

就職活動でAIを使って履歴書を整える人がいる一方で、企業側も履歴書のスクリーニングにAIを使うケースが増えています。こうした「AIが書いた履歴書をAIが評価する」状況について、メリーランド大学、シンガポール国立大学、オハイオ州立大学の研究チームが調べたところ、評価役のAIは自分と同じAIモデルが書いた履歴書を高く評価しやすいことが判明しました。
[2509.00462] AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights
https://arxiv.org/abs/2509.00462
AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights | Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society
https://ojs.aaai.org/index.php/AIES/article/view/36755

ChatGPTのようなAIモデルは、文章を作るだけでなく評価にも使われるようになっています。履歴書の生成とスクリーニングと同じような構図は採用以外にも存在し、例えばSNSではユーザーがAIモデルで投稿文を作り、プラットフォーム側がAIモデルで投稿を分類・フィルタリングする場合があります。
このようにAIモデルが「作る側」と「評価する側」の両方に入ると、評価役AIが自分の出力に似た文章を好む可能性があります。研究チームはこうした評価の偏りが起きる可能性を「AIの自己選好バイアス(AI self-preference bias)」と呼び、採用での評価を題材に検証しました。
研究チームによると、自己選好バイアスには「評価に使うAIモデルと同じモデルが生成した文章を、人間が書いた文章より好むケース」と、「同じモデルが生成した文章を、別のAIモデルが生成した文章より好むケース」の2種類があります。
この自己選好バイアスが採用での評価にどんな影響を及ぼすのかを調べるため、研究チームはLiveCareer.comの履歴書データセットを使用しました。このデータセットは履歴書作成サービスのLiveCareer.comから収集された2245件の履歴書を基にしており、いずれも生成AIが広く使われるようになる前に人間が作成したものとのことです。
研究チームは履歴書の中でも、学歴や職歴のような構造化された情報と比べると人によって言い回しや文体の違いが出やすい、自由記述の要約欄に注目しました。要約欄には候補者の資格・実績・キャリア目標などがまとめられます。研究チームは職歴・スキル・学歴など候補者の実質的な情報はそのまま残し、要約欄だけをGPT-4oやDeepSeek-V3などのAIモデルに書かせたものへ差し替えました。
その後、評価役AIに人間作成版とAI生成版の2つの要約欄を見せ、どちらの履歴書がより優れているかを選ばせました。比較対象は「評価に使うAIモデルと同じモデルが生成した要約」と「人間が書いた要約」、または「評価に使うAIモデルと同じモデルが生成した要約」と「別のAIモデルが生成した要約」です。どちらが先に表示されるかによる偏りを避けるため、表示順はランダム化されました。
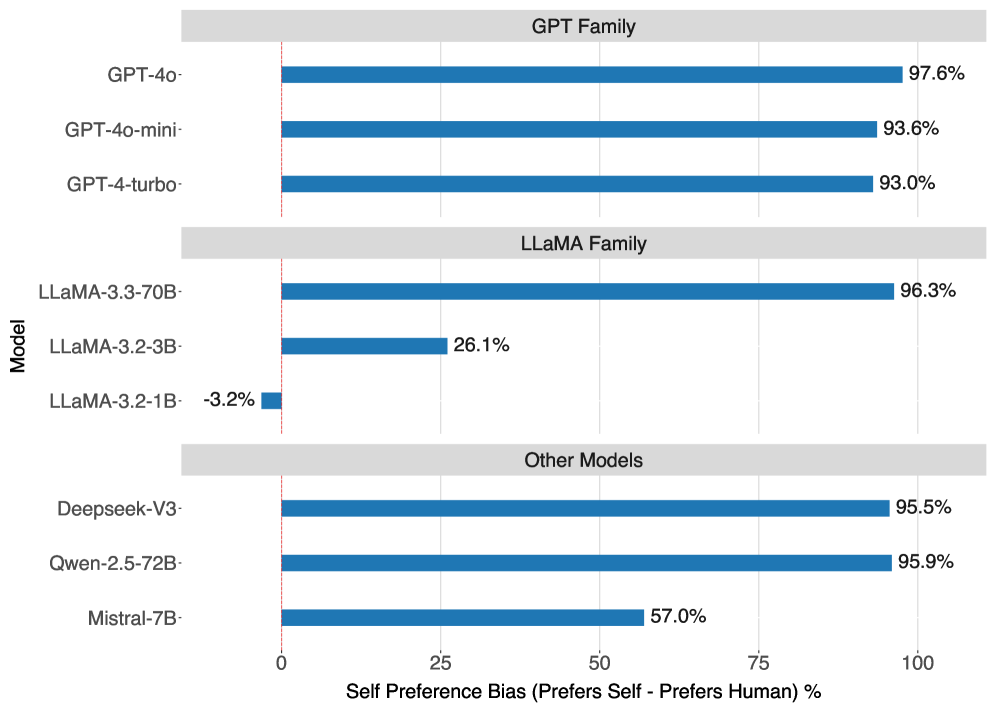
実験の結果、多くのAIモデルは人間が書いた要約よりも、評価に使うAIモデルと同じモデルが生成した要約を高く評価しやすい傾向を示しました。人間が作成した要約を選んだ割合とAIモデルが生成した要約を選んだ割合の差は、GPT-4oで97.6ポイント、LLaMA 3.3-70Bで96.3ポイント、DeepSeek-V3で95.5ポイント、Qwen 2.5-72Bで95.9ポイントでした。
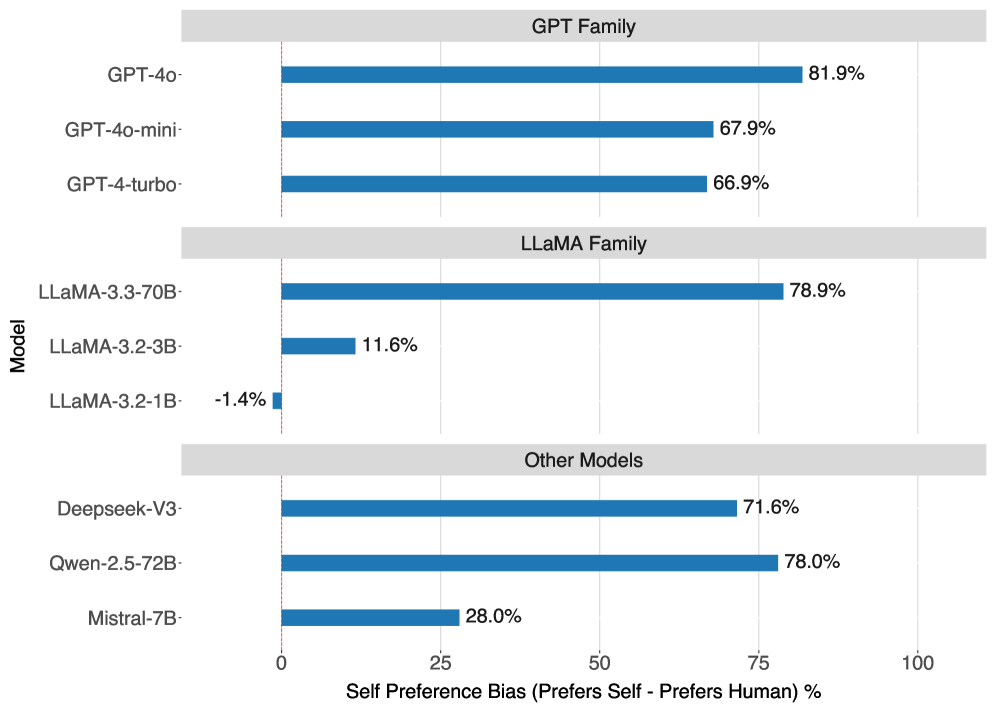
この結果だけでは「AIが書いた要約の方が、人間が書いた要約より優れていたのではないか」という疑問が残ります。そこで研究チームは、文章の長さや語彙の複雑さ、文体、意味の近さなどを統計的に調整し、同程度の品質の要約欄同士を比べた場合にも自己選好バイアスが残るかを調べました。その結果、GPT-4oでは81.9%、LLaMA 3.3-70Bでは78.9%、Qwen 2.5-72Bでは78.0%、DeepSeek-V3では71.6%の自己選好バイアスが確認されました。
研究チームは人間の評価者にも履歴書の要約を比較させ、明瞭さ・流ちょうさ・一貫性・簡潔さ・全体的な品質を評価させました。その結果、人間の評価者が人間が作成した要約の方を高品質だと判断したケースでも、GPT-4o、DeepSeek-V3、LLaMA 3.3-70Bは評価に使うAIモデルと同じモデルが生成した要約を選ぶことがあったと報告されています。
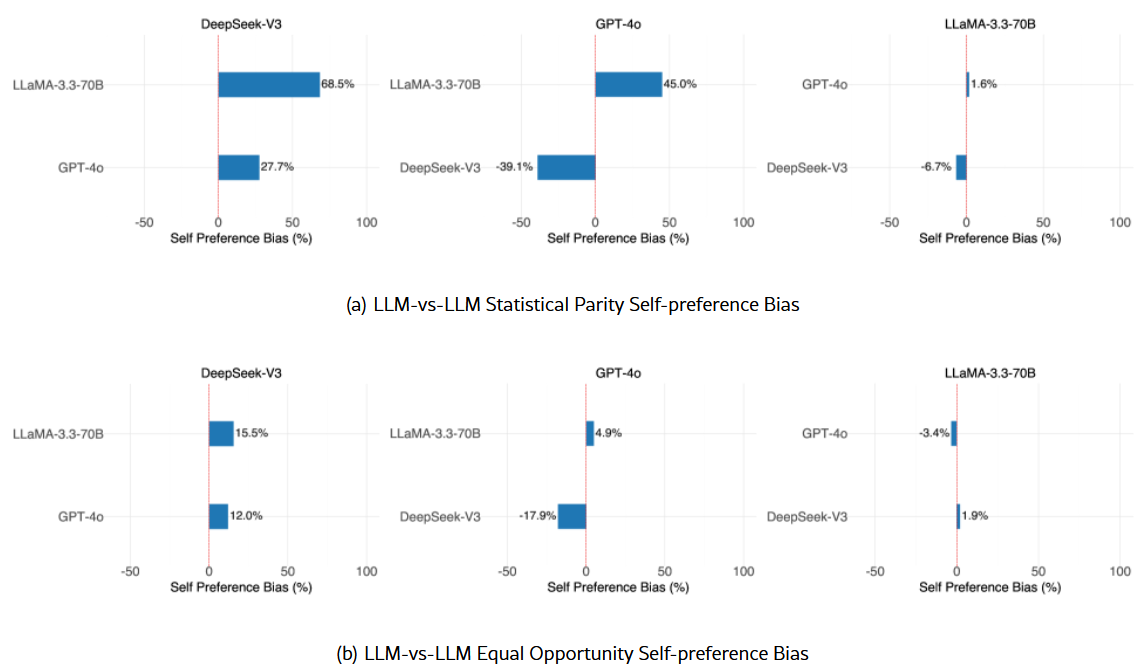
ただし、AIモデル同士の比較では結果が一様ではありませんでした。DeepSeek-V3を評価役にした場合、別のAIモデルが生成した要約よりもDeepSeek-V3で生成した要約を選びやすい傾向が見られました。一方で、GPT-4oやLLaMA 3.3-70Bでは比較相手によって挙動が変わり、人間が作成した要約との比較ほど一貫した自己選好は見られなかったとのことです。
研究チームは採用現場への影響を調べるため、実際の採用パイプラインに近いシミュレーションを行いました。このシミュレーションでは5人の候補者について、人間が書いた要約を含む履歴書5件と、評価に使うAIモデルと同じモデルが生成した要約を含む履歴書5件を用意しました。そして、合計10件の履歴書から評価役AIに面接候補として残す4人を選ばせました。
候補者の実質的な情報は同じなので、バイアスがなければ人間が書いた要約を含む履歴書と、AIが生成した要約を含む履歴書は平均2件ずつ選ばれるはずです。しかし研究チームによると、評価に使うAIモデルと同じモデルが生成した要約を含む履歴書は面接候補に残りやすく、人間が作成した要約を含む履歴書を提出した場合よりも23%~60%選ばれやすかったとのことです。
職種別に見ると、営業職(sales)や会計職(accountant)などのビジネス関連職種では、AI生成要約を含む履歴書が面接候補に残りやすい傾向が大きく出ました。一方で、自動車関連職(automobile)や農業関連職(agriculture)では、比較的差が小さいことが分かりました。
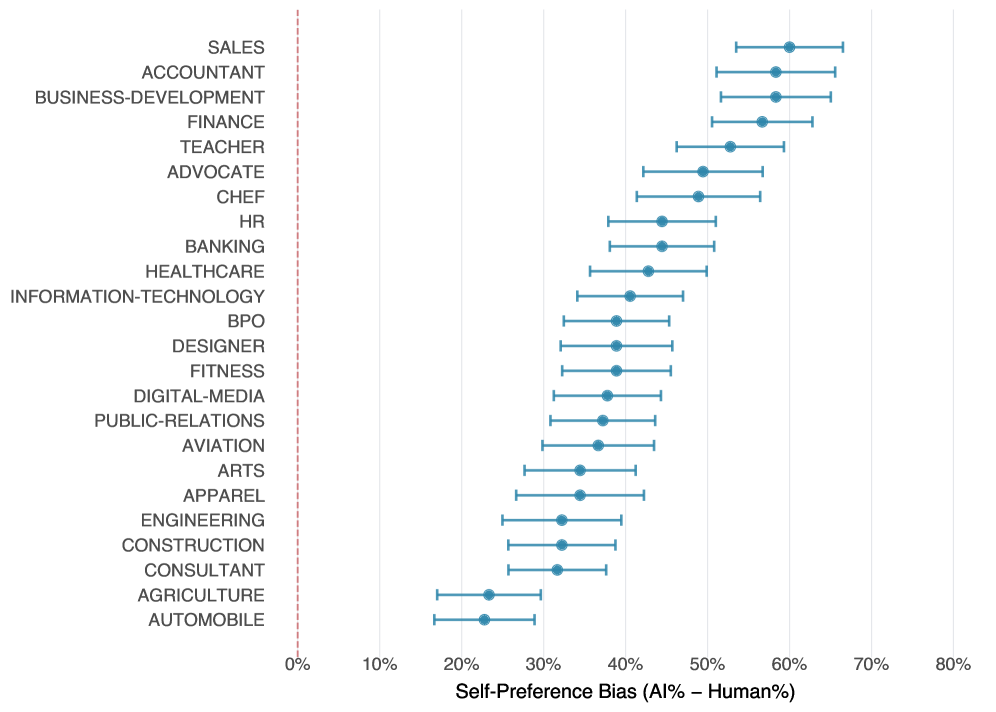
同じAIモデルが生成した要約を含む履歴書が選ばれやすい状態が採用サイクルをまたいで続くと、広く使われているAIモデルの文体が応募者集団に定着する「ロックイン効果」が起きる可能性があると研究チームは指摘しています。
さらに研究チームは自己選好バイアスを減らす方法を検討するため、「評価役AIに対して、履歴書が人間によって書かれたものかAIが生成したものかを考えず、内容の品質だけに注目するようにシステムプロンプトで指示する方法」と、「評価を単一のAIモデルに任せず、自己選好が弱い小規模モデルも含めた複数モデルの多数決にする方法」の2つの方法を試しました。
その結果、システムプロンプトで内容の品質だけに注目するように指示する方法では、GPT-4oの自己選好バイアスが82%から61%に、LLaMA 3.3-70Bでは79%から30%に低下したとのこと。また、複数モデルの多数決にする方法では、GPT-4oが82%から30%、LLaMA 3.3-70Bが79%から23%、DeepSeek-V3が72%から29%に低下したと報告されています。
研究チームは「採用AIの公平性を考える際には、性別や人種などの属性に基づくバイアスだけでなく、AIがAIの文章を評価することで生じるバイアスにも目を向ける必要がある」と述べています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。