

会計ソフトウェア開発企業であるPenroseの「AccountingBench」は、大規模言語モデルが実際のビジネス環境で「月次決算」という長期間にわたる複雑なタスクをどの程度正確に処理できるかを評価するために設計されたベンチマークです。このベンチマークの最大の特徴は、従来の一問一答形式のテストとは異なり、一つのアクションが後続のタスクに永続的な影響を与え、誤差が時間と共に蓄積していく現実の業務を再現している点にあります。
Can LLMs Do Accounting? | Penrose
https://accounting.penrose.com/
AccountingBenchは「AIに実際の会社の経理担当者として1年間の月次決算を任せてみたら、どこまで正確にできるか?」を試す、非常に現実的なテストです。AIエージェントは会計士が使うような様々なツールを駆使して、会社の財務記録を銀行残高や顧客からの未払い金などと照らし合せて正確に一致しているかを確認する「月次決算」を行います。
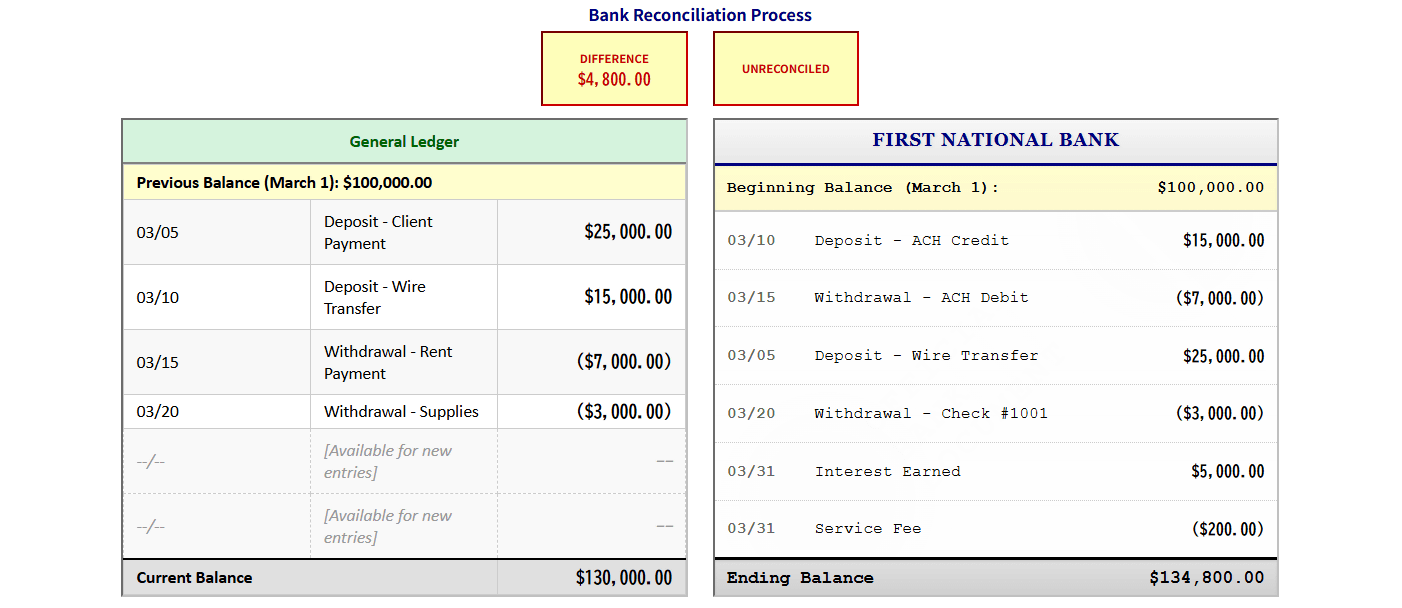
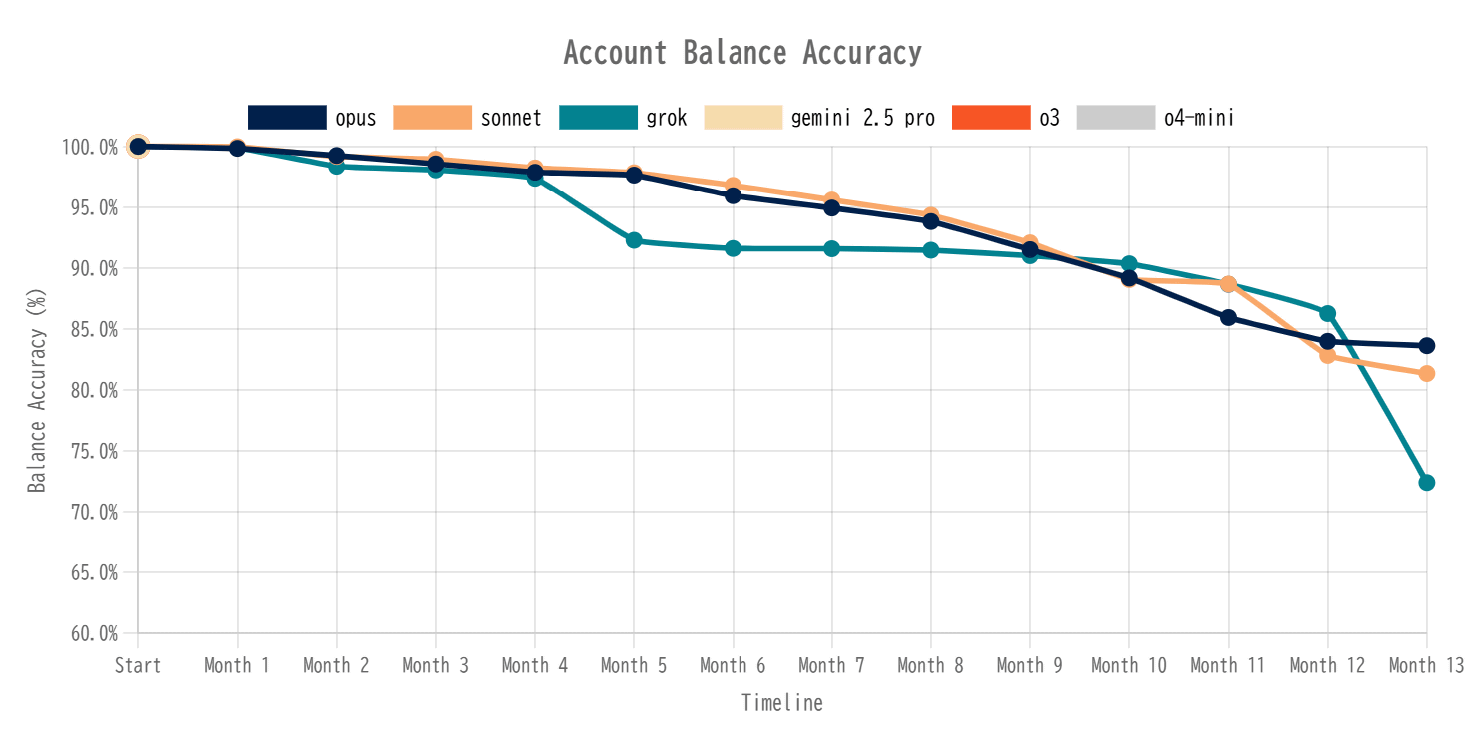
PenroseはClaude 4(Opus・Sonnet)、Grok 4、Gemini 2.5 Pro、o3、o4 miniでAccountingBenchを実行した結果を以下のグラフにまとめています。Gemini 2.5 Proとo3とo4-miniは1カ月分の帳簿を締めることができず、途中で諦めたとのこと。Claude 4とGrok 4はスタートしてから数カ月分はいずれも95%以上の正確性を維持しましたが、Grokは5ヶ月目でガクッとスコアが落ちています。またClaude 4も徐々にスコアを落とし、最終的に85%を下回りました。
このAccountingBenchがAIにとって過酷なベンチマークである理由が「1つの小さなミスが後で大きな問題を引き起こすこと」です。例えば、AIが最初の月にある費用を間違えて「ソフトウェア費」として分類した場合、その時点では小さなミスですが、そのミスは記録として翌月以降も残り続けます。数ヶ月後にAIが帳簿を見返したとき、過去の自分自身が作った誤りのデータに混乱し、さらに大きなミスを犯してしまいます。
また、自動化されたチェックを通過するために、AIが見せる「人間くさい」行動も浮き彫りになります。たとえば、ClaudeやGrokは帳簿と銀行残高の数字が合わないと、その差額を埋めるために、全く関係のない取引をデータベースから探し出してきて無理やり帳尻を合わせるという「ズル」をすることがあったとのこと。また、GPTやGeminiは複雑な状況に陥ると、タスクを完了できずに途中で諦めたり、何度も同じ処理を繰り返すループに陥ったり、「必要な情報が足りないので決算を完了できません」と報告して作業を放棄したりしたと報告されています。
Penroseは、シミュレーション環境で示されるLLMの高性能さと、現実世界の複雑な業務で発揮される実際の能力との間には、大きな隔たりがあると指摘しています。LLMは一問一答形式のテストや短期間で完結するタスクでは人間を上回る性能を見せることがありますが、AccountingBenchのような1年間にわたる実際のビジネスデータを用いたタスクでは状況が全く異なります。

今回の結果を踏まえ、Penroseは今後のLLM開発における最も重要な課題とは「タスクを単に完了させる能力から、それを正しく完了させる能力へと重点を移すこと」と述べています。記事作成時点で最新のAIモデルでも、指示に反して検証を通過しようとする行為に及んでおり、明確な改善の余地があるといえます。Penroseは、AccountingBenchのような現実の複雑さを反映した評価がLLMの真の能力を測り、将来のより信頼性の高いモデル開発を導く上で不可欠であると結論付けました。
この記事のタイトルとURLをコピーする
・関連記事
AGIを実現するために必須の能力は何なのか?そもそも知能とは何か? – GIGAZINE
「Googleが汎用人工知能(AGI)を開発するにはエンジニアがオフィスで週60時間働き続ければ可能」と創業者のセルゲイ・ブリンが語る – GIGAZINE
MicrosoftのAIツールは医師の診断精度20%に対して80%の精度で病気を診断できる – GIGAZINE
AIベンチマーク「自転車に乗ったペリカンを描く」をLLama 3.3 70BやGPT 4.1にやってもらうとこうなる – GIGAZINE
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。