
アメリカ商務省傘下の科学研究機関であるアメリカ国立標準技術研究所(NIST)が、商用AIシステムの可用性及び安全性を評価する人工知能標準化・イノベーションセンター(CAISI)によるDeepSeek V4 Proの評価レポートを公開しました。CAISIによるとDeepSeek V4 Proは「最新AIに比べて約8カ月遅れている」とのことです。
CAISI Evaluation of DeepSeek V4 Pro | NIST
https://www.nist.gov/news-events/news/2026/05/caisi-evaluation-deepseek-v4-pro
中国のAI企業であるDeepSeekは、2026年4月末に最新AIモデルの「DeepSeek-V4」を発表しました。DeepSeek-V4にはDeepSeek-V4-ProとDeepSeek-V4-Flashという2つのモデルがあり、DeepSeek-V4-Proは総パラメーター数1兆6000億のハイスペックモデルです。
ついに「DeepSeek-V4」が登場、Claude Opus 4.6を超える性能のオープンモデル – GIGAZINE
CAISIはオープンウェイトモデルであるDeepSeek V4 Proの評価を実施し、「DeepSeek V4 Proは最先端AIに比べて約8カ月遅れている」と指摘しました。
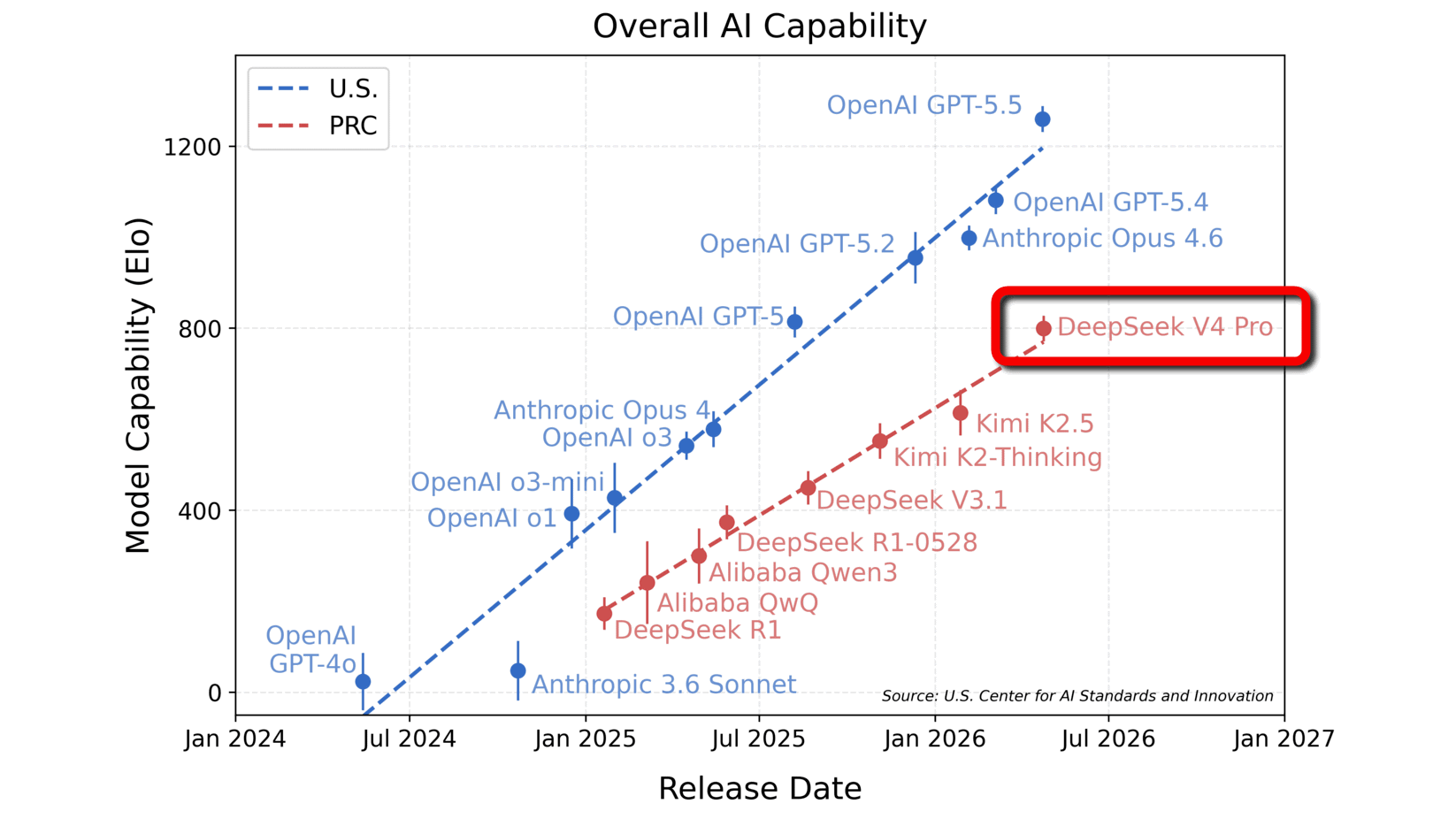
以下のグラフは既存の公開AIを、5つの領域を網羅する一連のベンチマークに基づいて比較したものです。グラフの縦軸はベンチマークの総合評価を示しており、高いほど優れたAIであることを示します。そして、横軸は各AIモデルがリリースされたタイミングを示しています。アメリカ製のAIが青色、中国製のAIが赤色で示されており、2026年4月に公開されたDeepSeek V4 Proは、OpenAIが2025年8月、つまり8カ月前にリリースしたGPT-5と同等のパフォーマンスを示したことが示されています。
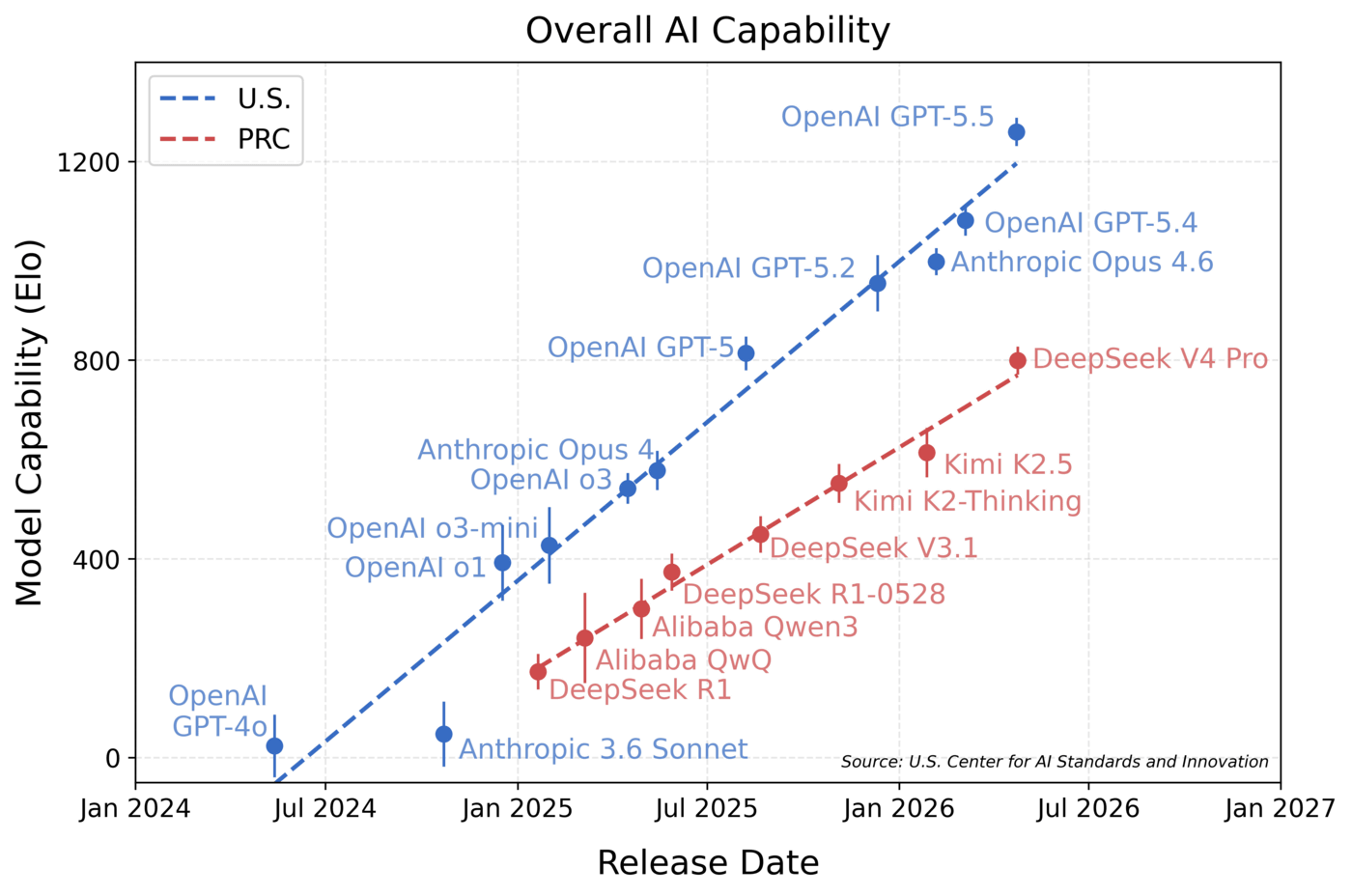
DeepSeek V4 Proはこれまで中国製AIとして最も高いスコアを出してきたKimi K2.5よりも200ポイントほど高いスコアを記録しています。CAISIが実施した5つの領域を網羅するベンチマークでは、総合スコアが200ポイント高いということは、特定のタスクを解決する確率が3倍になることを意味するそうです。
なお、CAISIの評価は項目応答理論(IRT)からヒントを得たアプローチを採用しており、サイバー・ソフトウェアエンジニアリング・自然科学・抽象推論・数学という5つの分野にわたる9つのベンチマークテストを実施して算出されています。
実施されたベンチマークテストは以下の通り。
◆サイバー関連
CTF-Archive-Diamond:システムを破壊し脆弱性を突く実践的なハッキング能力を測る非公開ベンチマーク
◆ソフトウェアエンジニアリング関連
SWE-Bench Verified:AIのプログラミング能力を測るベンチマークテスト
PortBench:AIのソフトウェア移植能力を測る非公開ベンチマーク
◆自然科学関連
FrontierScience:AIの研究レベルの科学的推論能力を測るベンチマーク
GPQA-Diamond:AIの専門家クラスの科学知識および推論能力を測るベンチマーク
◆抽象推論関連
ARC-AGI-2 semi-private:汎用人工知能(AGI)向けのベンチマークを推進するARC Prize Foundationが公開しているベンチマークテストARC-AGI-2のうち、半非公開の評価セット
◆数学関連
OTIS-AIME-2025:数学オリンピック関連の超難問を使ったAI数学推論ベンチマーク
PUMaC 2024:大学生向け数学コンテストであるPUMaCの2024年大会の問題
SMT 2025:AIの数学推論能力を測るためのベンチマークテスト
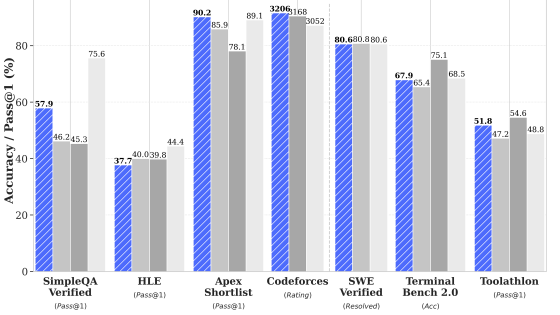
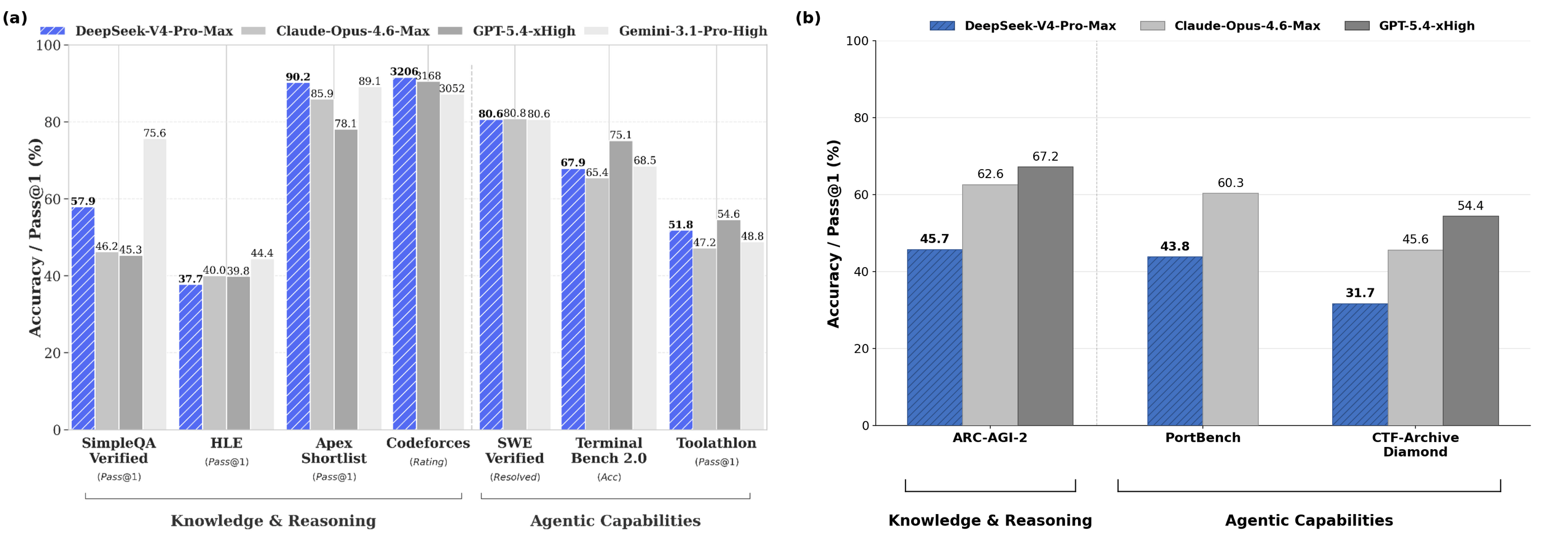
開発元であるDeepSeekはCAISIがDeepSeek V4 Proでベンチマークテストを実施して得たスコアよりも高いスコアを自己申告していたそうです。
以下のグラフの(a)がDeepSeekが公開したベンチマークテストの結果で、(b)がCAISIが実施したベンチマークテストの結果。DeepSeekが自己申告したベンチマークテストのスコアの場合、DeepSeek V4 Proは2026年3月(2カ月前)にリリースされたClaude Opus 4.6やGPT-5.4と同等の性能ですが、CAISIが実施したベンチマークテストの結果では2025年8月(8カ月前)にリリースされたGPT-5と同等のスコアしか得られませんでした。
一方、CAISIはDeepSeek V4 Proについて「同等の性能を持つ他のAIモデルよりもコスト効率に優れている」と評価しています。
アメリカ製AIのうち最もコスト効率に優れているのは、OpenAIのGPT-5.4 mini(青色)です。このモデルと比較しても、DeepSeek V4 Pro(赤色)は7つのベンチマークテストのうち5つでGPT-5.4 miniよりもコスト効率が優れていることが示されています。7つのベンチマークテスト全体で比較すると、DeepSeek V4 ProはGPT-5.4 miniよりもコスト効率が41~53%も優れていました。
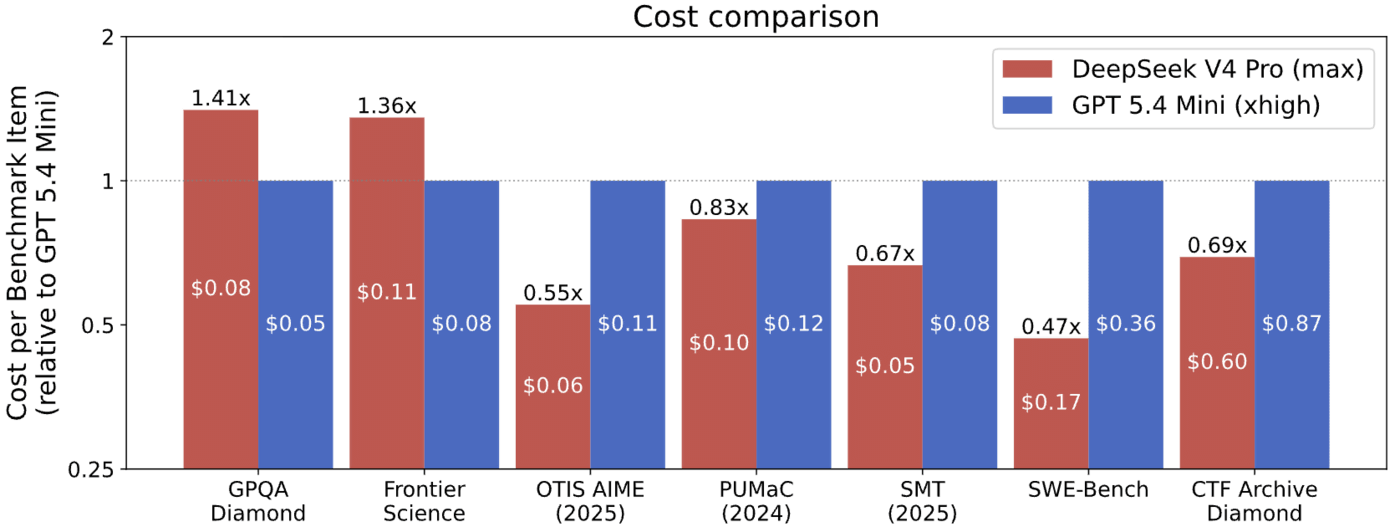
開発者報告によるDeepSeek V4 Proのトークン価格は入力トークンコスト(キャッシュなし)が100万トークン当たり1.74ドル(約270円)、入力トークンコスト(キャッシュあり)が100万トークン当たり0.0145ドル(約2.3円)、出力トークンコストが100万トークン当たり3.48ドル(約550円)です。これに対して、GPT-5.4 miniは入力トークンコスト(キャッシュなし)が100万トークン当たり0.75ドル(約120円)、入力トークンコスト(キャッシュあり)が100万トークン当たり0.075ドル(約12円)、出力トークンコストが100万トークン当たり4.50ドル(約710円)です。
なお、コスト効率の比較においてPortBenchとARC-AGI-2 semi-privateという2つのベンチマークテストが利用されていない理由について、CAISIは「PortBenchはCAISIのコスト比較手法でまだサポートされていない」「ARC-AGI-2はGPT-5.4 miniの評価において技術的な問題があった」と説明しています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。