

AlibabaのAI研究チームであるQwen(Tongyi Lab)が「Qwen3.5-Omni」を2026年3月30日に発表しました。Qwen3.5-Omniはテキスト・画像・音声・動画の理解が可能なオムニモーダルモデルで、テキストだけでなく音声も生成することが可能。音声と映像の理解能力はGemini 3.1 Proを超えているとアピールされています。
Qwen3.5-Omni: Scaling Up, Toward Native Omni-Modal AGI
https://qwen.ai/blog?id=qwen3.5-omni
Qwen-Omni – Alibaba Cloud Model Studio – Alibaba Cloud Documentation Center
https://www.alibabacloud.com/help/en/model-studio/qwen-omni
Qwen3.5-Omniは合計1億時間以上の視覚音声データを用いてトレーニングされたAIモデルです。内部には「Hybrid MoE Talker」と「Hybrid MoE Thinker」が組み込まれており、Thinkerのテキスト出力をTalkerに伝えることで文脈に応じた音声を出力することが可能です。さらに、モデルの全体がリアルタイム応答を念頭に設計されているのも特徴です。
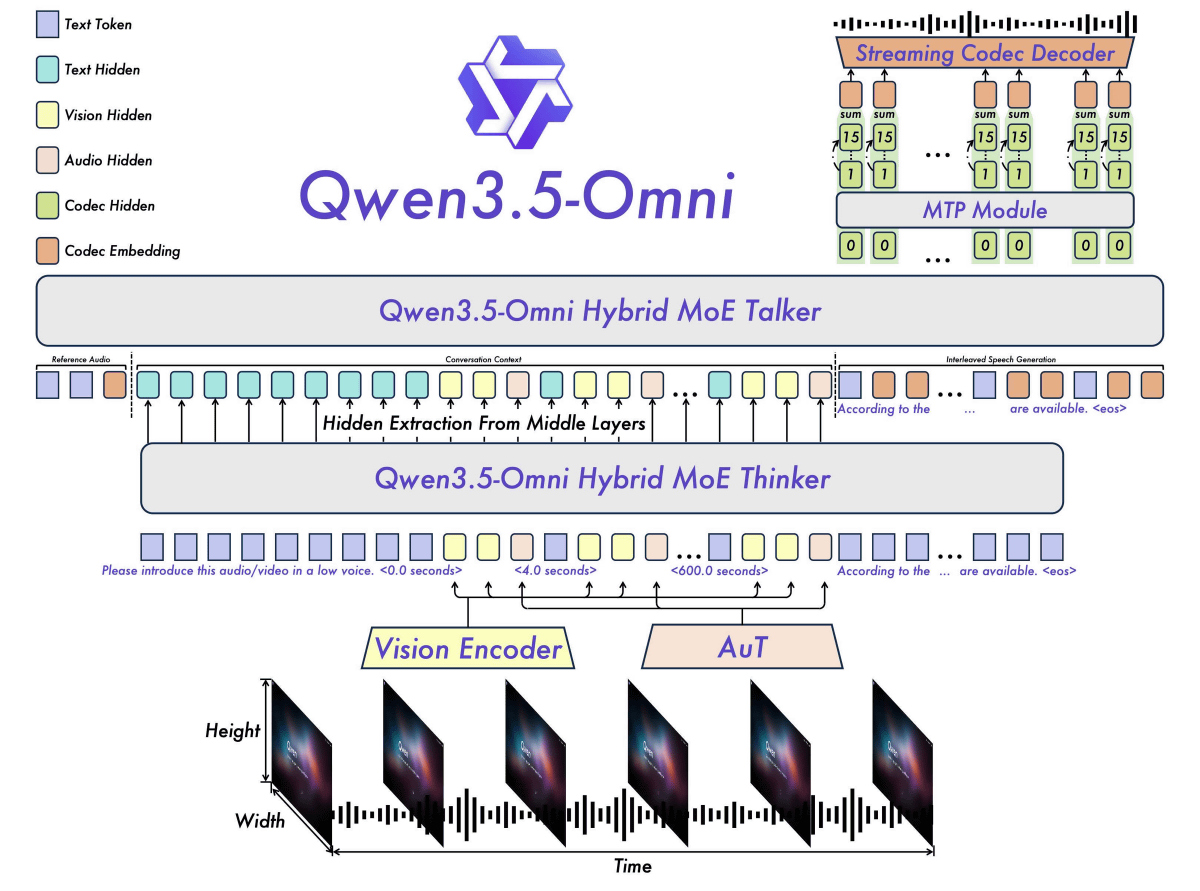
Qwen3.5-Omniの最大シーケンス長は25万6000で、10時間の音声や400秒(1FPS)の視聴覚データを入力することができます。音声認識機能は中国語39方言に加えて日本語・英語を含む74言語に対応。さらに、音声合成は中国語7方言に加えて日本語・英語を含む29言語に対応しています。
Qwen3.5-Omniは「Qwen3.5-Omni Plus」「Qwen3.5-Omni Flash」「Qwen3.5-Omni Light」の3モデルに分かれてリリースされており、オフラインAPIとリアルタイムAPIを介して利用可能です。
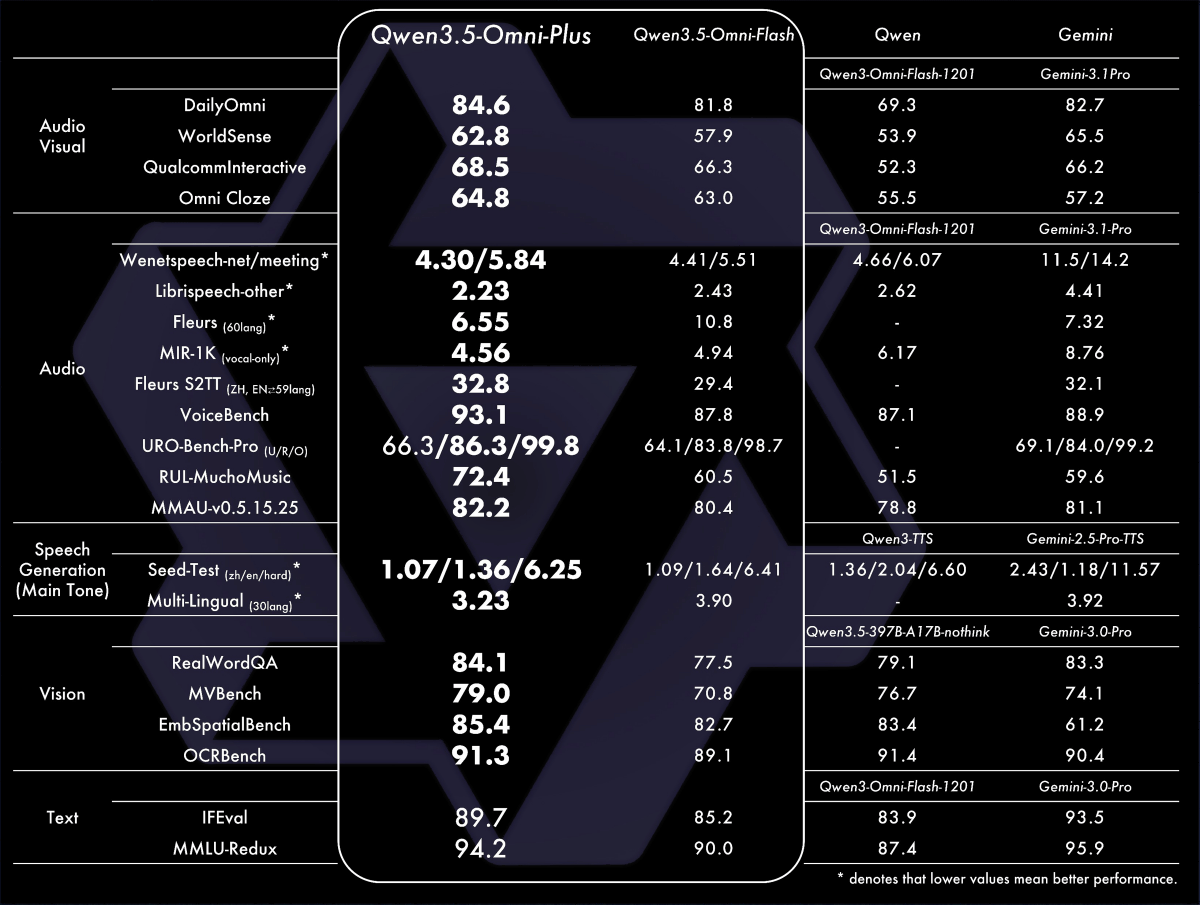
「Qwen3.5-Omni Plus」「Qwen3.5-Omni Flash」「Qwen旧モデル」「Gemini 3.1 Pro」の各種ベンチマーク結果を並べた表が以下。Qwen3.5-Omni Plusは複数のテストでGemini 3.1 Proを上回っています。
Qwen3.5-Omniの視聴覚データ認識性能を示すデモ動画が以下。動画に含まれる事象をテキストで正確に説明できています。
「手書きの設計図を示しつつ目的の機能を口頭で説明する」という動画を入力して適切なコードを出力させることも可能。Tongyi Labは一連の操作を「Audio-Visual Vibe Coding」と呼称しています。
声色を調整しながら高品質な音声を生成することもできます。
Qwen3.5-Omniのデモは以下のリンクで実行できます。
Qwen3.5 Omni Offline Demo – a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen3.5-Omni-Offline-Demo
また、リアルタイム応答機能のデモも公開されています。
Qwen3.5 Omni Online Demo – a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen3.5-Omni-Online-Demo
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。