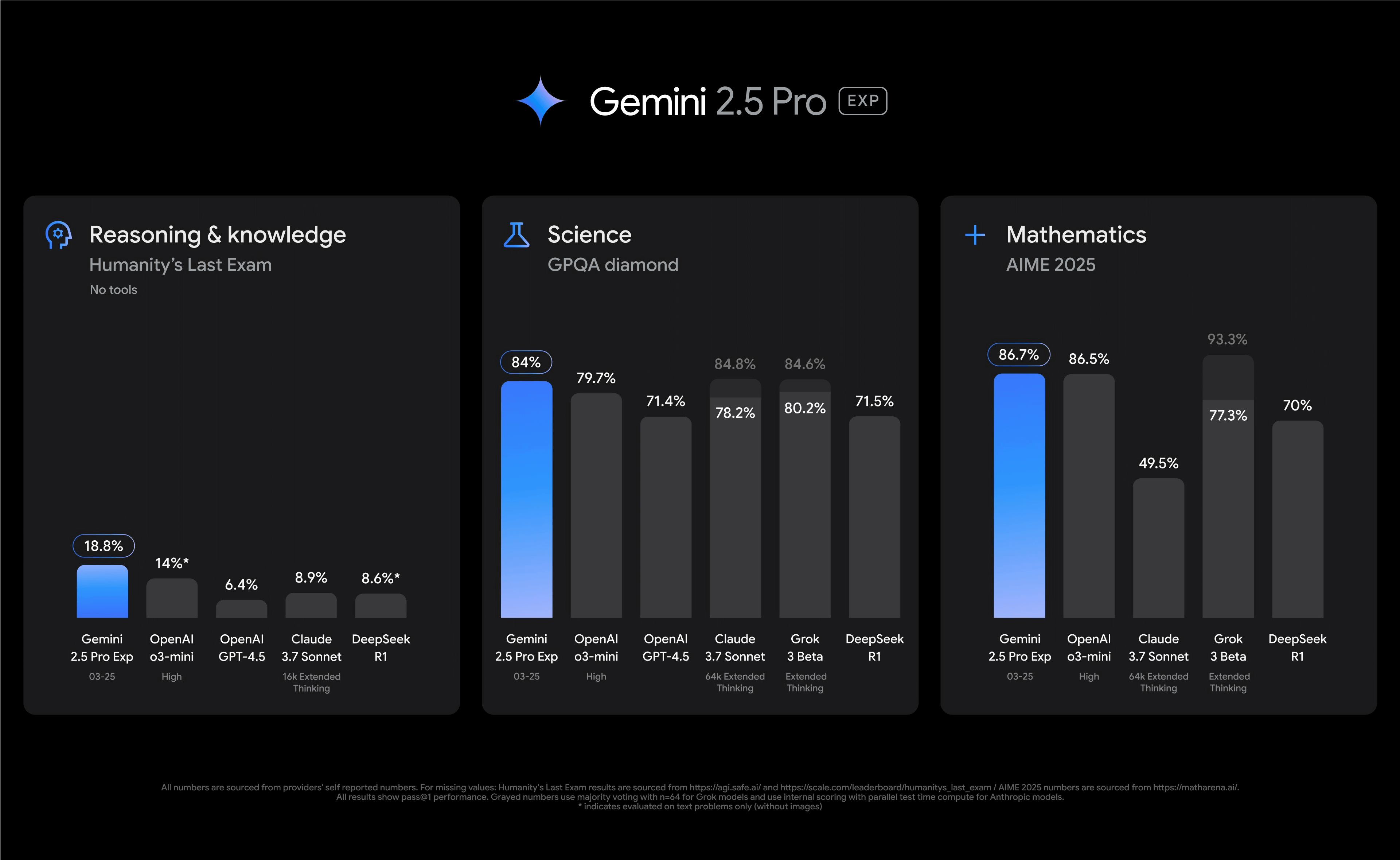
Googleが公開しているベンチマーク結果をまとめた図が以下。「Reasoning&knowledge(推論と知識)」「Science(科学)」「Mathematics(数学)」で、OpenAI o3-miniやOpenAI GPT-4.5、Claude 3.7 Sonnet、Grok 3 Beta、DeepSeek-R1と比較してトップクラスのスコアを記録しました。
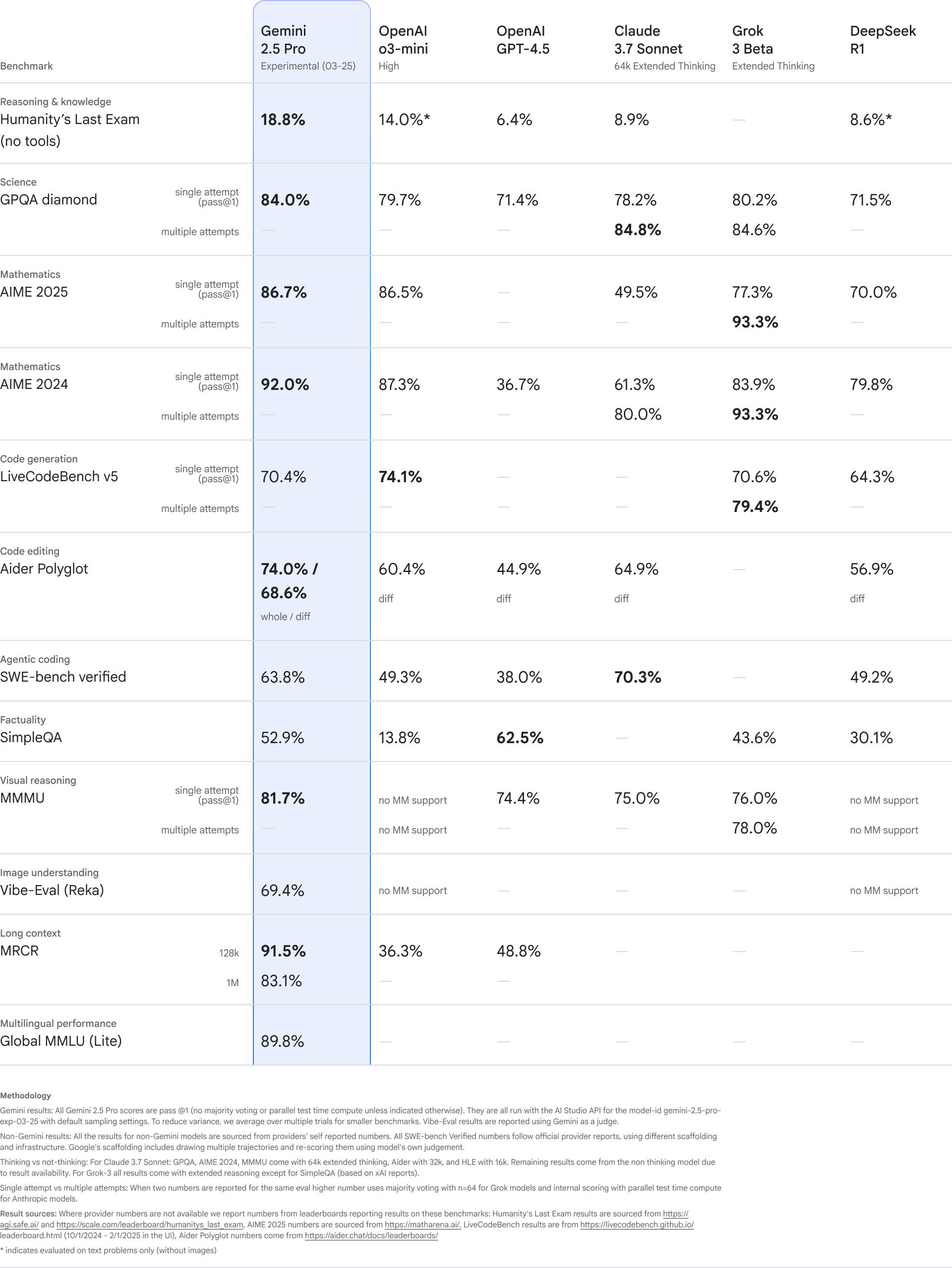
また、Googleによると、コード編集を測定する評価ツール「Aider Polyglot」において、Gemini 2.5 Pro Experimentalは 68.6% のスコアを獲得し、OpenAI o3-miniやClaude 3.7 Sonnet、DeepSeek-R1のスコアを上回ったとのこと。さらに、Gemini 2.5 Pro ExperimentalはAI向けのソフトウェア開発ベンチマーク「SWE-Bench Verified」で63.8%のスコアを獲得し、OpenAI o3-miniやDeepSeek-R1のスコアを上回ったとのこと。ただし、70.3%のスコアを示したAnthropicのClaude 3.7 Sonnetの方がGemini 2.5 Pro Experimentalよりもやや上回る結果となりました。
Googleは、実際にGemini 2.5 Pro Experimentalに1行のプロンプトを入力して簡単なゲームを生成させる様子を、以下のムービーで公開しています。
Gemini 2.5: Create your own dinosaur game from a single line prompt – YouTube

Gemini 2.5 Proは記事作成時点で入力トークン100万・出力トークン6万4000で、開発者プラットフォームであるGoogle AI Studioで利用可能になるほか、月額2900円の有料プラン「Gemini Advanced」加入者であればGeminiアプリでも利用可能になるとのこと。APIの利用料については記事作成時点では不明で、近日中に詳細を発表するとGoogleは述べています。
さまざまなAIを検証している開発者のサイモン・ウィリソン氏は独自に検証を行った結果、「試用したばかりでまだ少しかじった程度」と前置きしながらも、Gemini 2.5 Proの文章解釈・画像認識・音声認識の精度が高かったと評価し、「Gemini 2.5 Proは非常に強力な新モデルです」と自身のブログで論じました。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。