
中国のAlibabaが開発する大規模言語モデル(LLM)の「Qwen3」ファミリーに、パラメーターサイズ2350億、アクティブパラメーター数220億の「Qwen3-235B-A22B-Thinking-2507」が追加されました。「Qwen3-235B-A22B-Thinking-2507」は「Qwen3-235B-A22B」の推論能力の質と深さの両方を向上させた、最も先進的な推論モデルです。
Qwen3-235B-A22B-Thinking-2507
https://simonwillison.net/2025/Jul/25/qwen3-235b-a22b-thinking-2507/
It’s Qwen’s summer: Qwen3-235B-A22B-Thinking-2507 tops charts | VentureBeat
https://venturebeat.com/ai/its-qwens-summer-new-open-source-qwen3-235b-a22b-thinking-2507-tops-openai-gemini-reasoning-models-on-key-benchmarks/
Alibabaは2025年4月末に、Qwen3ファミリーを発表しました。フラグシップモデルの「Qwen3-235B-A22B」は、パラメーター数が2350億、アクティブパラメーター数が220億となっており、コーディング・数学・一般機能などのベンチマーク評価において、DeepSeek-R1、o1、o3-mini、Grok-3、Gemini-2.5-Proといった他社製の最先端AIモデルと比較しても、競争力のある結果を残しています。

この「Qwen3-235B-A22B」の推論能力を高めたものが「Qwen3-235B-A22B-Thinking-2507」です。「Qwen3-235B-A22B-Thinking-2507」は「Qwen3-235B-A22B」と比べて、論理的推論・数学・科学・コーディング・一般機能において人間の専門知識を必要とする学術ベンチマークを含む推論タスクのパフォーマンスが大幅に向上しており、オープンソースの推論モデルの中でも最も優れたパフォーマンスを実現しています。ただし、推論能力を向上させた影響で、「Qwen3-235B-A22B-Thinking-2507」は思考時間が長くなっているため、複雑な推論課題に使用することが推奨されています。
🚀 We’re excited to introduce Qwen3-235B-A22B-Thinking-2507 — our most advanced reasoning model yet!
Over the past 3 months, we’ve significantly scaled and enhanced the thinking capability of Qwen3, achieving:
✅ Improved performance in logical reasoning, math, science & coding… pic.twitter.com/vO6UHlW7pf— Qwen (@Alibaba_Qwen) July 25, 2025
以下は複数のベンチマークテストで、推論モデルの「Qwen3-235B-A22B-Thinking-2507」(赤色)「Qwen3-235B-A22B-Thinking」(青色)「Gemini 2.5 Pro」(灰色)「OpenAI o4 mini」(濃茶色)「DeepSeek R1 0528」(薄茶色)を比較したグラフ。生物学・物理学・化学関連のベンチマークテストがGPQA、数学関連のベンチマークテストがAIME25、コーディング関連のベンチマークテストがLiveCodeBench v6、推論能力と高度な専門知識に関するベンチマークテストがHLEです。
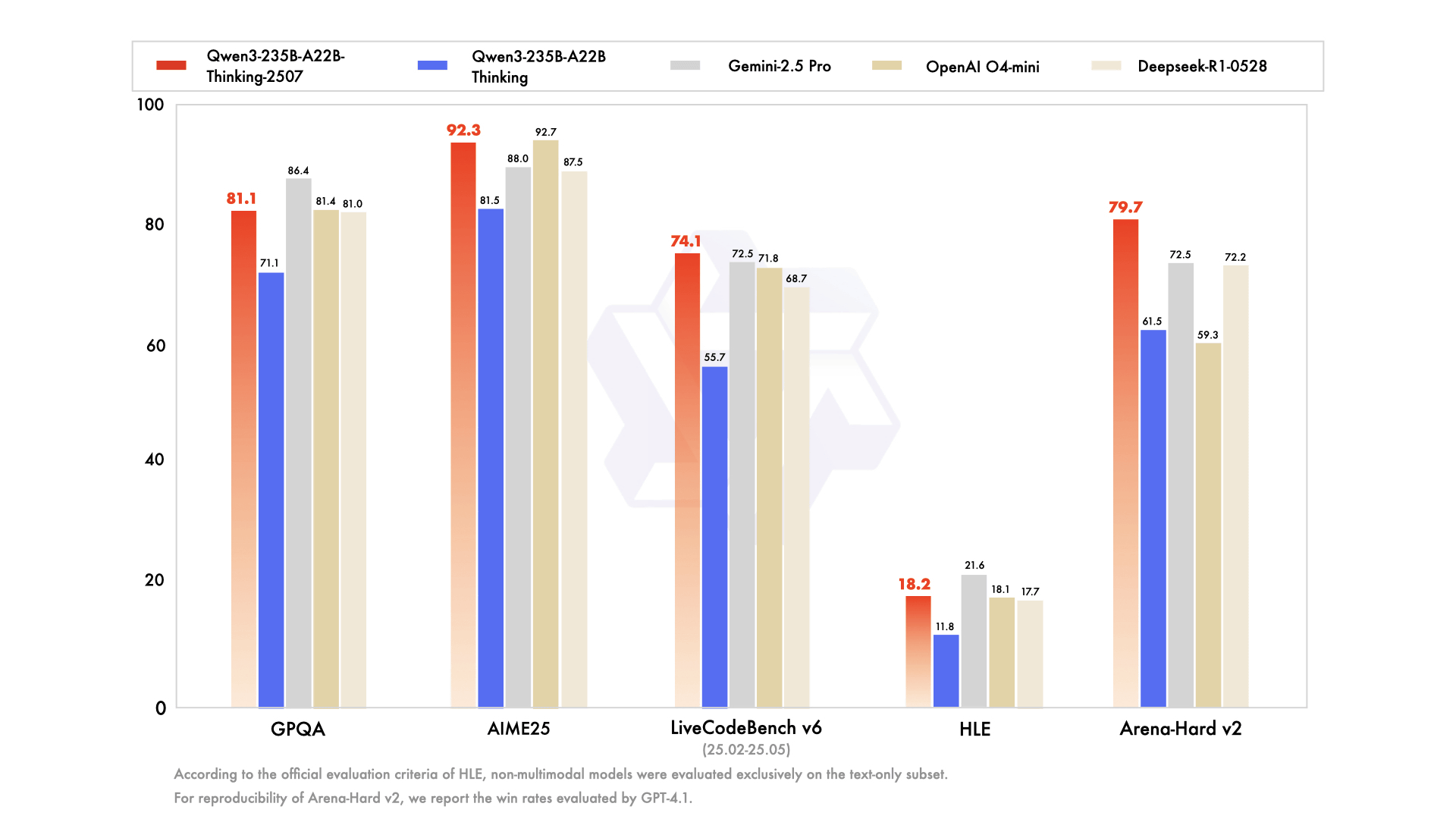
「Qwen3-235B-A22B-Thinking-2507」のベンチマークテストの結果について、コロンビア大学のソフトウェアエンジニアであるDavid Hendrickson氏は、「中国からの勝利が続々と生まれています。彼らは今、オープンソース言語モデルの勝者です。この新しいモデルであるQwen3-235B-A22B-Thinking-2507は、最も高性能なオープンソース推論モデルです。コンテキスト長13万のモデルで、コンテキスト長12万のo1、o3-mini、Opus4、Flash 2.5をLiveBenchにおいて上回っています」と指摘。
The wins keep coming out of China. They are now the champions of Open-Source language models. This new model, Qwen3-235B-A22B-Thinking-2507, is the most performant open-source thinking model. w/130K context it even beats O1, O3-mini, Opus4, Flash 2.5 @ 120K context in LiveBench https://t.co/jpouEiBy4s pic.twitter.com/sMHl7tV8JC
— David Hendrickson (@TeksEdge) July 25, 2025
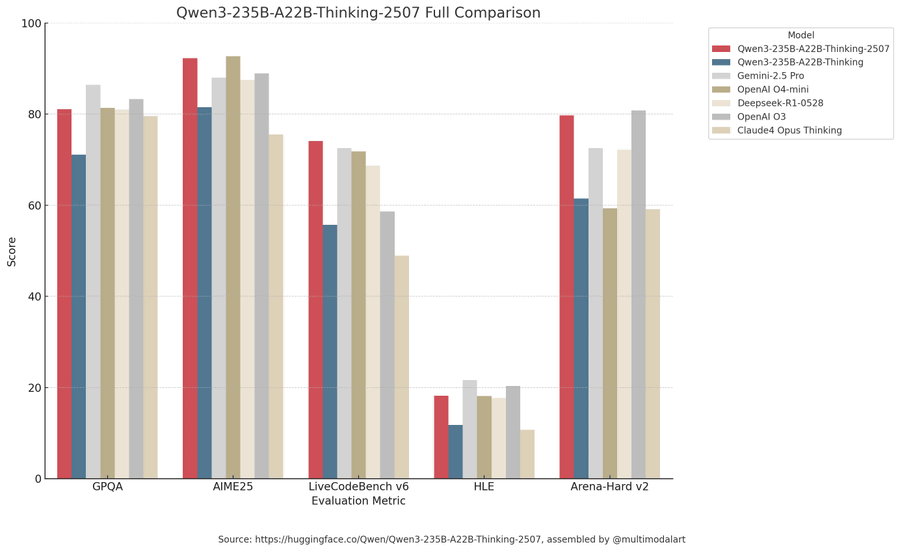
Alibabaが公開したベンチマーク結果を比較するグラフには、Claude Opus 4 Thinking(茶色)とOpenAI o3(濃灰色)のベンチマーク結果が含まれていなかったため、これを比較するグラフをapolinario氏が作成しています。
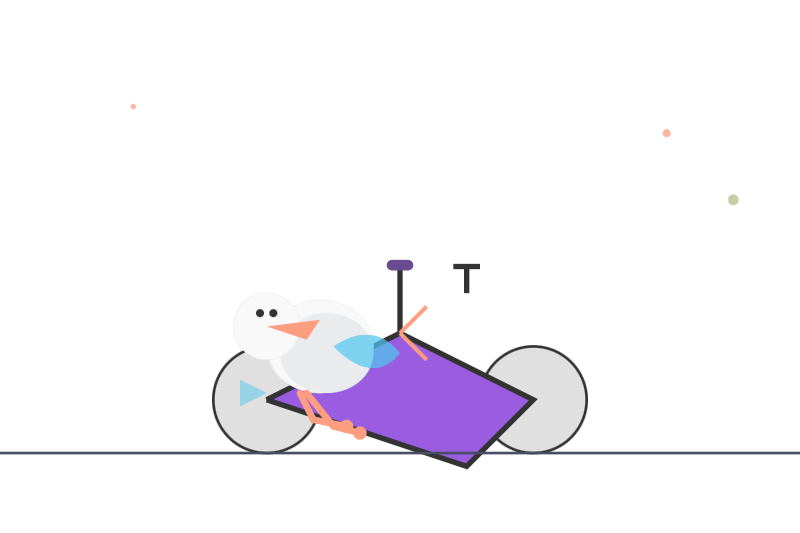
独自のAIベンチマークである「自転車に乗ったペリカンを描く」を実施しているエンジニアのサイモン・ウィリソン氏が、「Qwen3-235B-A22B-Thinking-2507」に「自転車に乗ったペリカン」を描かせたところ、思考に166秒もかかったと記しています。なお、生成された「自転車に乗ったペリカン」は以下です。
「Qwen3-235B-A22B-Thinking-2507」はAlibaba Cloudで利用可能です。
また、Hugging Faceでも公開されています。
Qwen/Qwen3-235B-A22B-Thinking-2507 · Hugging Face
https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507
この記事のタイトルとURLをコピーする
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。