

中国のAI企業であるDeepSeekがオープンウェイトモデル「DeepSeek-V3.1」を2025年8月21日にリリースしました。このモデルは、エージェントの時代に向けた第一歩として位置づけられており、推論モードと非推論モードを両立させて高速化を図るハイブリッドモデルとなっています。
DeepSeek-V3.1 Release | DeepSeek API Docs
https://api-docs.deepseek.com/news/news250821
Introducing DeepSeek-V3.1: our first step toward the agent era! ????
???? Hybrid inference: Think & Non-Think — one model, two modes
⚡️ Faster thinking: DeepSeek-V3.1-Think reaches answers in less time vs. DeepSeek-R1-0528
????️ Stronger agent skills: Post-training boosts tool use and…— DeepSeek (@deepseek_ai) August 21, 2025
DeepSeek-V3.1の主な特徴は、思考を行う「Think」モードと、行わない「Non-Think」モードの2つを1つのモデル内に持つハイブリッド推論スタイルです。Thinkモードは思考速度が向上しており、旧モデルのDeepSeek-R1-0528よりも短時間で回答を生成します。また、事前トレーニングにより、ツールの使用や複数ステップを要するエージェントタスクのスキルが強化されているとのこと。この新機能は、公式サイトのチャットで「DeepThink」ボタンを切り替えることで試用できます。
DeepSeek – Into the Unknown
https://chat.deepseek.com/
APIも更新され、「deepseek-reasoner」がThinkモード、「deepseek-chat」がNon-Thinkモードとして提供されます。両モデルともに128Kのコンテキスト長をサポートしており、さらにAnthropic APIフォーマットや、ベータAPIでの厳密な関数呼び出し(Strict Function Calling)にも対応しました。APIリソースも増強され、よりスムーズな利用体験が提供されます。
ツールとエージェントの機能もアップグレードされ、SWE-benchやTerminal-Benchといったベンチマークでより良い結果を記録しています。複雑な検索タスクにおける複数ステップの推論能力が強化され、思考の効率も大幅に向上しました。
ベンチマークスコアを見ると、SWE-bench Verifiedで66.0を記録し、DeepSeek-V3-0324の45.4やDeepSeek-R1-0528の44.6を上回りました。SWE-bench Multilingualでは54.5、Terminal-Benchでは31.3を達成しています。
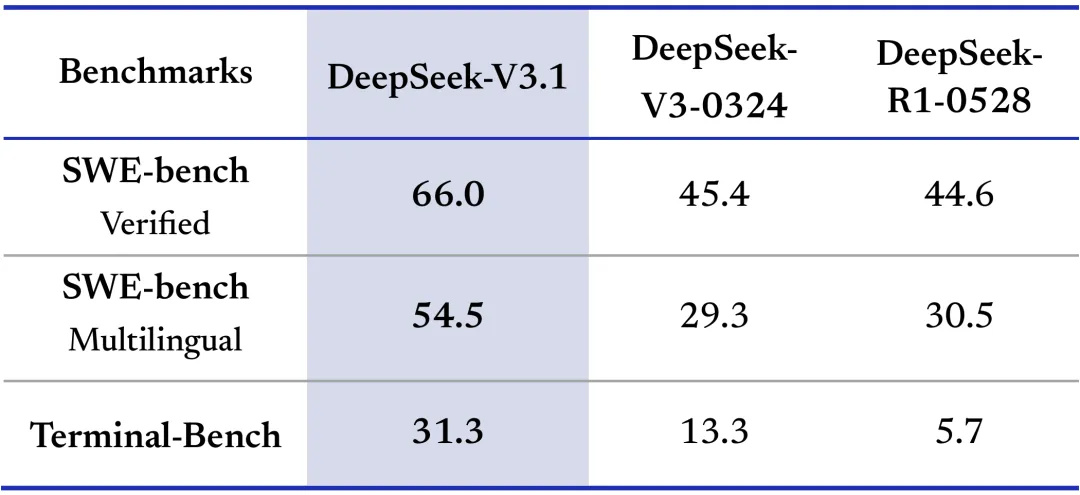
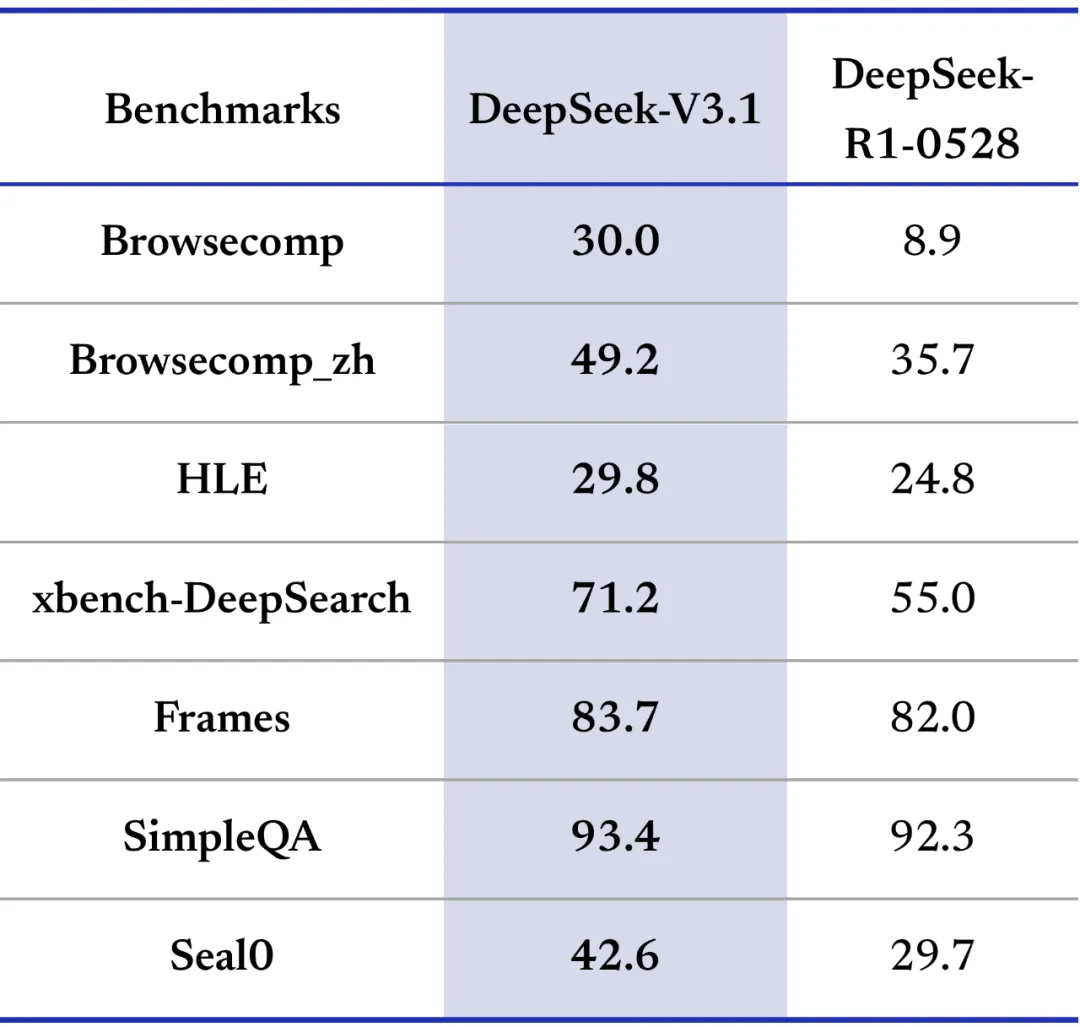
その他のベンチマークにおいても、BrowseCompで30.0、BrowseComp_zhで49.2、Humanity’s Last Examで29.8、xbench-DeepSearchで71.2など、多くの項目でDeepSeek-R1-0528のスコアを上回る結果を示しました。
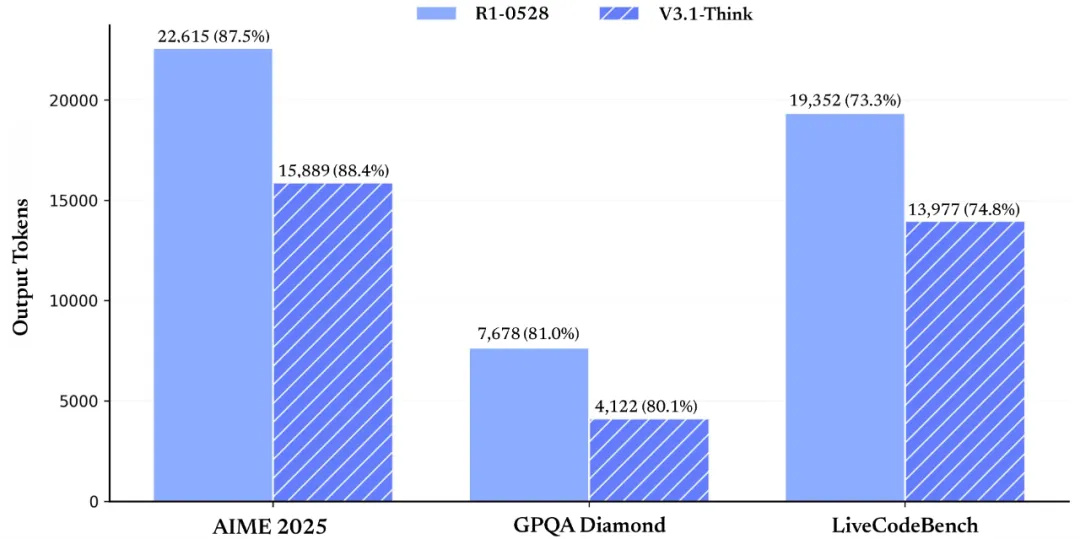
思考効率の向上は出力トークン数にも反映されており、DeepSeek-V3.1のThinkモードはDeepSeek-R1-0528と比較して、AIME 2025では22,615から15,889へ、GPQA Diamondでは7,678から4,122へ、LiveCodeBenchでは19,352から13,977へと、それぞれ出力トークン数を削減しています。
DeepSeek-V3.1のモデルデータおよびトークナイザー、チャットテンプレートはHugging Faceで公開されています。また、モデルの基盤となるDeepSeek-V3.1-Baseも同時に公開されています。このDeepSeek-V3.1-BaseはV3をベースに長文コンテキスト拡張のため8400億トークンの継続的な事前学習を行ったものだそうです。
deepseek-ai/DeepSeek-V3.1-Base · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
deepseek-ai/DeepSeek-V3.1 · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V3.1
DeepSeek-V3.1 APIの料金は、入力が100万トークンあたり0.07ドル(約11円)~0.56ドル(約80円)、出力が100万トークンあたり1.68ドル(約250円)に設定されています。

この記事のタイトルとURLをコピーする
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。