

NVIDIAが数百万トークンの入力に対応するAI処理特化GPU「Rubin CPX」を2025年9月9日に発表しました。Rubin CPXは長編動画生成や長い文脈の処理を伴うコーディングタスクなどにおいて現行システムの設計限界を大きく超えるものだとアピールされています。
NVIDIA Unveils Rubin CPX: A New Class of GPU Designed for Massive-Context Inference | NVIDIA Newsroom
https://nvidianews.nvidia.com/news/nvidia-unveils-rubin-cpx-a-new-class-of-gpu-designed-for-massive-context-inference
NVIDIA Rubin CPX Accelerates Inference Performance and Efficiency for 1M+ Token Context Workloads | NVIDIA Technical Blog
https://developer.nvidia.com/blog/nvidia-rubin-cpx-accelerates-inference-performance-and-efficiency-for-1m-token-context-workloads/
NVIDIAによると、AIモデルは1時間の動画処理に対して最大100万トークンを必要とし、従来のGPU演算の限界に近づいているとのこと。今回発表されたRubin CPXはそのような限界を押し広げるもので、ビデオデコーダーとエンコーダー、長文脈推論処理を単一チップに統合し、動画検索や高品質な生成動画といったアプリケーションにおいて前例のない能力を実現するものになっているそうです。
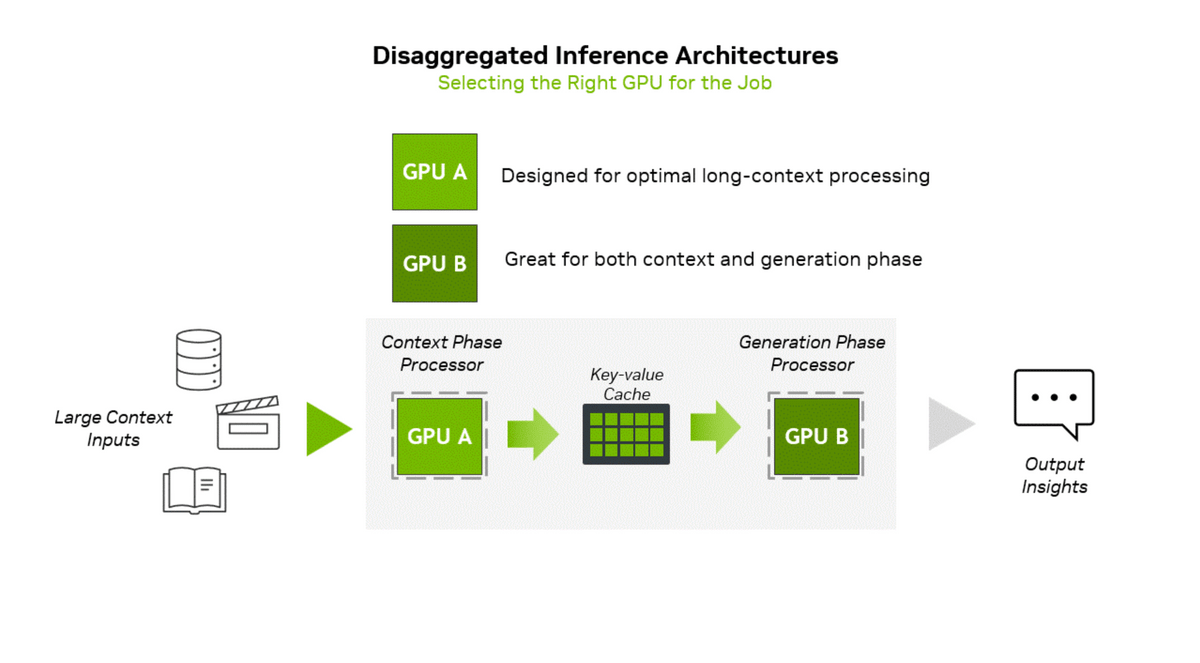
Rubin CPXは複雑なAI処理を行う「分散推論」というアプローチに対応するよう設計されたチップです。通常、AIにおける推論は文脈フェーズと生成フェーズという二つの異なるフェーズで構成されます。文脈フェーズは「大量の入力データを取り込み、分析して、最初のトークン出力結果を生成する」という役割から高スループット処理を必要とし、一方の生成フェーズはトークン単位の出力性能を維持するために高速なメモリ転送とNVLinkなどの高速相互接続に依存します。分散推論はこれらのフェーズを独立して処理するもので、演算リソースとメモリリソースの異なる2点で的を絞った最適化が可能となるものと説明されています。このような処理のニーズに対応したのがRubin CPXです。
また、Rubin CPXはNVIDIAの正確な低精度推論を実現する技術「NVFP4」を採用し、同技術により最大30ペタフロップスの演算性能を実現します。さらに、128GBのGDDR7メモリや、NVIDIA SMARTフレームワークなどを統合することで、AIワークロードの要求を高い効率性とROI(投資利益率)で満たすように設計されているとのこと。NVIDIAは「投資額1億ドルごとに50億ドルのトークン収益という、前例のない規模で収益化できます」と紹介しています。
さらに、8エクサフロップスのAI演算性能と100TBの高速メモリを1つのラックに搭載した「NVIDIA Vera Rubin NVL144 CPX」というプラットフォームも同時に発表されています。Rubin CPXはこのプラットフォーム内でNVIDIA Vera CPUおよびRubin GPUと連携して動作し、既存システムの「NVIDIA GB300 NVL72」と比較して7.5倍のAI性能を実現します。

NVIDIAのジェンスン・フアンCEOは、「Vera Rubinプラットフォームは、次世代の新カテゴリープロセッサであるRubin GPUおよびRubin CPXを導入し、AIコンピューティングの最先端領域で新たな飛躍を遂げます。RTXシリーズがグラフィックスと物理AIに革命をもたらしたように、Rubin CPXは数百万トークン規模の知識を同時に推論する大規模なコンテキスト処理で比類ない性能を実現します」と述べました。
Rubin CPXの提供は2026年末に始まる予定です。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。