
Metaが文字起こしAI「Omnilingual ASR」をリリースしました。Omnilingual ASRは日本語を含む1600以上の言語の文字起こしに対応しており、対応言語を簡単に追加できることも特徴としています。
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages | Research – AI at Meta
https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/
Omnilingual ASR: Advancing Automatic Speech Recognition for 1,600+ Languages
https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
文字起こしAIを開発するには、膨大な学習データを用意するのが一般的です。Omnilingual ASRでは70億パラメーターの音声エンコーダー「wav2vec 2.0」を採用することで必要な学習データの削減に成功しました。
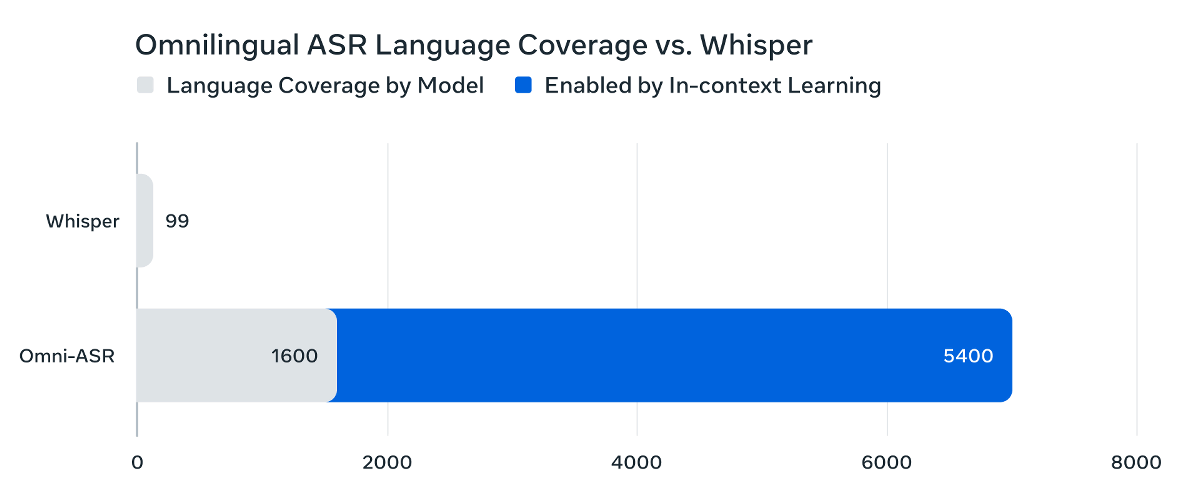
対応する1600以上の言語のうち78%の言語で文字誤り率(CER)が10%を下回っています。CERが10%を下回った言語のうち、50時間以上の学習データを必要としたのは236言語で、195言語は10時間未満の学習データでトレーニングされました。また、Omnilingual ASRは大規模言語モデルなどで採用されているコンテキスト内学習(In-Context Learning)に対応しており、少ない操作で対応言語を増やすことができます。これにより、Whisperなどの既存モデルと比べて圧倒的に多くの言語をサポートできます。
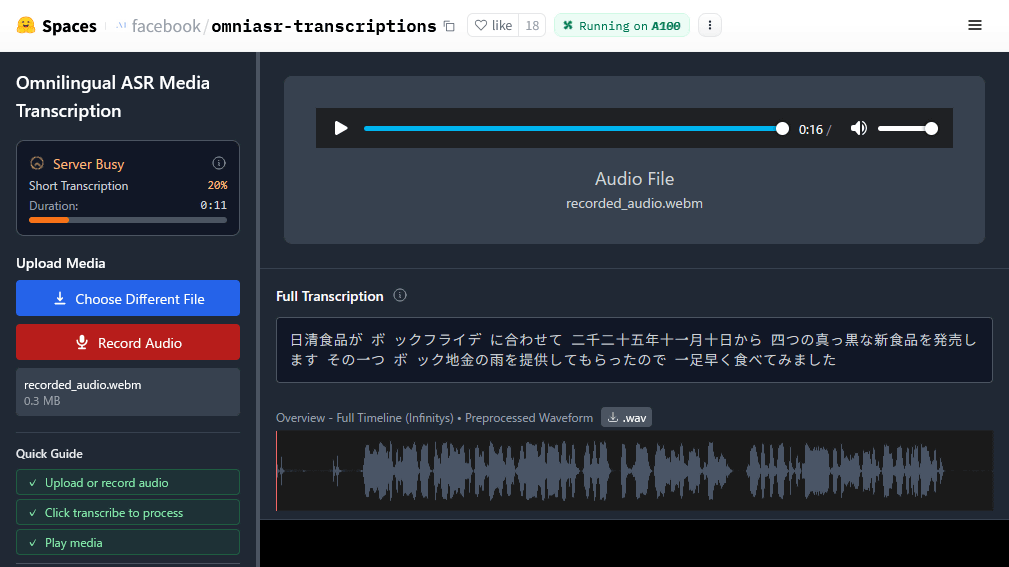
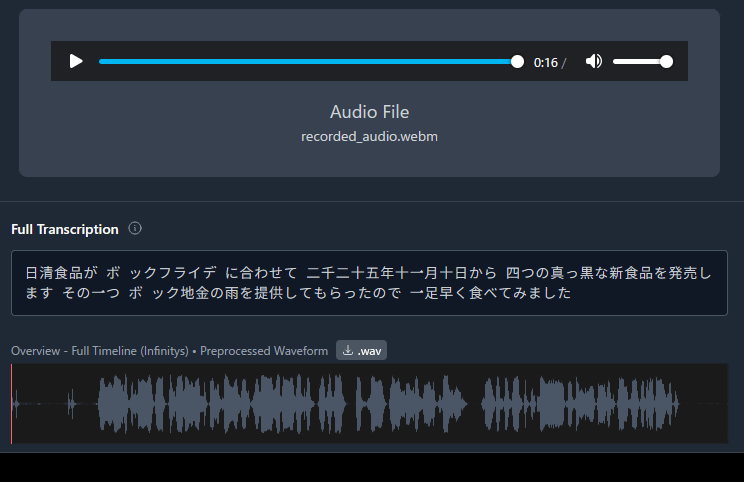
Omnilingual ASRを実行できるデモページが以下のリンク先で公開されています。
Omnilingual ASR Media Transcription – a Hugging Face Space by facebook
https://huggingface.co/spaces/facebook/omniasr-transcriptions

実際にGIGAZINEの記事を読み上げて文字起こししてみたところ、「ブラックチキンラーメン」が「ボック地金の雨」という謎フレーズになってしまいました。
Omnilingual ASRのソースコードやドキュメントは以下のリンク先で公開されています。
GitHub – facebookresearch/omnilingual-asr: Omnilingual ASR Open-Source Multilingual SpeechRecognition for 1600+ Languages
https://github.com/facebookresearch/omnilingual-asr
対応言語一覧は以下のコードに記されています。日本語も「jpn_Jpan」として記載されています。また、対応言語を探索できるインタラクティブなページも用意されています。
omnilingual-asr/src/omnilingual_asr/models/wav2vec2_llama/lang_ids.py at main · facebookresearch/omnilingual-asr · GitHub
https://github.com/facebookresearch/omnilingual-asr/blob/main/src/omnilingual_asr/models/wav2vec2_llama/lang_ids.py
さらに、Omnilingual ASRの開発時に収集された音声データセット「Omnilingual ASR Corpus」も公開されています。
facebook/omnilingual-asr-corpus · Datasets at Hugging Face
https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。