

中国に拠点を置く大手テクノロジー企業「Alibaba」のAI研究チーム「Qwen」が、自然言語でリアルタイム応答できるAIモデル「Qwen3-Omni」を2025年9月22日に発表しました。さらに、9月22日~24日の短期間に「Qwen3-VL」「Qwen3-TTS」「Qwen-Image-Edit-2509」「Qwen3-VL」「Qwen3-LiveTranslate-Flash」「Qwen3-Max」といったAIモデルが続々と発表されています。
◆Qwen3-Omni
Qwen3-Omniはテキスト・画像・音声・動画を処理してリアルタイムで応答できるAIモデルです。テキストと音声での応答に対応しているほか、119言語のテキスト理解、19言語の音声理解、10言語の音声生成が可能な多言語性能の高さも特徴です。
Qwen3-Omni: Natively Omni-Modal Foundation Models!
https://qwen.ai/blog?id=fdfbaf2907a36b7659a470c77fb135e381302028&from=research.research-list
ユーザーは「スマートフォンのカメラに写っているものについて、Qwen3-Omniと会話する」といったことが可能。Qwen3-Omniの動作例は以下の動画で確認できます。
Qwen3-Omni: Natively Omni-Modal Foundation Models! – YouTube

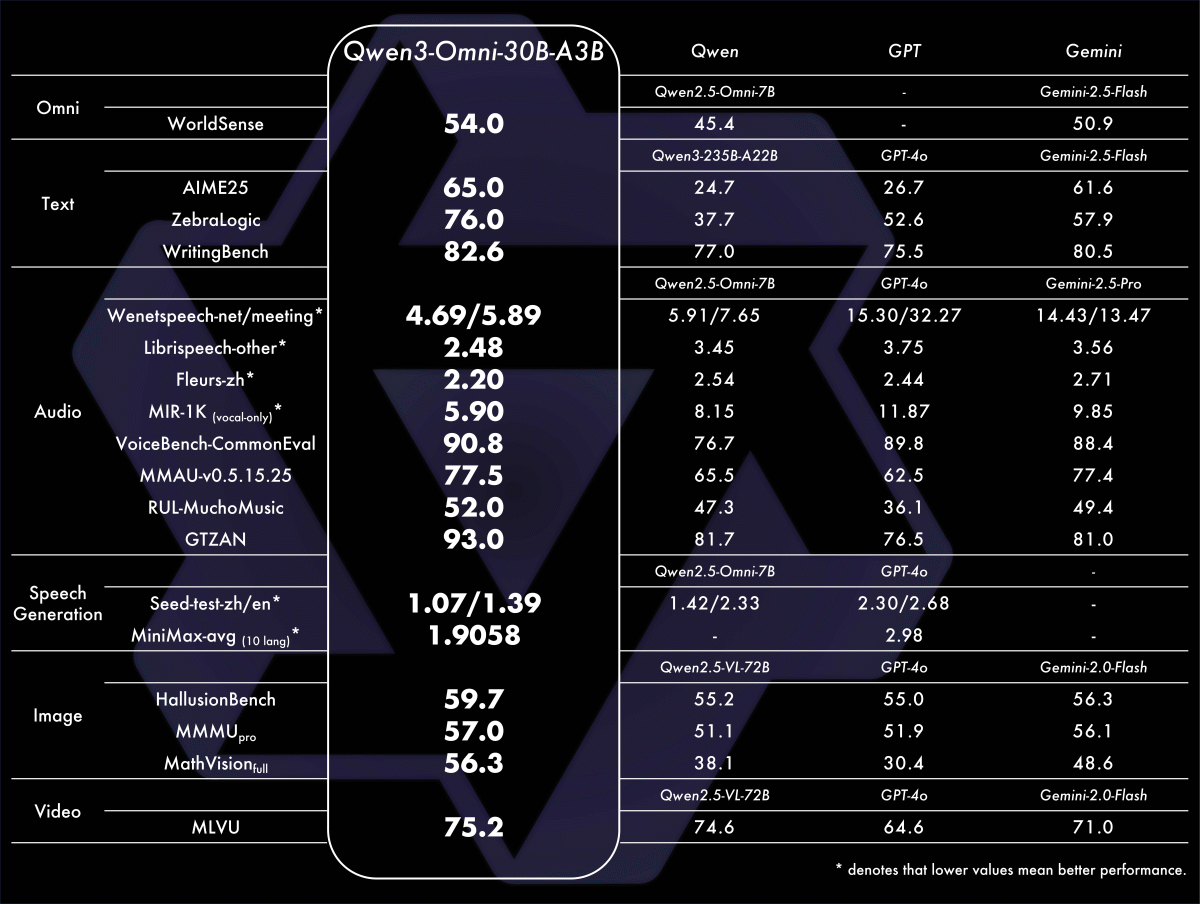
QwenチームはQwen3-Omni-FlashとQwen3-Omni-30B-A3Bのベンチマーク結果を公開しています。Qwen3-Omni-FlashはGPT-4oやGemini-2.5-Flashと同等以上のスコアを記録しています。
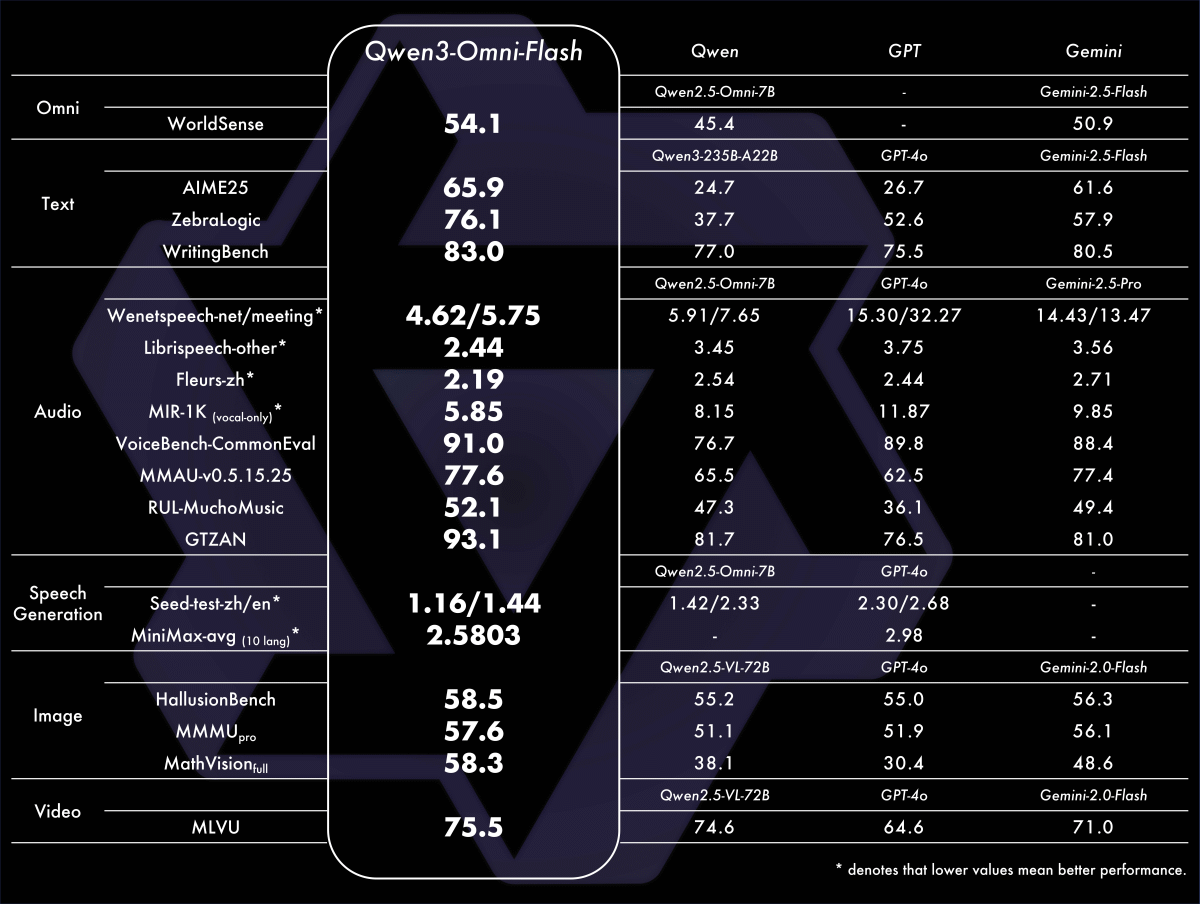
そして、Qwen3-Omni-30B-A3BはGPT-4oとQwen3-Omni-30B-A3Bのスコアをほとんどテストで上回っています。
Qwen3-Omniの各モデルは以下のリンク先で公開されています。
Qwen3-Omni – a Qwen Collection
https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
◆Qwen3-VL
Qwen3-VLは高度な画像認識性能を備えたビジュアル言語モデルで、写真やアプリのスクリーンショットなどの内容を理解することが可能。また、32言語のOCRもサポートしています。
Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action
https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef&from=research.latest-advancements-list

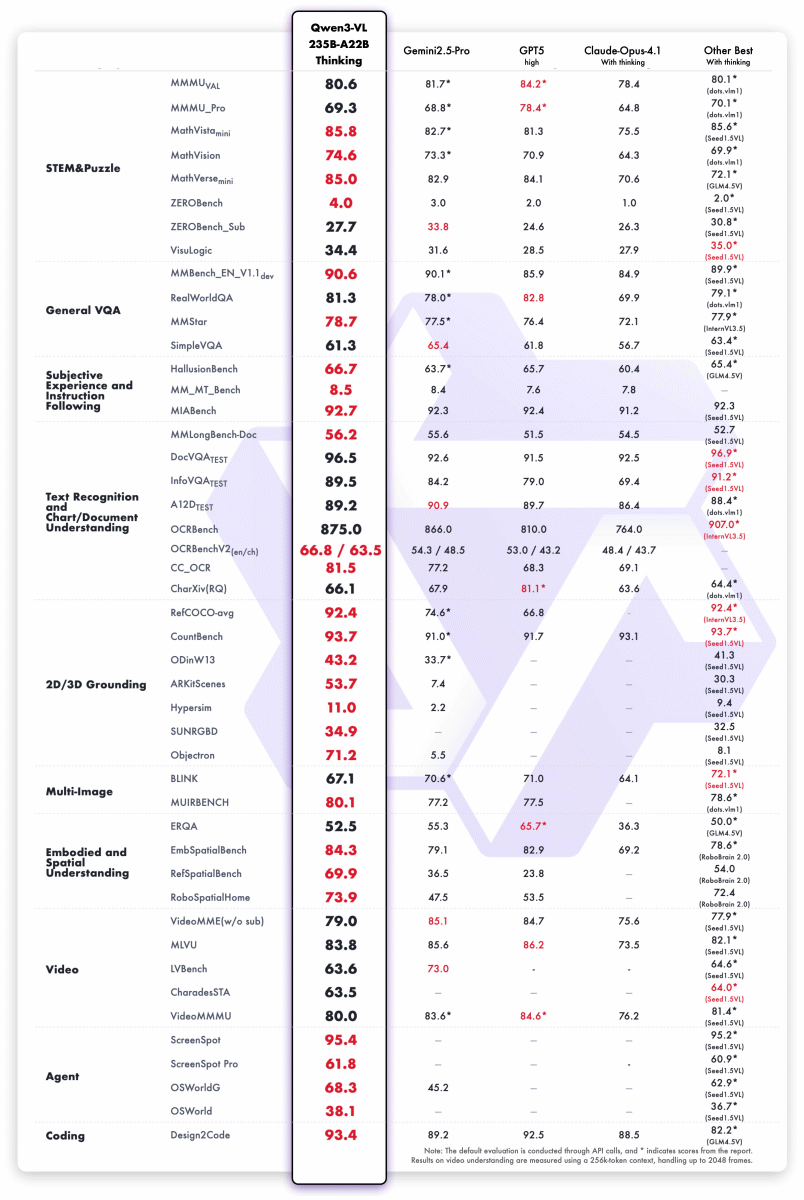
Qwen3-VL-235B-A22B-Instructのベンチマーク結果は以下の通り。オープンモデルながら、多くのテストでGemini-2.5-ProやGPT-5のスコアを上回っています。
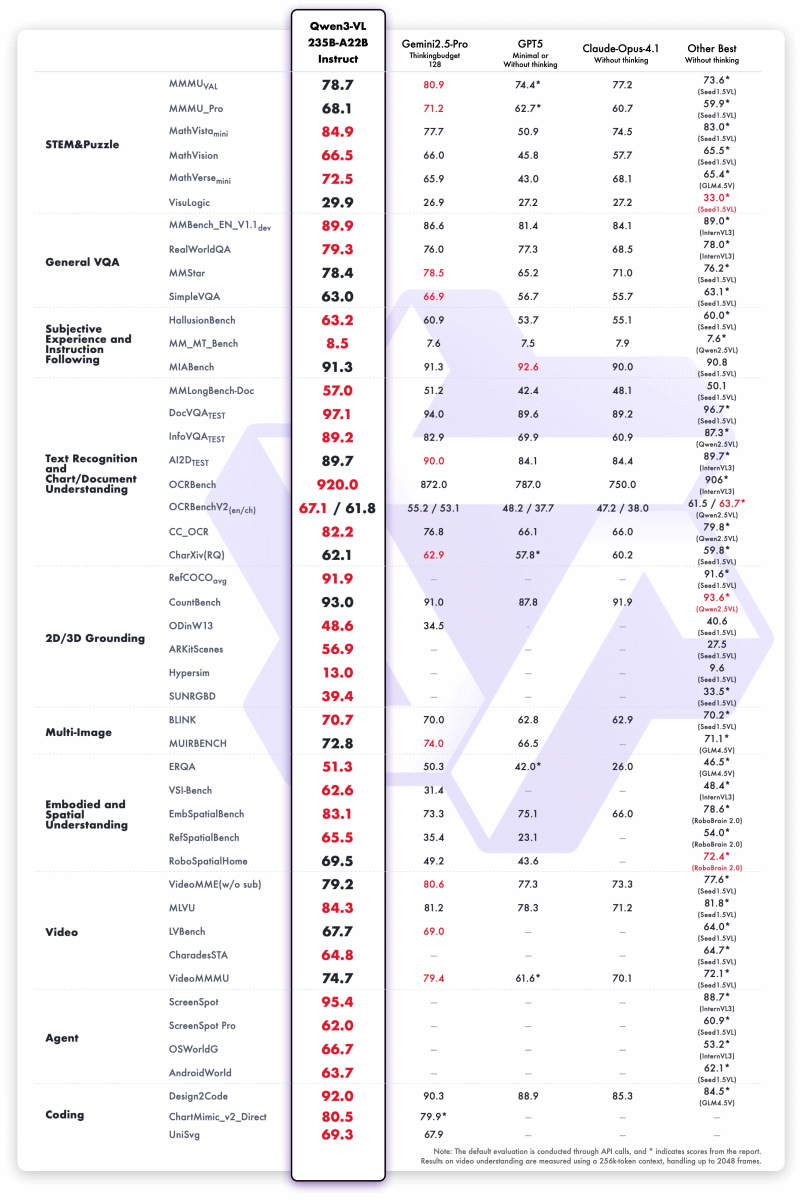
推論モデルのQwen3-VL-235B-A22B-ThinkingもGemini-2.5-ProやGPT-5を超える性能を示しました。
Qwenチームは動作例として「鬼滅の刃のキャラクター名を正確に認識する様子」を提示しています。

Qwen3-VLのモデルデータは以下のリンク先で公開されています。
Qwen3-VL – a Qwen Collection
https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
◆Qwen3-TTS
Qwen3-TTSは日本語を含む10言語に対応した音声生成モデルです。Qwen3-TTSでは入力された音声を感情表現を維持したまま他の言語に翻訳することが可能です。日本語への翻訳を含む動作例は以下の動画で確認できます。
Qwen3-TTS: Multi-timbre & Multi-lingual & Multi-dialect Speech Synthesis. – YouTube
https://www.youtube.com/watch?v=MC6s4TLwX0A
◆Qwen-Image-Edit-2509
Qwen-Image-Edit-2509は画像編集AIモデル「Qwen-Image-Edit」のアップデート版で、顔や製品の一貫性を維持する能力が向上しています。Qwen-Image-Edit-2509を用いた編集例は以下のリンク先で確認できます。
Qwen-Image-Edit-2509: Multi-Image Support, Improved Consistency
https://qwen.ai/blog?id=1675c295dc29dd31073e5b3f72876e9d684e41c6&from=research.research-list

◆Qwen3-LiveTranslate-Flash
Qwen3-LiveTranslateは日本語を含む18言語に対応したリアルタイム音声通訳モデルです。音声だけでなく「唇の動き」や「ジェスチャー」といった視覚的な要素も入力可能で、音声認識精度を向上させられます。
Qwen3‑LiveTranslate: Real‑Time Multimodal Interpretation — See It, Hear It, Speak It!
https://qwen.ai/blog?id=b2de6ae8555599bf3b87eec55a285cdf496b78e4&from=research.latest-advancements-list
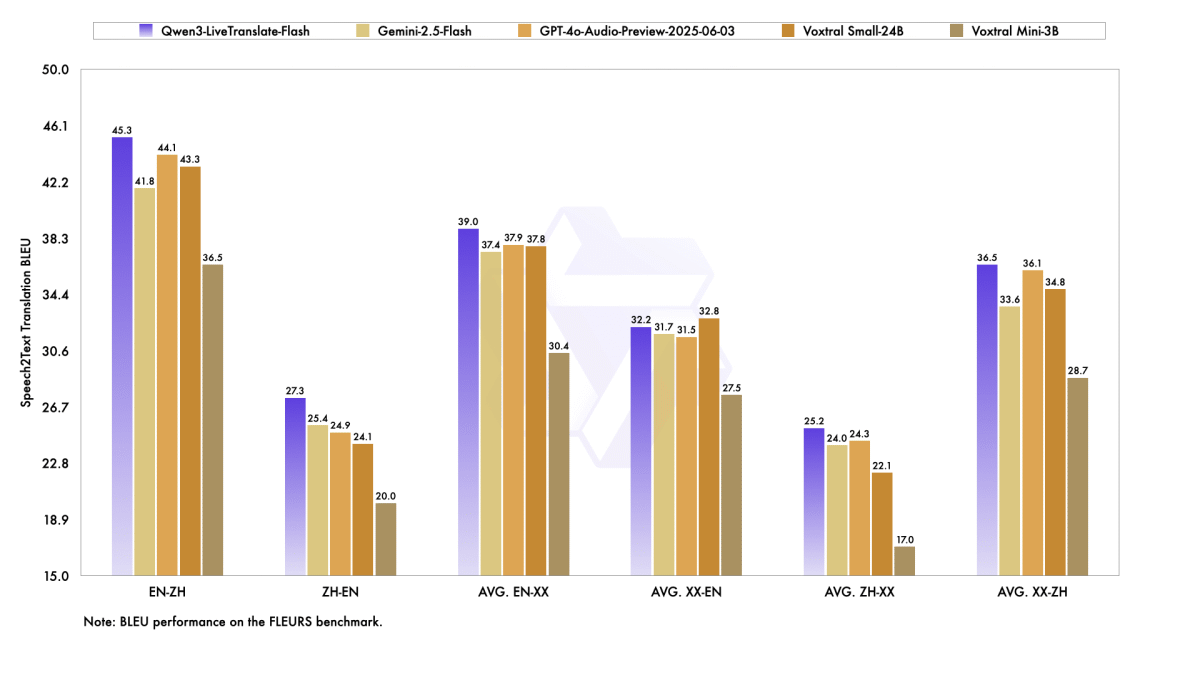
Qwenチームが実施したベンチマークテストでは、Qwen3-LiveTranslate-FlashはGemini-2.5-FlashやGPT-4o-Audio-Previewより高いスコアを記録しました。
◆Qwen3-Max
Qwen3-Maxは推論モデル「Qwen3シリーズ」の中で最上位のモデルです。
Qwen3-Max: Just Scale it
https://qwen.ai/blog?id=241398b9cd6353de490b0f82806c7848c5d2777d&from=research.latest-advancements-list

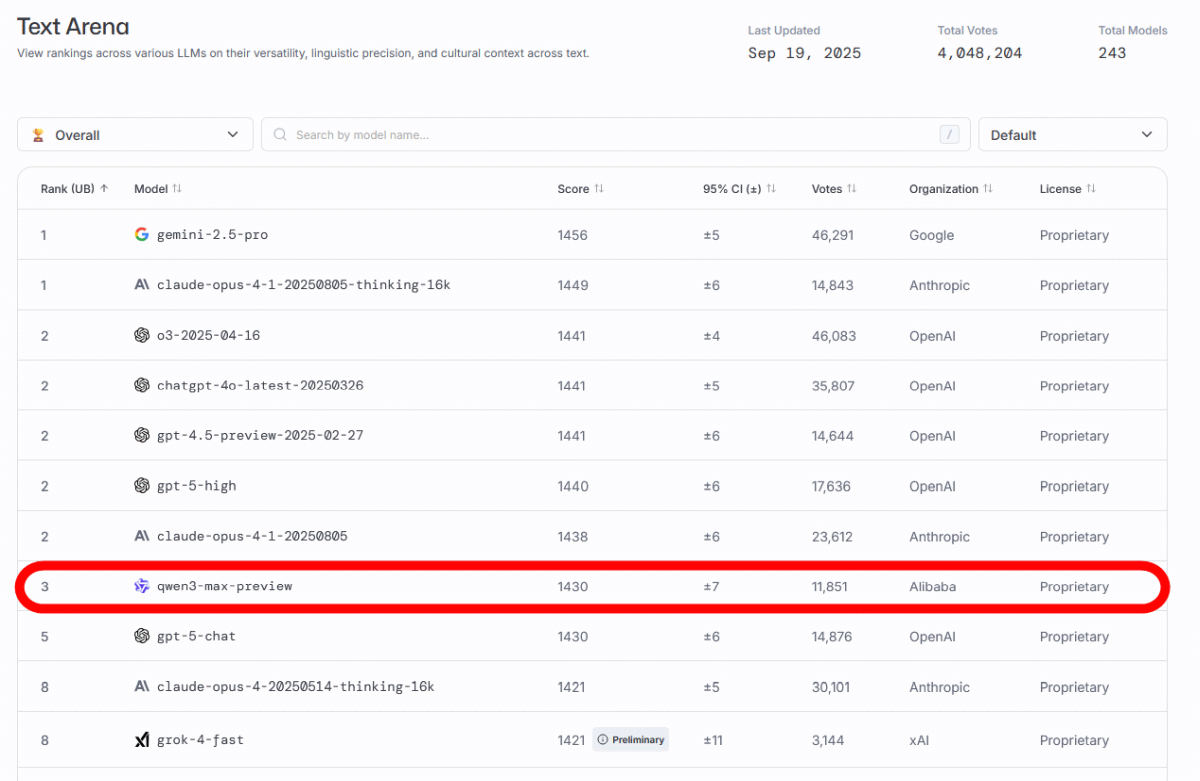
AIモデルの正体を伏せた状態で人間にテキスト生成性能を評価させる「Text Arena」では、Qwen3-MaxがGPT-5-Chatを抑えて3位にランクインしました。Qwen3-Maxは記事作成時点ではQwen Chatで利用可能となっており、近い内に一般公開される予定です。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。