

アメリカのAIスタートアップ「Zyphra」が、AMDのGPUインフラで学習した小型推論向け言語モデル「ZAYA1-8B」を公開しました。ウェイトが公開されており、商用利用も可能となっています。
Zyphra
https://www.zyphra.com/post/zaya1-8b
ZAYA1-8Bは、モデル全体として約80億パラメータを持ちながら、推論時に主に使う有効パラメータを約7億に抑えたMixture of Experts(MoE)モデルです。複数の専門家ネットワークから入力内容に合う一部だけを呼び出すMoE方式を活用することで、ZAYA1-8Bは計算量を抑えながら高い推論性能を実現したとのこと。Zyphraは、ZAYA1-8Bが数学、コーディング、複雑な推論タスクで大規模モデルに迫る性能を発揮すると説明しています。
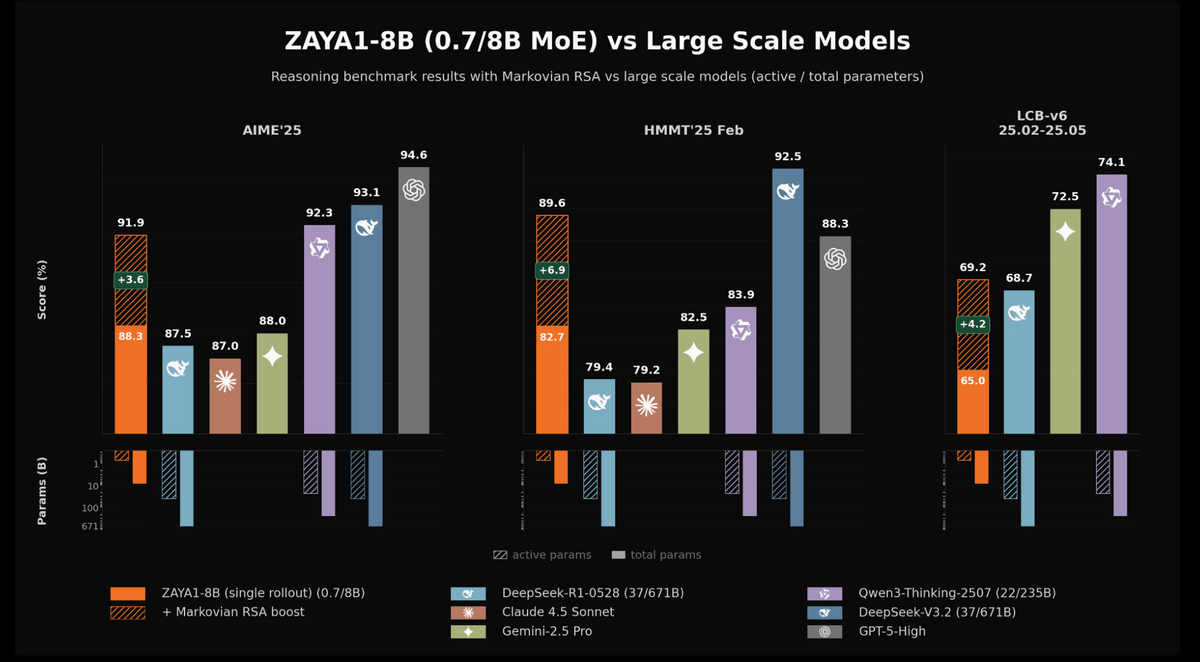
以下はZAYA1-8Bと各種大規模モデルを、AIME’25、HMMT’25 Feb、LCB-v6 25.02-25.05の推論ベンチマークで比較したグラフ。ZAYA1-8BはAIME’25で88.3%、HMMT’25 Febで82.7%、LCB-v6で65.0%を記録し、「マルコフ型RSA」という推論時追加計算を加えることで、それぞれ91.9%、89.6%、69.2%まで向上しています。下段では、各モデルの有効パラメータ数と総パラメータ数が示されており、ZAYA1-8Bが有効パラメータ約7億、総パラメータ約80億という小規模なMoEモデルでありながら、大規模モデルに近いスコアを出していることが分かります。
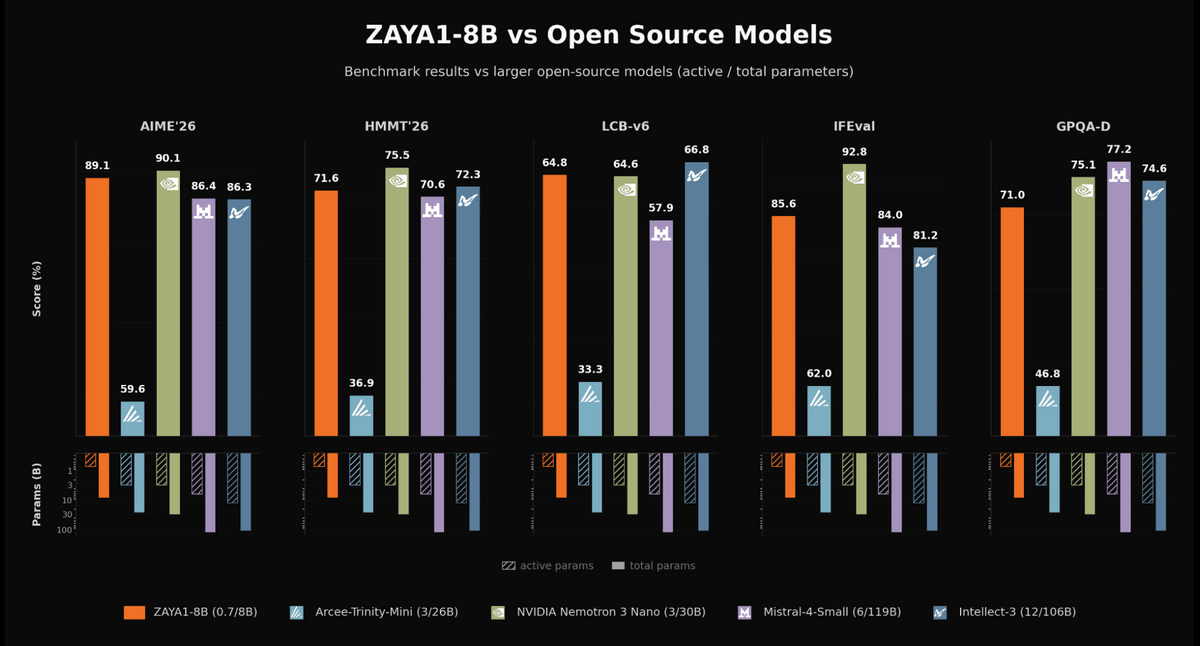
Zyphraが特に強調しているのは、「有効パラメータあたりの知能密度」です。通常、パラメータ数が大きいモデルほど性能が高くなる傾向がありますが、ZAYA1-8Bは有効パラメータを10億未満に抑えつつ、AIMEやHMMTなどの数学ベンチマーク、LCBことLiveCodeBenchのコーディングベンチマーク、GPQA-Diamondのような知識・推論ベンチマーク、IFEvalやIFBenchのような指示追従ベンチマークで競争力のあるスコアを示しています。Zyphraは、Mistral-Small-4-119Bのようなはるかに大きな重み公開モデルを一部の数学・コーディング評価で上回ったと説明しています。
以下はZAYA1-8Bと大規模なオープンソースモデルを、AIME’26、HMMT’26、LCB-v6、IFEval、GPQA-Dの5種類のベンチマークで比較したグラフ。ZAYA1-8BはAIME’26で89.1%、HMMT’26で71.6%、LCB-v6で64.8%、IFEvalで85.6%、GPQA-Dで71.0%を記録しています。比較対象にはArcee-Trinity-Mini、NVIDIA Nemotron 3 Nano、Mistral-4-Small、Intellect-3が含まれており、ZAYA1-8Bは有効パラメータ約7億、総パラメータ約80億という小さな構成ながら、数学、コード、指示追従、専門知識を問う複数の評価で競争力のある結果を示しました。
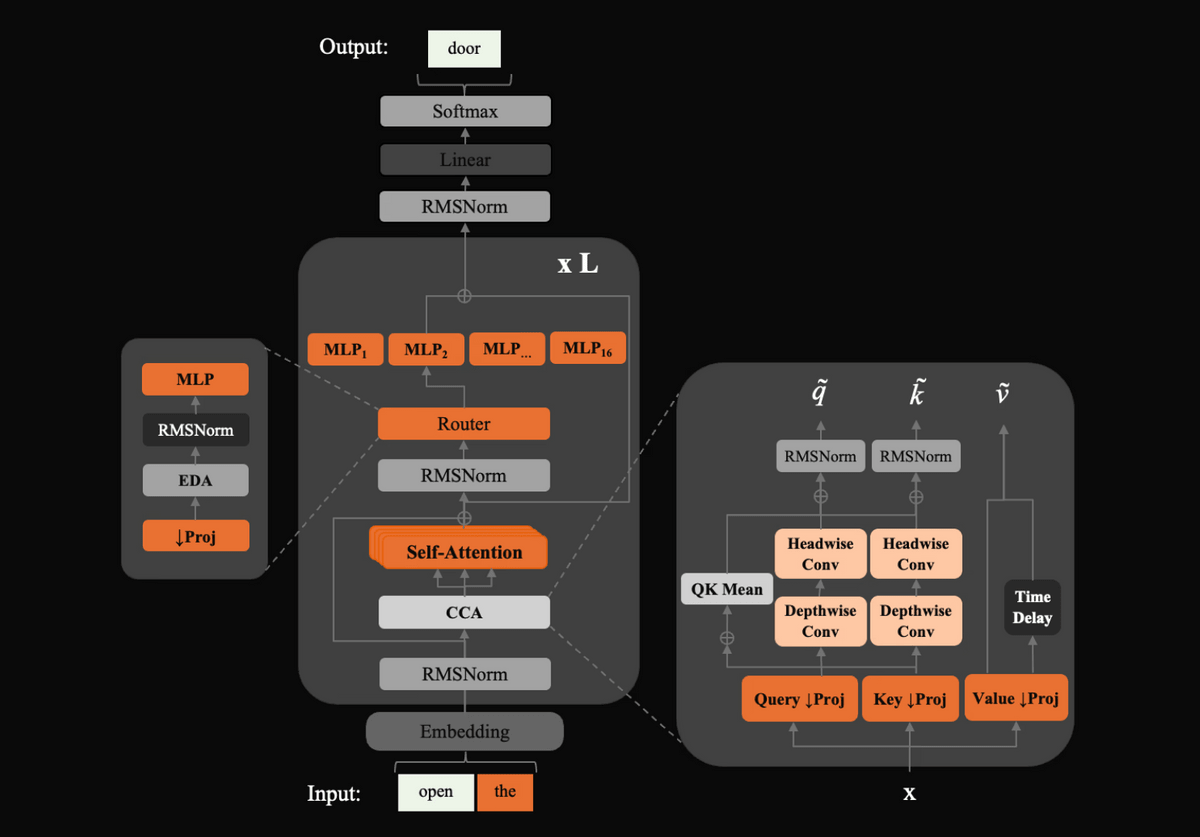
ZAYA1-8Bの設計では、効率化のために3つの仕組みが組み込まれています。1つ目はTransformerで計算負荷が大きくなりやすい注意機構を効率化するための「Compressed Convolutional Attention(CCA)」です。2つ目は、MoEで呼び出す専門家ネットワークを選ぶ部品であるルーターに、MLPベースのルーターを採用した点です。Zyphraによると、MLPベースのルーターにより、線形ルーターより安定した専門家選択を実現できたとのこと。3つ目は学習可能な残差スケーリングで、残差接続を深い層まで積み重ねると内部表現の大きさが膨らみやすくなるため、学習可能な係数で大きさを制御しています。
以下はZAYA1-8Bのモデル構造を示した図。入力トークンがEmbedding層を通過した後、RMSNorm、CCA、Self-Attention、MoEルーター、複数のMLPエキスパートを含むブロックで処理され、最終的に出力トークンが生成されます。右側ではCCA内部のQuery、Key、Value処理や畳み込み処理が拡大表示されており、効率的な注意機構を組み込んだ設計であることが分かります。
Zyphraによると、ZAYA1-8Bは事前学習、中間学習、教師ありファインチューニングまでAMD Instinct MI300系の環境で実施したとのこと。学習には1024基のAMD Instinct MI300Xノード、AMD Pensando Pollaraインターコネクト、IBMと構築したカスタム学習クラスターが使われたとされています。大規模AIモデルの学習環境ではNVIDIA製GPUが話題になりがちですが、ZAYA1-8BはAMDスタックで競争力のある推論モデルを作れるかを示す事例としても注目できます。
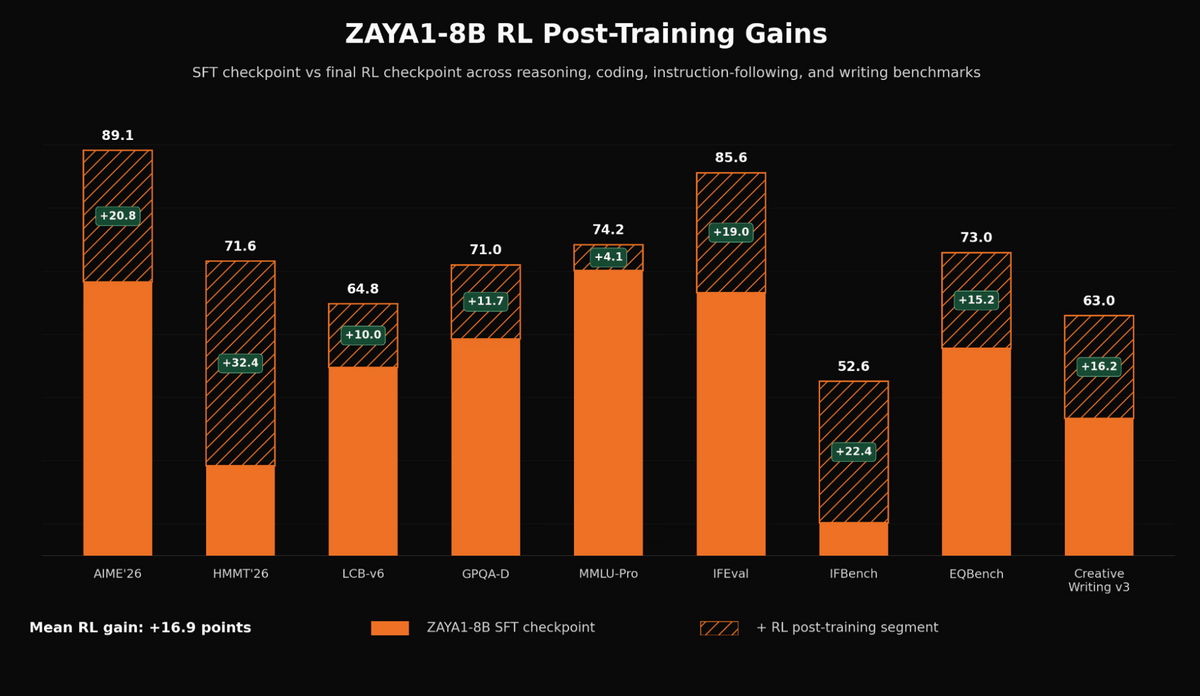
ZAYA1-8Bは、事前学習だけで性能を出しているわけではありません。Zyphraは、教師ありファインチューニングの後に、推論ウォームアップ、大規模な強化学習、数学とコードに特化した強化学習、さらに人間のフィードバックを使う強化学習(RLHF)およびAIのフィードバックを使う強化学習(RLAIF)を使ったチャット品質や振る舞いの改善を行ったと説明しています。ZAYA1-8Bでは、検証しやすい数学やコードのような領域に加えて、指示追従やクリエイティブライティングでも改善が見られたとのこと。
下図はZAYA1-8Bにおける強化学習ベースの事後学習による性能向上を示したグラフ。オレンジ部分は教師ありファインチューニング後のスコア、斜線部分は強化学習による追加の伸びを表しており、AIME’26、HMMT’26、IFEval、IFBenchなどで大きな改善が確認できます。平均では16.9ポイントのスコア向上が示されています。
ZAYA1-8Bのもう1つの目玉が「マルコフ型RSA」です。マルコフ型RSAは、モデルの重みを増やす代わりに回答を作る段階で複数の候補を生成し、候補を統合して精度を高める推論時追加計算と呼ばれる仕組みの一種です。ZAYA1-8Bのマルコフ型RSAでは、複数の推論過程を並列に生成し、各推論過程の末尾だけを取り出し、末尾の断片を組み合わせた集約プロンプトを次の推論に使います。長い推論過程を丸ごと次の段階へ渡さないため、文脈長の増加を抑えながら、より長く考えさせる設計になっています。
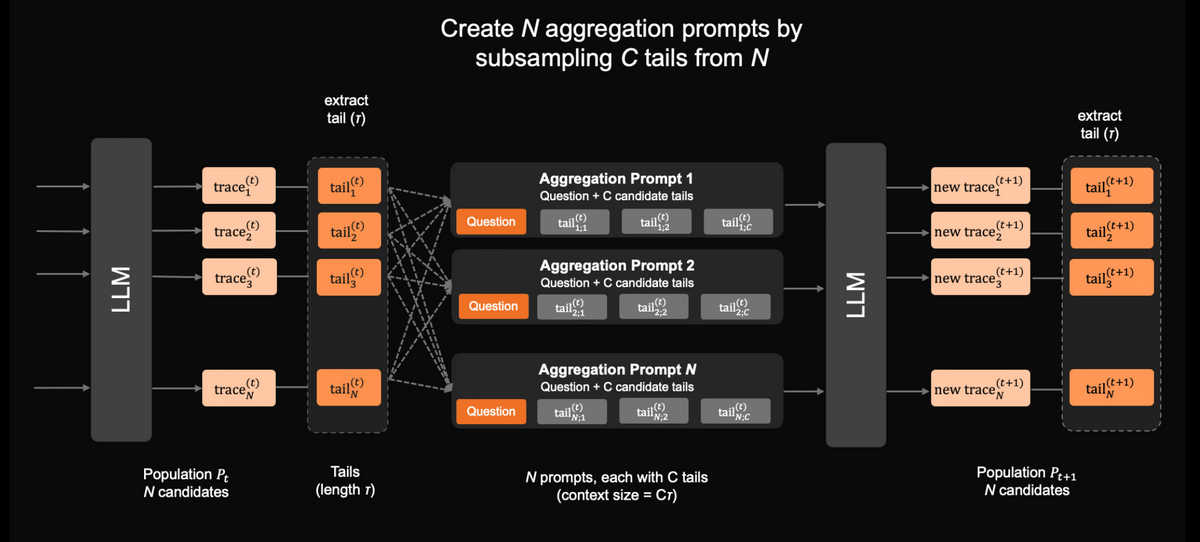
以下はマルコフ型RSAで複数の推論候補を統合する手順を示した図。まずLLMがN個の推論過程を生成し、各推論過程から末尾部分を抽出します。次に、N個の末尾部分からC個ずつをサンプリングしてN個の集約プロンプトを作成し、各プロンプトを再びLLMへ入力して新しい推論過程を生成します。集約プロンプトの文脈サイズが制限されるため、過去の推論全体を保持せずに候補の要点だけを引き継ぎ、推論の質を段階的に高める仕組みになっています。
Zyphraは、マルコフ型RSAを使ったZAYA1-8BがHMMT’25でClaude 4.5 SonnetやGPT-5-Highを上回ったと説明しています。ただし、マルコフ型RSAを使った成績は、通常の1回だけの推論ではなく、追加の推論計算を使った結果です。ZAYA1-8Bの強みは「常に大規模フロンティアモデルを置き換える」というより、「小型モデルに追加の推論時間を与えることで、数学やコードのような検証しやすい問題で大きな伸びを得られる」という点にある模様。
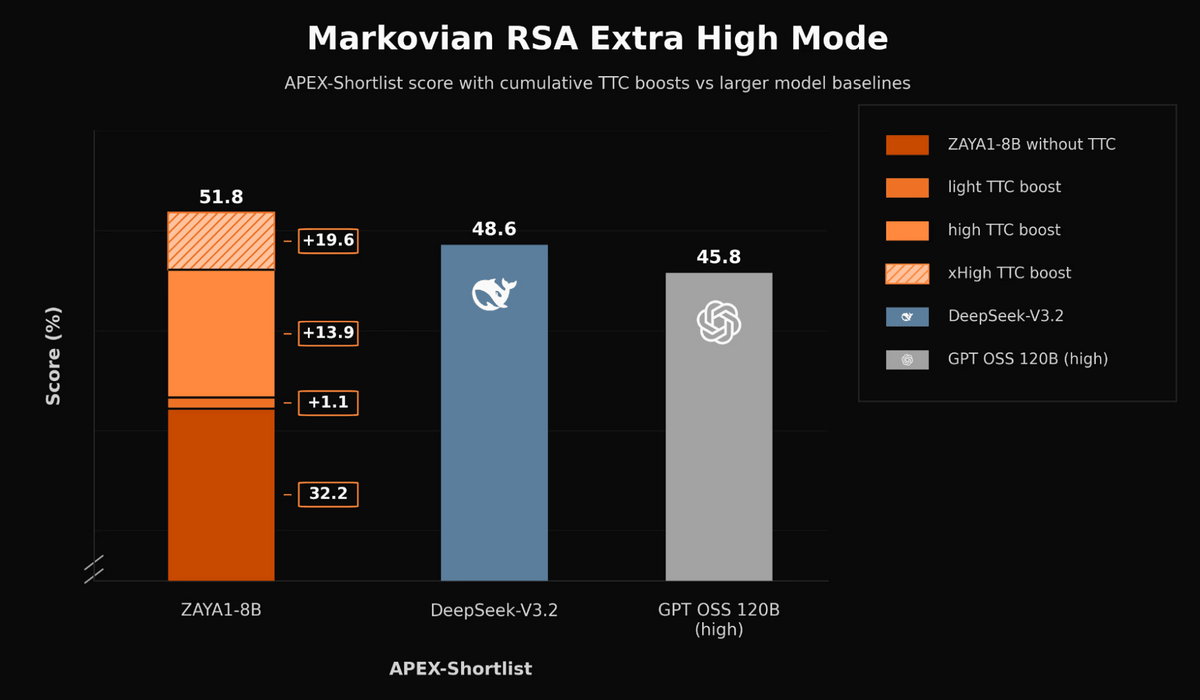
下図はマルコフ型RSAのExtra High Modeによる推論時追加計算の効果を示した比較グラフ。ZAYA1-8Bは推論時追加計算なしではAPEX-Shortlistで32.2%ですが、追加計算を段階的に増やすことで最終的に51.8%に到達し、DeepSeek-V3.2の48.6%やGPT OSS 120Bの45.8%を上回る結果が示されています。
ZAYA1-8BはZyphra Cloudのサーバーレスエンドポイントから利用でき、モデルの重みもHugging Faceで公開されています。ライセンスはApache 2.0で、研究だけでなく商用利用も可能です。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。