

Google、OpenAI、Perplexity、DeepSeek、xAIなどのAI企業がそれぞれ独自の「Deep Research」という機能を実装しています。これらの「Deep Research」は一体何が違うのかについて、機械学習エンジニアのハン・リー氏が解説しています。
The Differences between Deep Research, Deep Research, and Deep Research
https://leehanchung.github.io/blogs/2025/02/26/deep-research/
2024年12月、Googleはユーザーの指示に従って課題解決に役立つ情報をインターネット上から収集してくれる情報整理AI機能の「Deep Research」を発表しました。
Googleが人間の代わりに情報収集してくれるAI機能「Deep Research」をリリース、ウェブ上の膨大な情報をまとめてレポートを提出してくれる – GIGAZINE

2025年2月、OpenAIがChatGPTにオンライン上の情報を収集させる「Deep research」という機能を発表。
OpenAIがChatGPTにオンライン上の情報を収集させる「Deep research」機能を搭載すると発表 – GIGAZINE
Perplexityもユーザーの代わりに詳細な調査と分析を実施する「Deep Research」機能を発表しています。
他にも、DeepSeek、Qwen、xAIといったAI企業もチャットボット向けの検索機能として「Deep Research」を展開しており、これらのDeep Research機能を模倣したオープンソース実装がGitHub上には数十件も乱立しているそうです。
「Deep Research」は、ユーザークエリを受け取り、大規模言語モデル(LLM)をエージェントとして使用して情報を反復的に検索および分析し、出力として詳細なレポートを生成するレポート生成システムです。自然言語処理(NLP)用語において、これは「レポート生成(report generation)」と呼ばれています。
この「レポート生成」は、ChatGPTが2025年2月に「Deep research」機能を発表してから業界で注目を集めていますが、AIエンジニアリングが始まった2023年初頭時点でリー氏は個人的に実験したことのあるシステムだったそうです。
なぜこれまでレポート生成が注目されなかったかについて、リー氏は「GPT-3.5のような初期のLLMではレポート生成を依頼することは現実的ではなかったため」と説明しています。当時のLLMではレポート生成が現実的ではなかったため、代わりに「複数のLLMを呼び出して連結する」という複合パターンが採用されました。
複合パターンのプロセスは以下の通り。複合パターンを使用している代表例がGPT Researcherです。複合パターンは「出力が主観的な目視に依存している」ため、レポートの品質に一貫性がないという問題を抱えています。
1:ユーザークエリを分解し、レポートのアウトラインを作成。
2:各セクションについて、検索エンジンやナレッジベースから関連情報を取得し、要約。
3:LLMを使用してセクションを統合したレポートを作成。
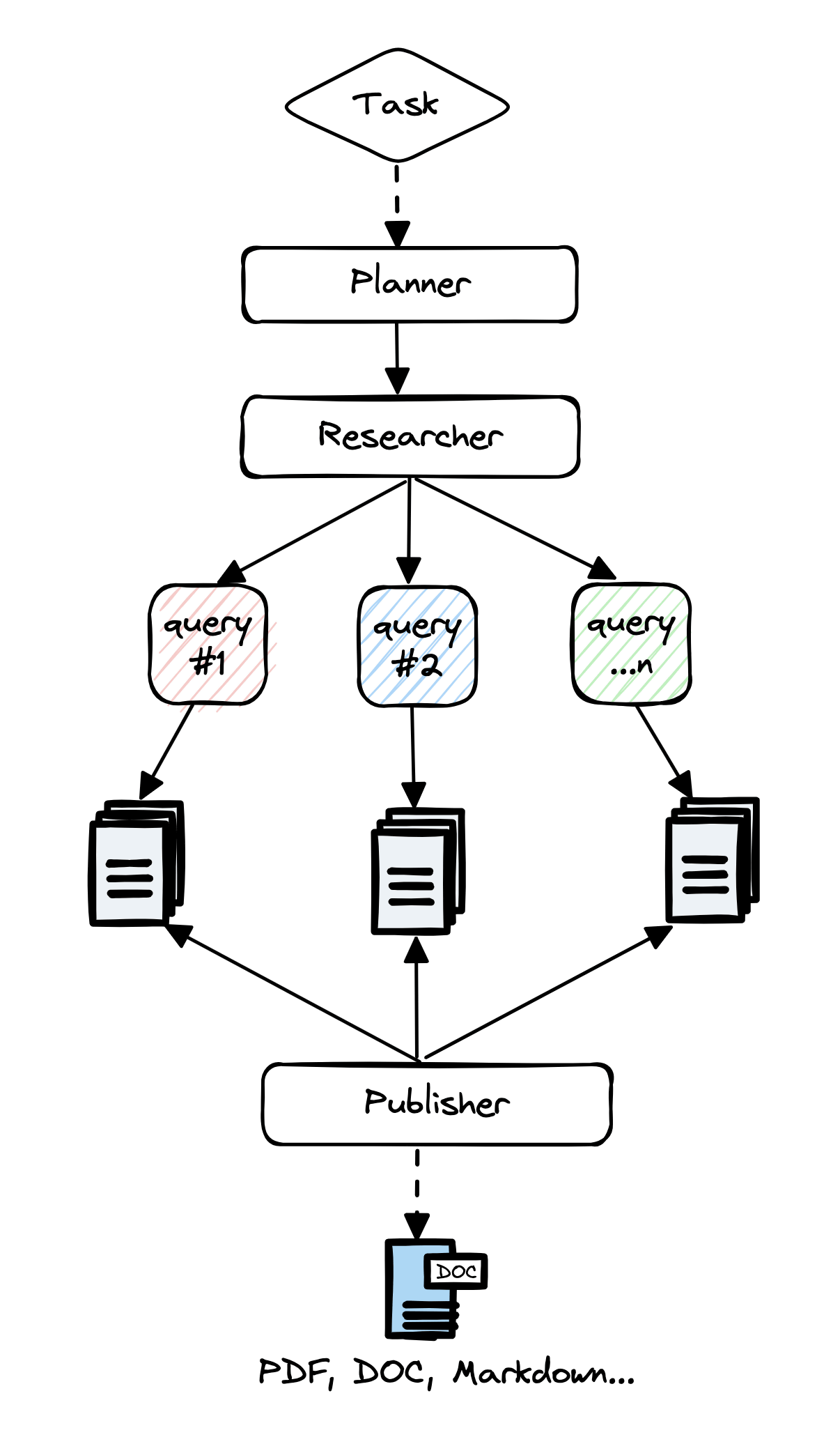
複合パターンで生成されるレポートの品質を高めるため、エンジニアはDAGアプローチに複雑さを加えました。単一のパスプロセスではなく、Reflexionや自己Reflexionなどの構造パターンを導入し、LLMが独自の出力を確認して改良しています。これにより、単純なDAGがFSMに変換され、LLMが状態遷移を部分的にガイドできるようになりました。しかし、この方法でもすべてのプロンプトが手作業で作成され、評価は主観的なものになるという問題を抱えています。
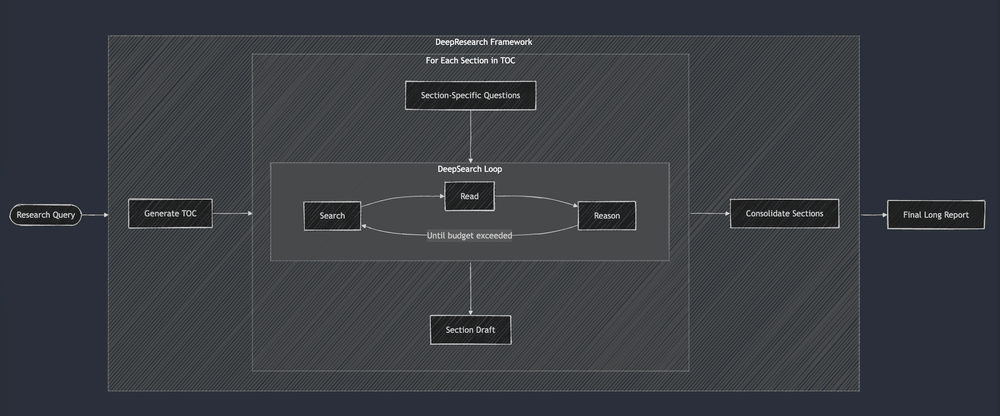
その後登場したのが、スタンフォード大学のSTORMです。STORMはDSPyを使用して、システムをエンドツーエンドで最適化することで、Wikipediaの記事に匹敵する品質のレポートを生成可能にしました。
STORM
https://storm.genie.stanford.edu/
上記の進歩により、大規模な推論モデルがDeep Research機能にとって魅力的な選択肢となってきたとリー氏は説明しています。なお、OpenAIはDeep Researchで使用するモデルのトレーニング方法について、「LLMを審査員として使用し、評価基準を使用して出力を評価している」と説明しています。
一方で、GoogleとPerplexityは「Deep Research」機能において、モデルやシステムを最適化した方法や実質的な定量的評価に関する文献は公開していません。しかし、Googleのプロダクトマネージャーは、ポッドキャストのインタビューで「特別なアクセス権を持っています。ほぼ同じモデル(Gemini 1.5)です。もちろん、トレーニング後の作業は独自に行なっています」と解説しています。一方、xAIの「Deep Research」機能はレポート生成に優れていますが、2回の反復を超えて検索することはないそうです。
リー氏は各AIの「Deep Research」機能を評価するマップを作成しています。縦軸は検索の深さを測定するもので、「サービスが以前の調査結果に基づいて追加情報を収集するために実行する反復サイクルの数」で定義されています。横軸はトレーニングのレベルを評価しており、左に行けば行くほど手動で調整されており、右に行けば行くほど機械学習技術を活用した完全にトレーニングされたシステムであることを表します。

この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。