

NVIDIAが高速かつ高精度なオブジェクト検出が可能なAIモデル「LocateAnything」を公開しました。LocateAnythingは写真やスクリーンショットに含まれるオブジェクトを高速検出することが可能で、ロボットやPC自動操作などの分野で活用されることが期待されています。
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
https://research.nvidia.com/labs/lpr/locate-anything/?linkId=100000424057485
LocateAnythingはオブジェクト検出の速さを特徴とするモデルです。以下のポストに埋め込まれた動画を再生すると非常に高速に処理を実行できることが分かります。
This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to… pic.twitter.com/2OGaQnUCnX
— NVIDIA AI (@NVIDIAAI) May 28, 2026
LocateAnythingの学習データには写真だけでなく「アプリケーションのスクリーンショット」や「文書」も含まれており、アプリケーションのUI要素検出や文字検出能力も有しています。
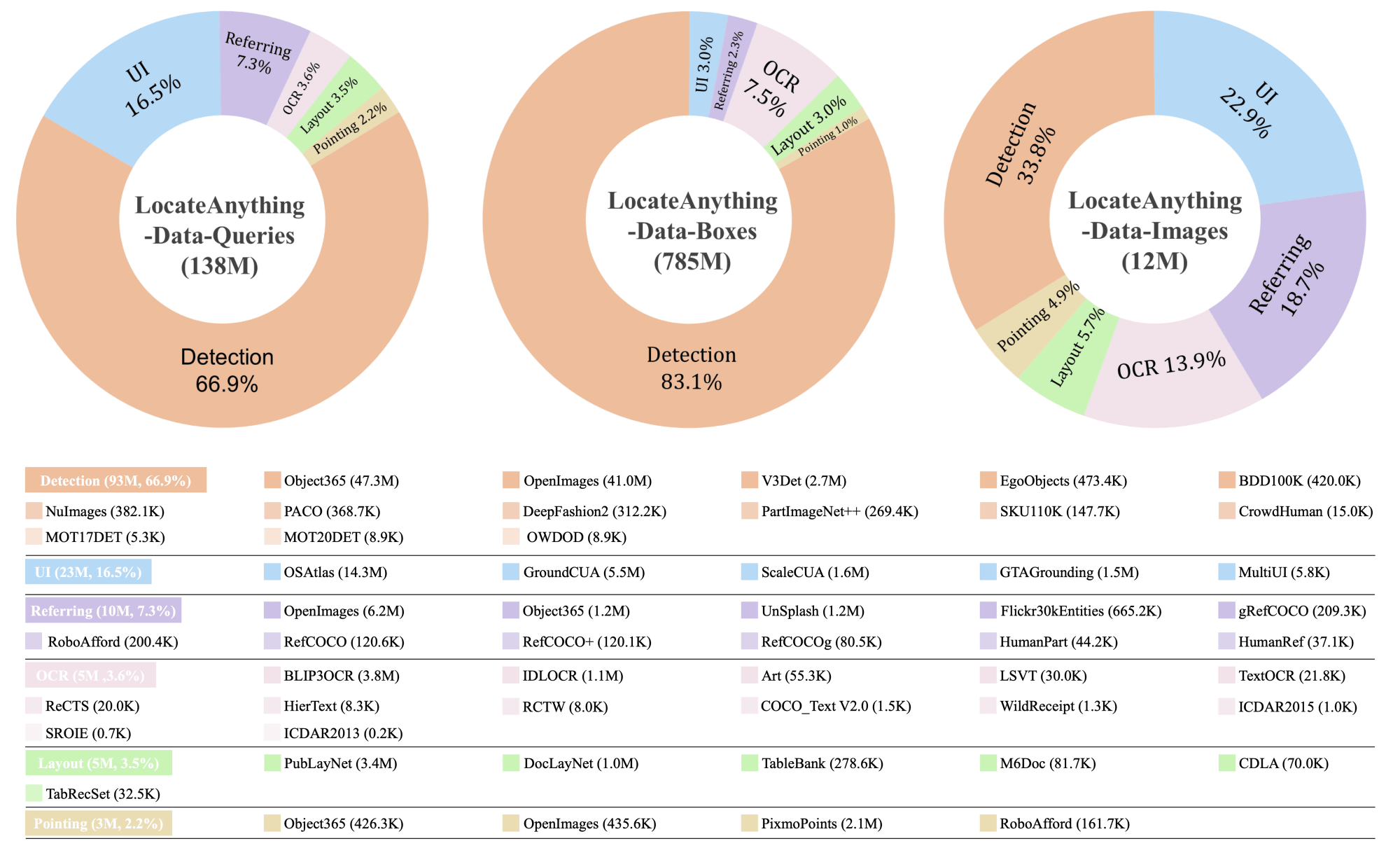
LocateAnythingの性能をQwen3-VLやRex-Omniと比較した結果が以下。Qwen3-VLとRex-Omniは「建物の窓の1つずつ個別に認識する」「木材を1つずつ認識する」といった処理が苦手ですが、LocateAnythingは正確に実行できています。

文字認識もQwen3-VLとRex-Omniとくらべて高精度に実行可能。

実際にLocateAnythingを使えるデモアプリが用意されているので使ってみます。
LocateAnything – a Hugging Face Space by nvidia
https://huggingface.co/spaces/nvidia/LocateAnything
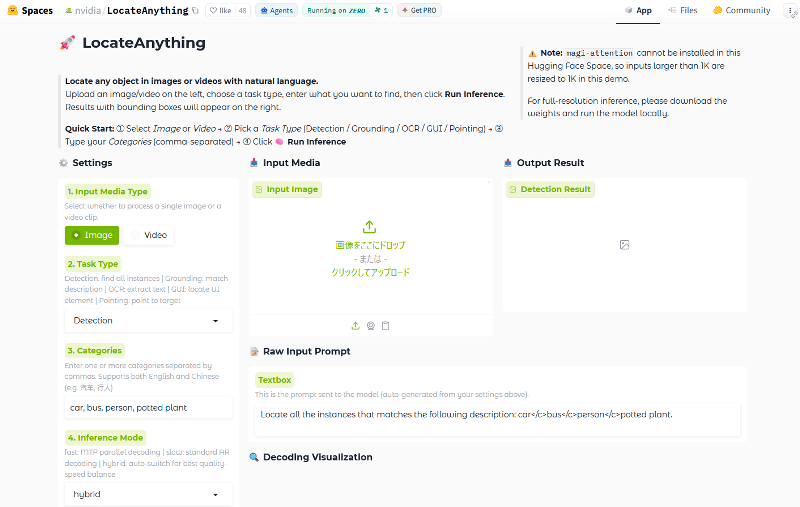
デモアプリに画像を入力して、検出したいオブジェクトの名前を入力してから「Run Inference」をクリック。今回は「video-game(ゲーム)」と入力しました。
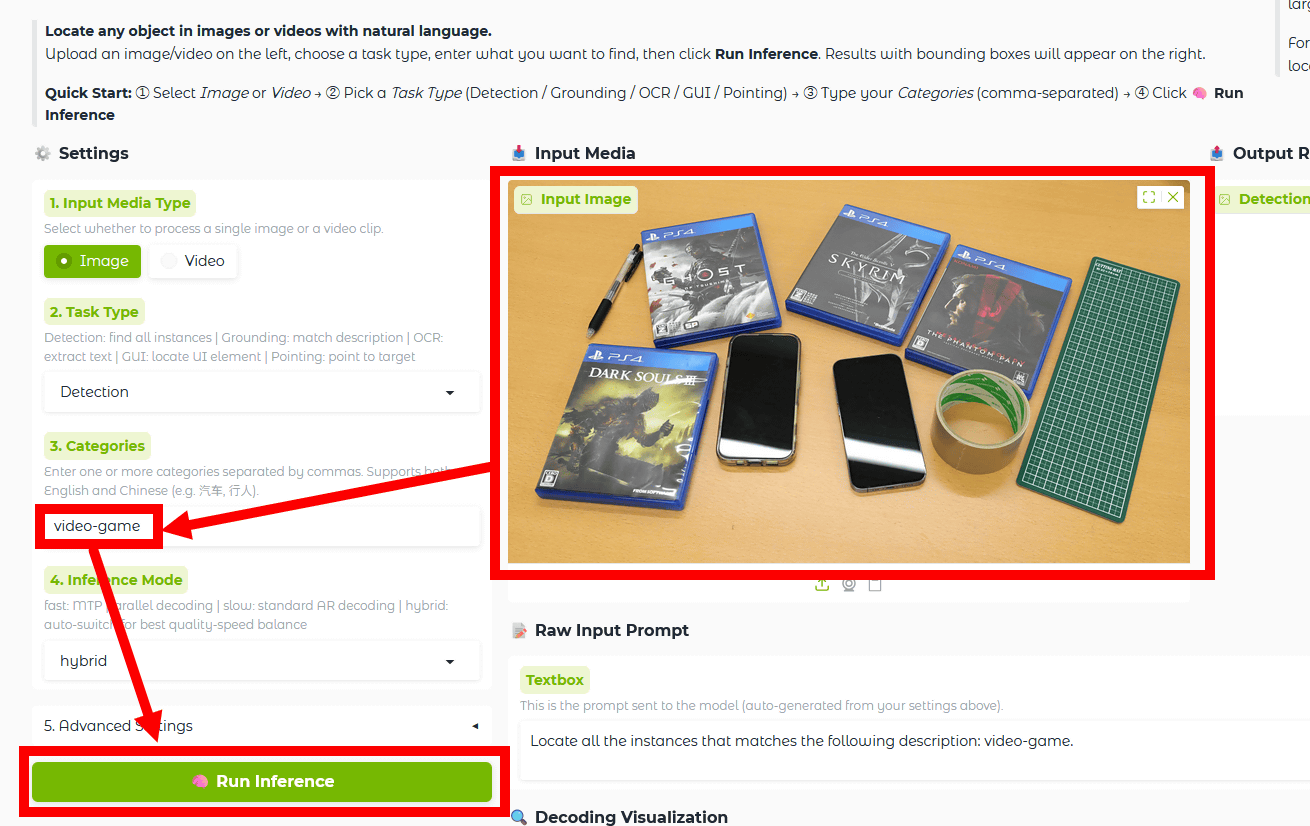
検出結果が以下。写真内に含まれるすべてのゲームソフトパッケージが認識されています。

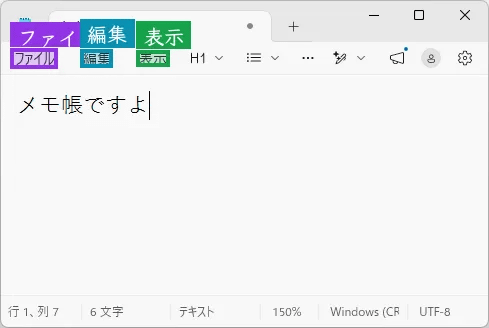
同時に複数の要素を検出することもできます。メモ帳のスクリーンショットを入力して「ファイル」「編集」「表示」の3つを検出するように指示してみました。
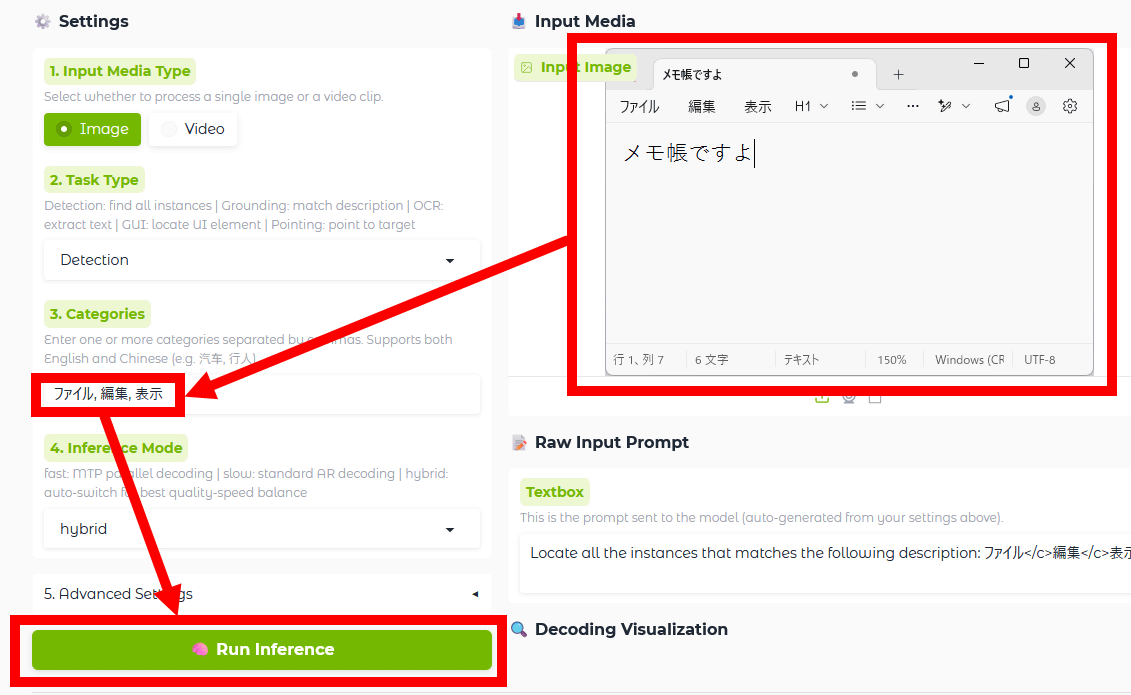
結果が以下。正しく検出できています。
LocateAnythingはオープンモデルとして公開されており、以下のリンク先からダウンロード可能です。
nvidia/LocateAnything-3B · Hugging Face
https://huggingface.co/nvidia/LocateAnything-3B
この記事のタイトルとURLをコピーする
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。