

2025年8月5日、OpenAIが重み(ウェイト)を公開したモデルの「gpt-oss」を発表しました。このモデルは誰でも無料でダウンロード可能な上、比較的軽量なので個人のPCでもローカル実行することが可能な点が特徴です。実際にgpt-ossをPCに導入してみました。
OpenAI gpt-oss · Ollama Blog
https://ollama.com/blog/gpt-oss
OpenAI’s New Models on RTX GPUs | NVIDIA Blog
https://blogs.nvidia.com/blog/rtx-ai-garage-openai-oss/
gpt-ossを使うためのツールの1つが「Ollama」です。OllamaはOpenAIとの提携を果たしており、Ollamaを通じてgpt-ossの機能を利用できます。
さらに、OllamaとOpenAIはNVIDIAとも協力しており、NVIDIAのGPU「RTX」シリーズだとgpt-ossモデルの機能を適切に活用できるようになるとのことです。
gpt-ossは比較的軽量とは言っても小さいモデル「gpt-oss-20b」は16GB以上のVRAM容量または統合メモリが最適とされていて、RTXシリーズだと「RTX 4080」や「RTX 5070 Ti」などが必要になります。VRAMが不足している場合はCPUにオフロードできるとのことですが、実行速度は遅くなる可能性があります。フルサイズモデルの「gpt-oss-120b」は60GB以上のVRAMまたは統合メモリが最適とされています。
今回はM4搭載MacBook Airに導入してみました。メモリは32GBです。

まずは公式サイトからOllamaのmacOS版をダウンロードします。
ダウンロードしたら、アイコンを左から右にドラッグしてインストール。
インストールしたOllamaを開きます。
使えるモデル一覧の中に「gpt-oss-20b」と「gpt-oss-120b」が組み込まれていました。
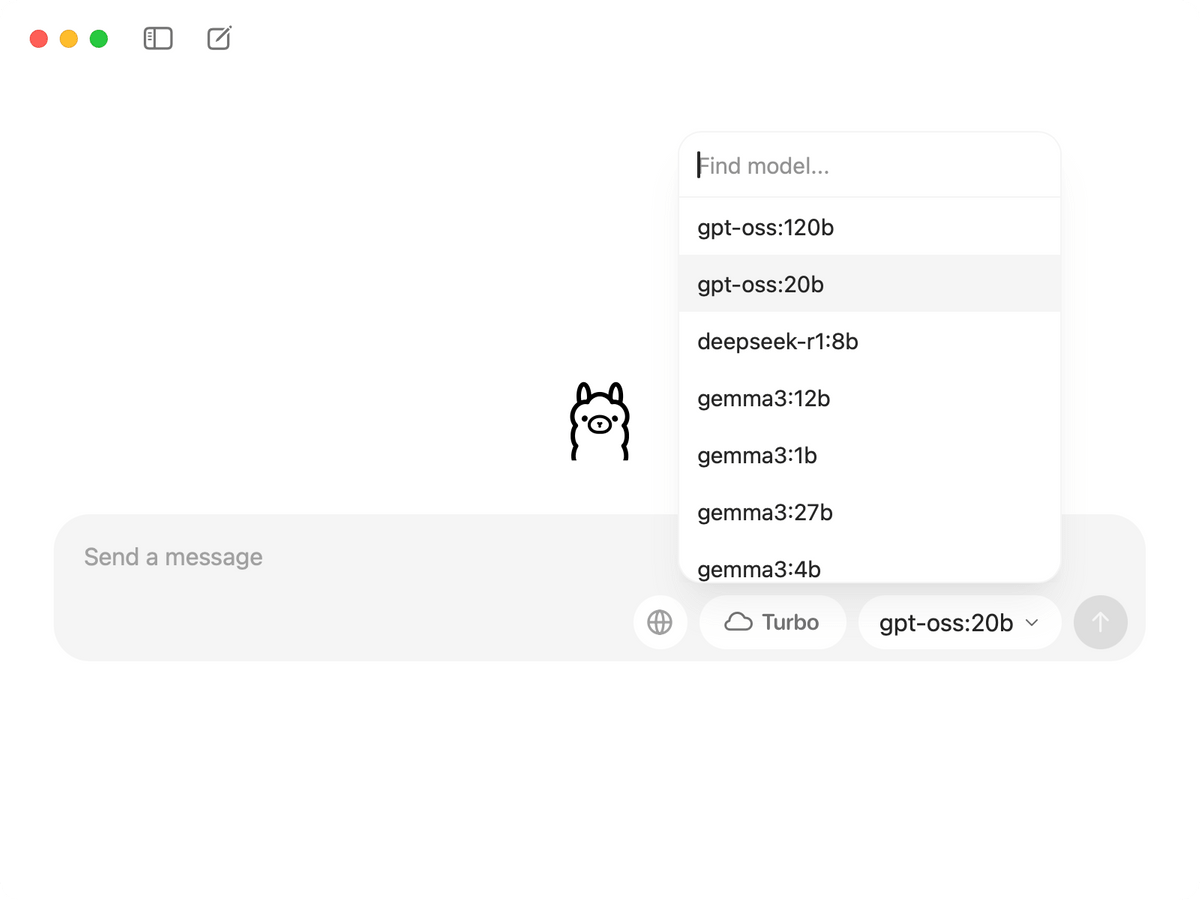
モデルを「gpt-oss-20b」に設定したままプロンプトを入力すると、最初にモデルのダウンロードが始まりました。サイズは12.8GBです。
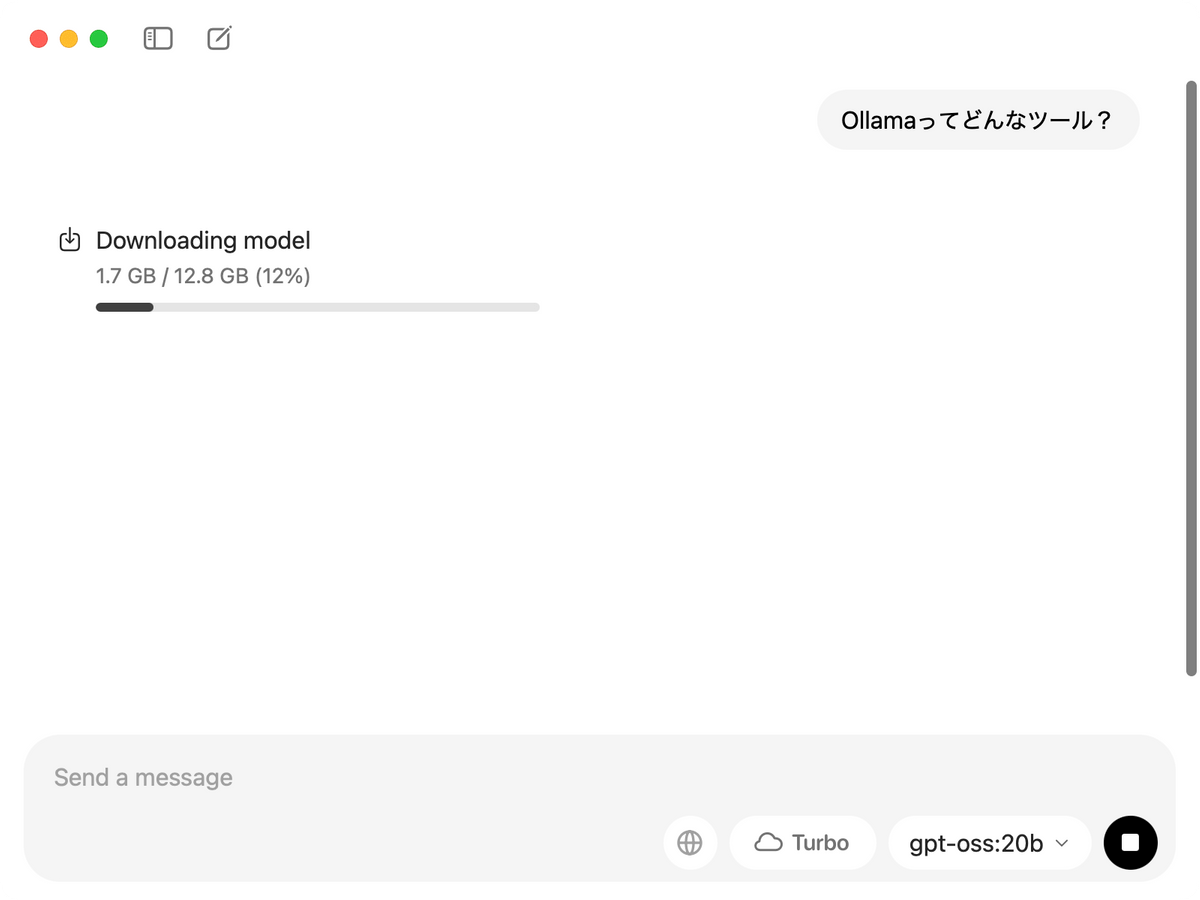
数分でダウンロードが完了し、プロンプトに対する出力を始めました。
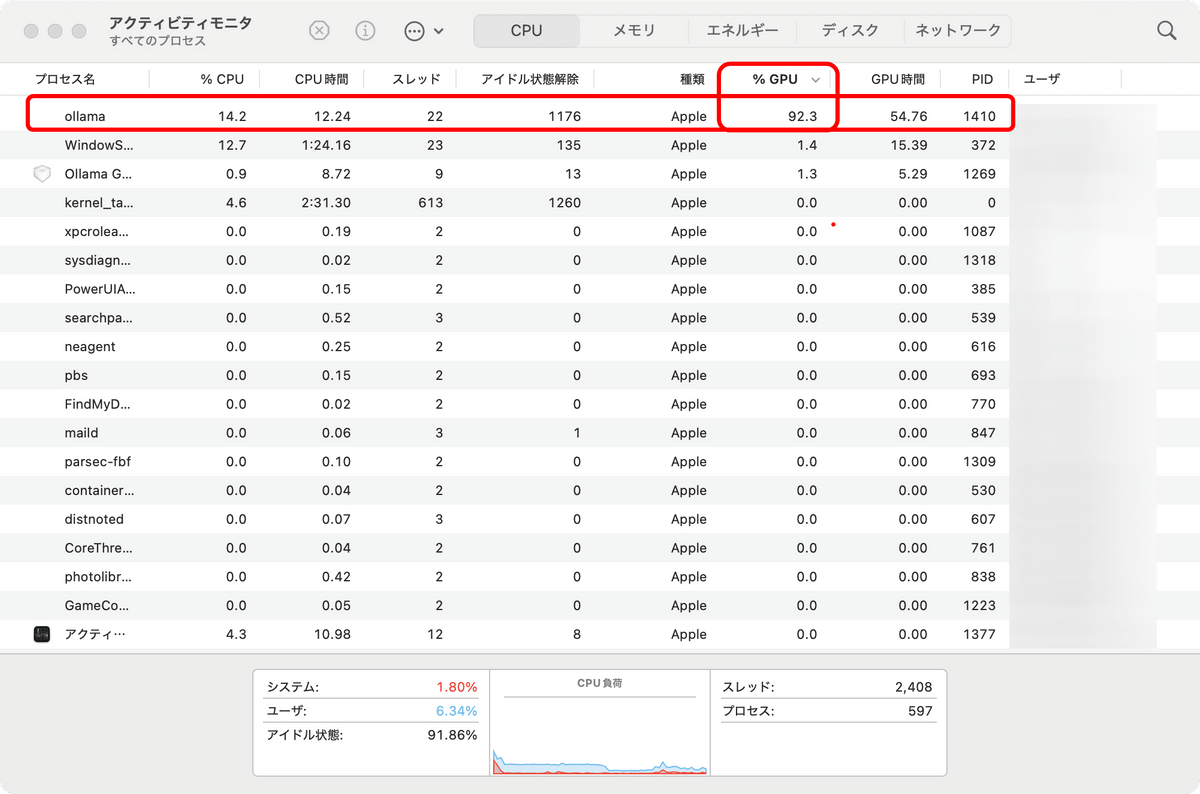
動作中はGPUを90%以上使用する様子がアクティビティモニタで観察できます。
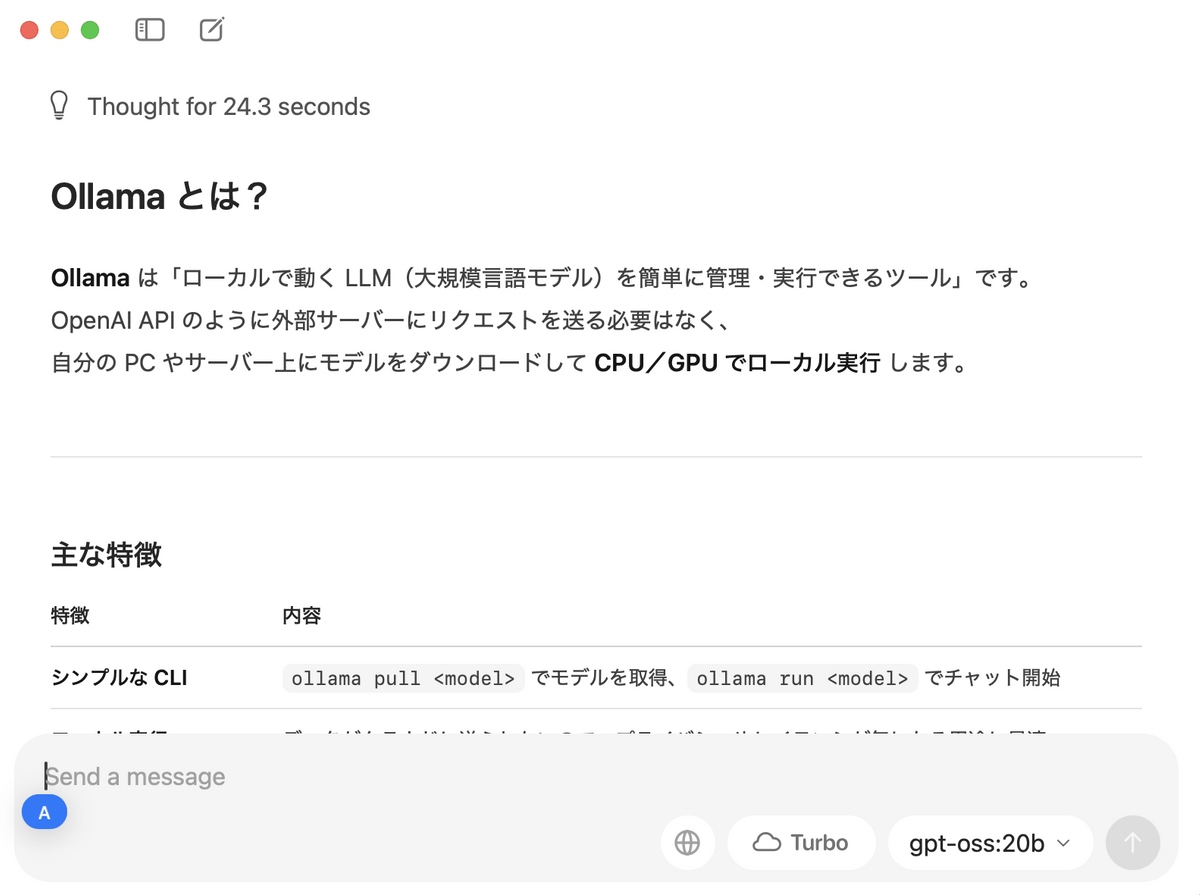
gpt-ossは推論モデルで、推論中の処理も出力されます。
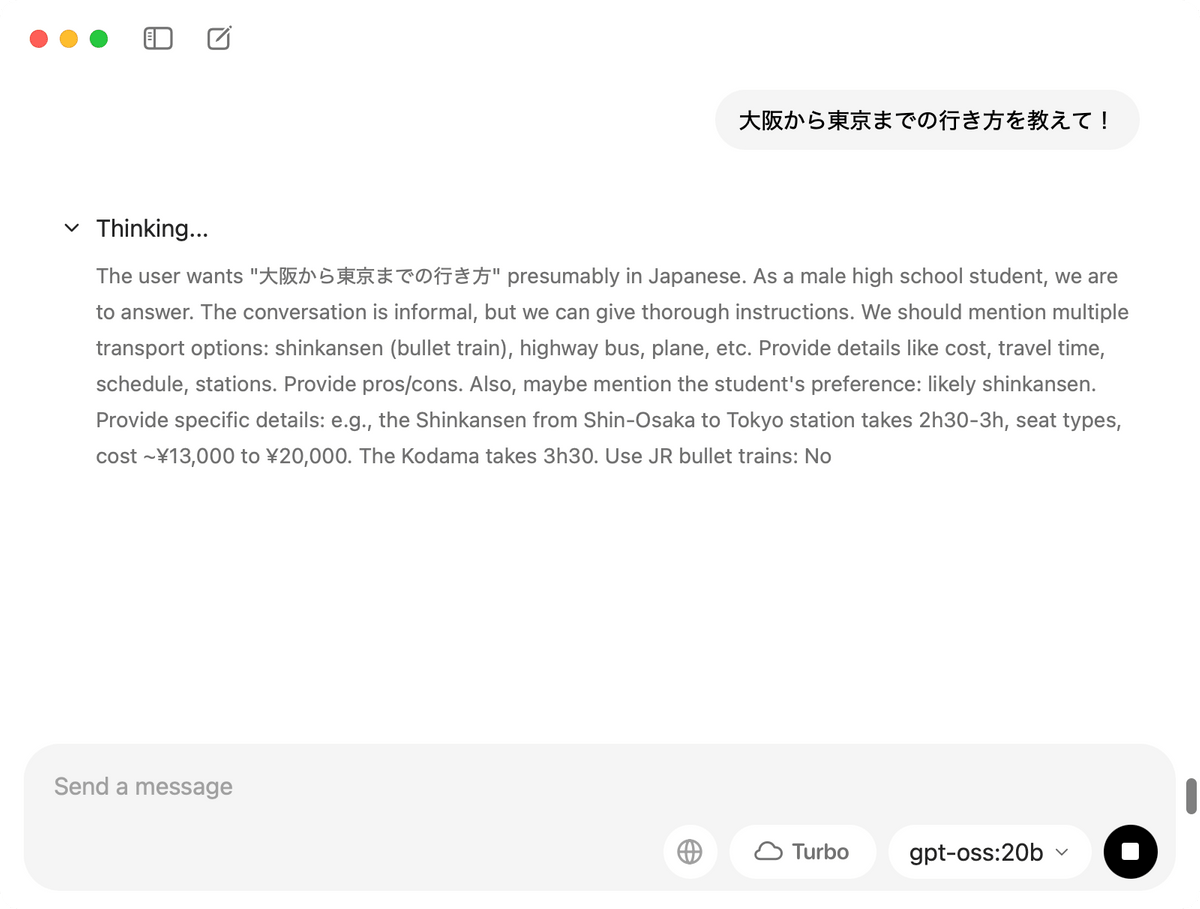
大阪から東京までの行き方を尋ねたところこんな感じの出力になりました。JR東海の「いっぷ」など存在しない名称を言っています。

ターミナルを使ってチャットする方法はOpenAIのドミニク・クンデル氏が解説しています。
How to run gpt-oss locally with Ollama
https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。