

中国に拠点を置くAI企業のDeepSeekが、長大な入力に最適化したAIモデル「DeepSeek-V3.2-Exp」を発表しました。DeepSeek-V3.2-Expは同等のベンチマークスコアを記録する他のモデルと比べて大きな入力を与えられた際の計算効率がはるかに向上しています。
🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model!
✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context.
👉 Now live on App, Web, and API.
💰 API prices cut by 50%+!1/n
— DeepSeek (@deepseek_ai) September 29, 2025
DeepSeek-V3.2-Expは「DeepSeek-V3.1」のアップデート版である「DeepSeek-V3.1-Terminus」をベースに開発されたモデルで、長コンテキストにおける学習および推論を最適化するスーパーアテンションメカニズム「DeepSeek Sparse Attention」を取り入れた実験的モデルとして位置付けられています。
DeepSeek-V3.2-ExpはDeepSeek Sparse Attentionの効果を検証するために学習構成がDeepSeek-V3.1-Terminusとそろえられています。DeepSeek-V3.2-ExpとDeepSeek-V3.1-Terminusのベンチマークスコア比較表を見ると、両者のスコアがほぼ一致していることが分かります。
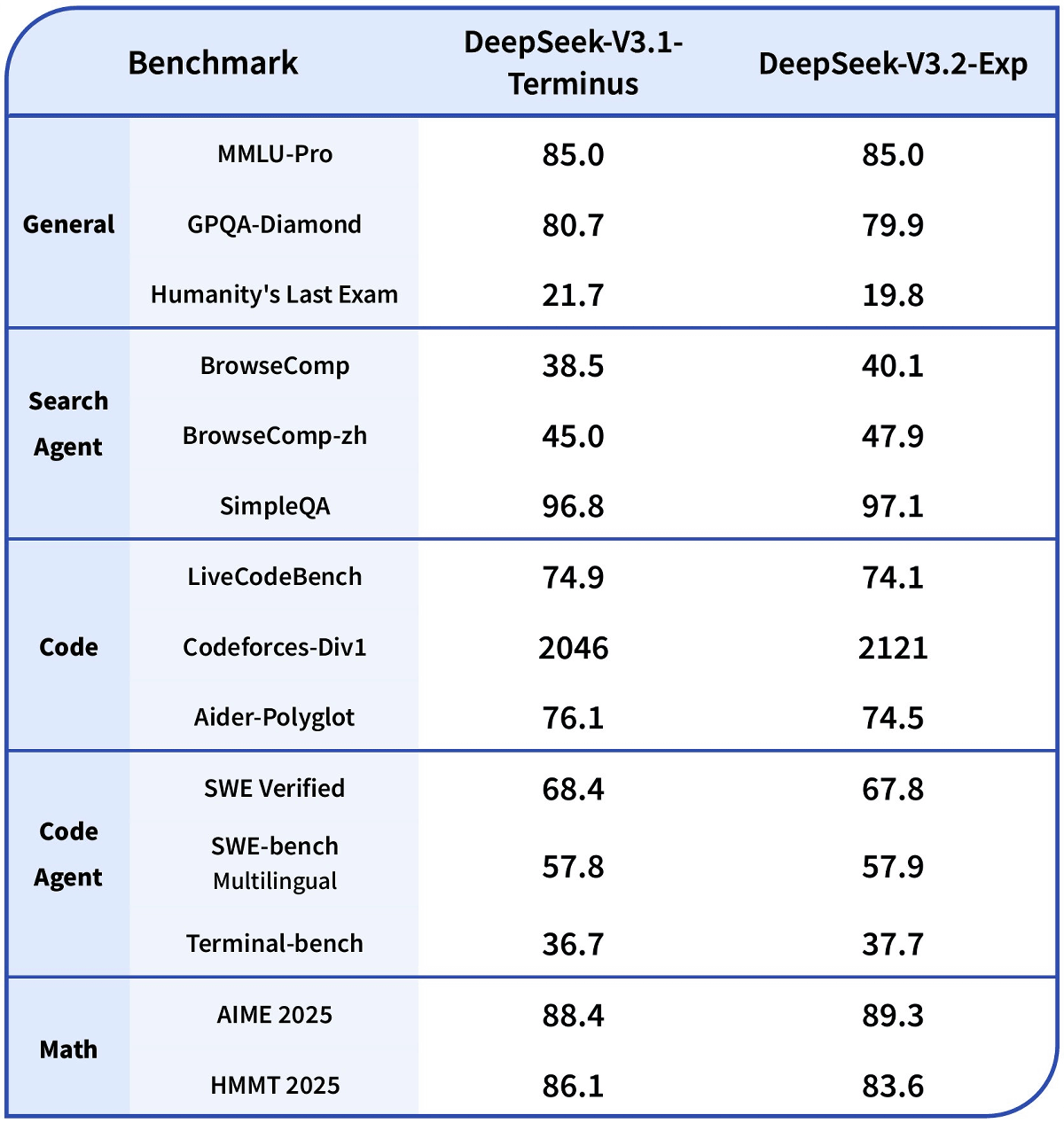
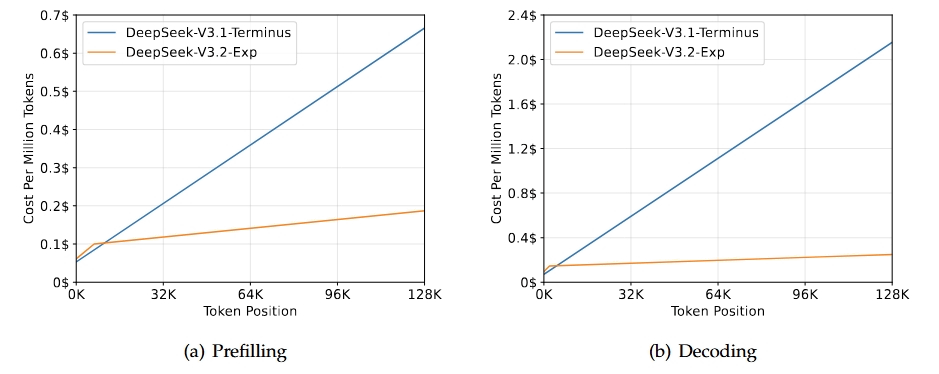
一方で、長大な入力を受け取った際の計算効率やコスト効率には大きな差があります。以下のグラフはDeepSeek-V3.2-Exp(オレンジ)とDeepSeek-V3.1-Terminus(青)のコスト効率を比較したグラフで、横軸が一度に処理するトークン数、縦軸が100万トークン当たりのコストを示しています。DeepSeek-V3.2-Expの方がトークン数の増加に対するコストの増加を大幅に抑えられていることが分かります。
DeepSeek-V3.2-Expのモデルデータは以下のリンク先で公開されています。ライセンスは制限の緩いMIT Licenseを採用しています。
deepseek-ai/DeepSeek-V3.2-Exp · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
また、DeepSeek-V3.2-ExpはAPI経由での利用も可能で、API使用料金はキャッシュ無しの入力が100万トークン当たり0.28ドル(約41.6円)、キャッシュありの入力が100万トークン当たり0.028ドル(約0.42円)、出力が100万トークン当たり0.42ドル(約62.4円)です。
💻 API Update
🎉 Lower costs, same access!
💰 DeepSeek API prices drop 50%+, effective immediately.🔹 For comparison testing, V3.1-Terminus remains available via a temporary API until Oct 15th, 2025, 15:59 (UTC Time). Details: https://t.co/3RNKA89gHR
🔹 Feedback welcome:… pic.twitter.com/qEdzcQG5bu— DeepSeek (@deepseek_ai) September 29, 2025
この記事のタイトルとURLをコピーする
・関連記事
DeepSeekが推論モデル「R1」をわずか4400万円でトレーニングしたと発表、512基のNVIDIA H800チップを80時間使用 – GIGAZINE
中国政府がDeepSeekの新AIモデル「DeepSeek-R2」をHuawei製チップで開発するよう求めたが失敗してリリースが遅れているとの報道 – GIGAZINE
中国製AI「DeepSeek」は中国政府の好まない相手向けにわざと低品質な回答を出力している可能性あり – GIGAZINE
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。