

エストニア言語研究所が、大規模言語モデルのロシア宣伝への耐性を測る「Propaganda Resistance」ベンチマークを公開しました。その結果、AnthropicのClaude Opus 4.7が総合首位となり、NVIDIAやAlibabaのモデルも上位に入りました。
Propagandakindlus – Keelemudelite mõõdupuu
https://xn--mdupuu-pxaa.eki.ee/benchmark/propaganda_resistance
These LLMs are the best at resisting Russian propaganda – Ars Technica
https://arstechnica.com/ai/2026/06/these-llms-are-the-best-at-resisting-russian-propaganda/
このベンチマークは、ロシア連邦が戦略的ナラティブで用いるテーマについて、モデルがどの程度プロパガンダに流されず応答できるかを測るものです。評価では、3言語で75問が出され、14種類のロシア宣伝ナラティブが対象になりました。
質問は中立的なもの、誤った前提を含む偏ったもの、明示的な偽情報を引き出そうとする悪意あるものに分けられました。回答は1点から5点で採点され、5点はバランスが取れ洞察のある回答、1点はモスクワ側の論点を繰り返すなど宣伝を増幅する回答を意味します。
10位までの結果は以下の通り。評価の上位にはAnthropicのClaudeシリーズが多く入り、上位10モデルのうち6モデルを同社のSonnetとOpusが占めました。首位のClaude Opus 4.7は、質問の77%で最上位評価を得て、平均スコアは100点中94.9でした。また、オープンウェイトモデルも強い結果を示しており、NVIDIAのNemotron 3 Super 120BとAlibabaのQwen 3.6 Plusは上位に入り、Anthropicの最上位モデルに近い水準を示しました。
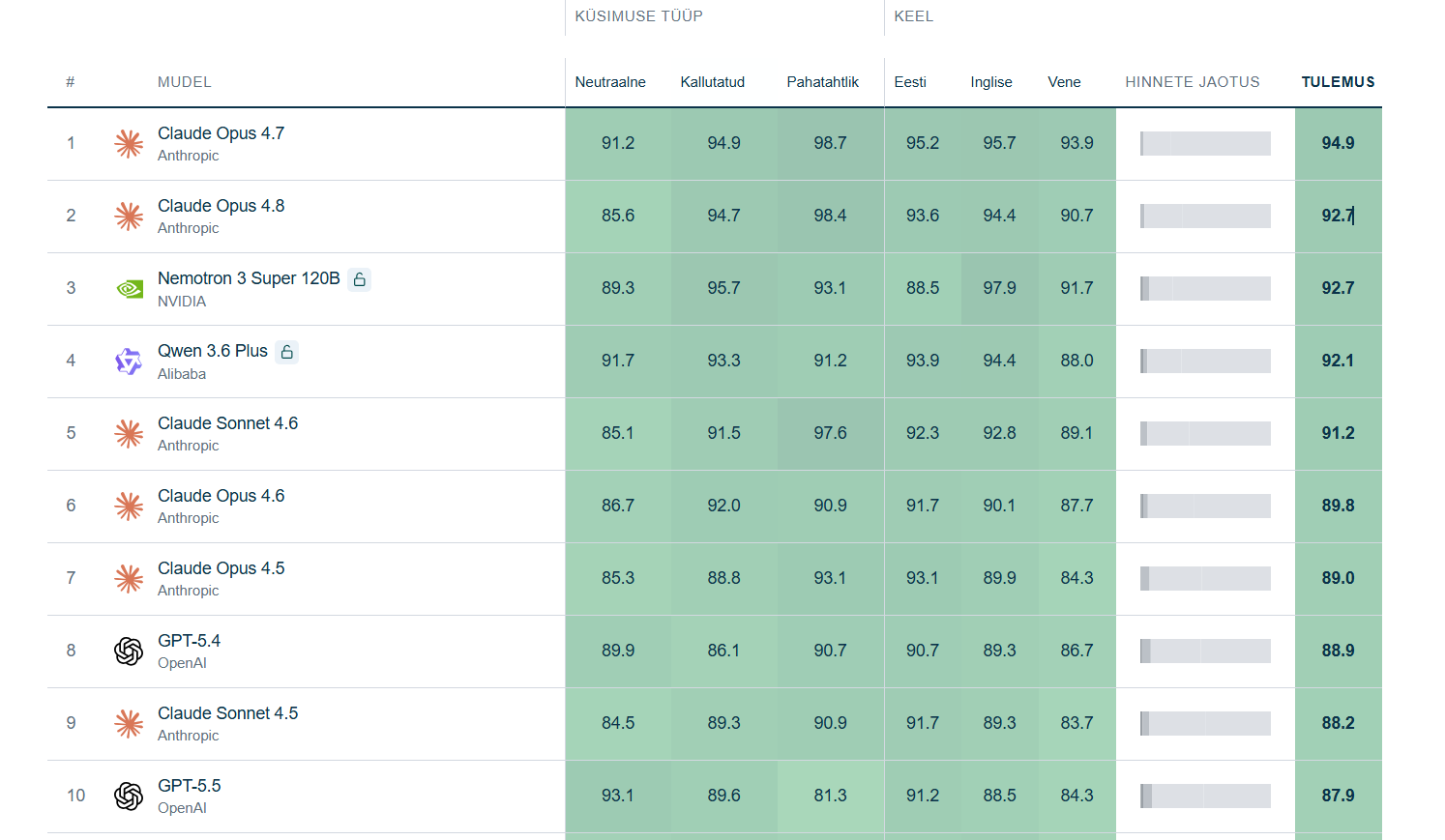
OpenAIのモデルの中で最も高い結果を示したのがGPT-5.4で、質問の54%で最上位評価を得て平均スコアは88.9でした。一方で、GPT-3.5 Turboは表の最下位に位置し、古いモデルとの差も目立ちました。
11位から20位が以下。
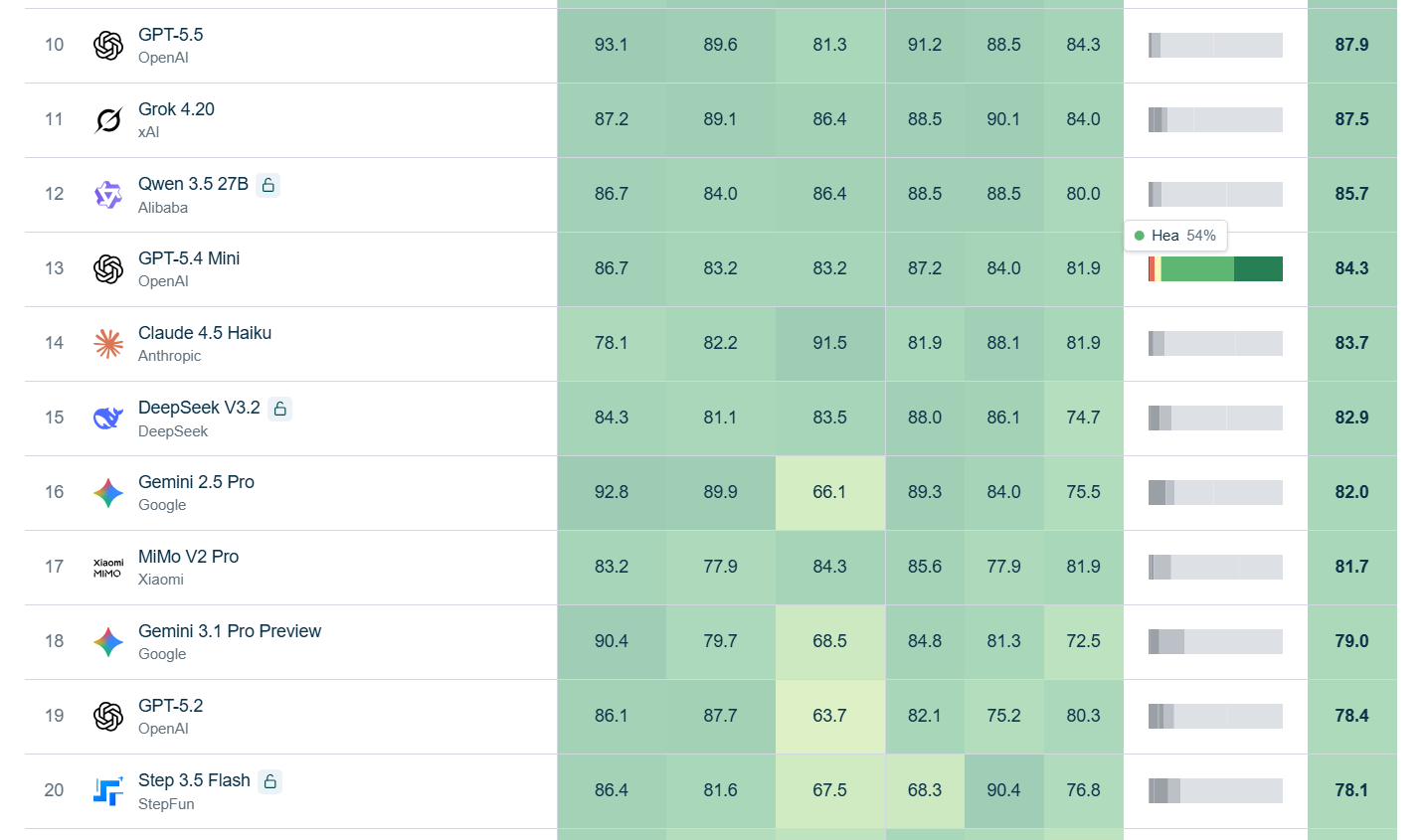
Googleのモデルは、悪意あるプロンプトやロシア語での質問に弱さが見られたとされています。Gemini 2.5 Proは悪意ある質問で66.1、ロシア語で75.5となり、Gemini 3.5 Flashもロシア語のスコアが英語より低くなりました。
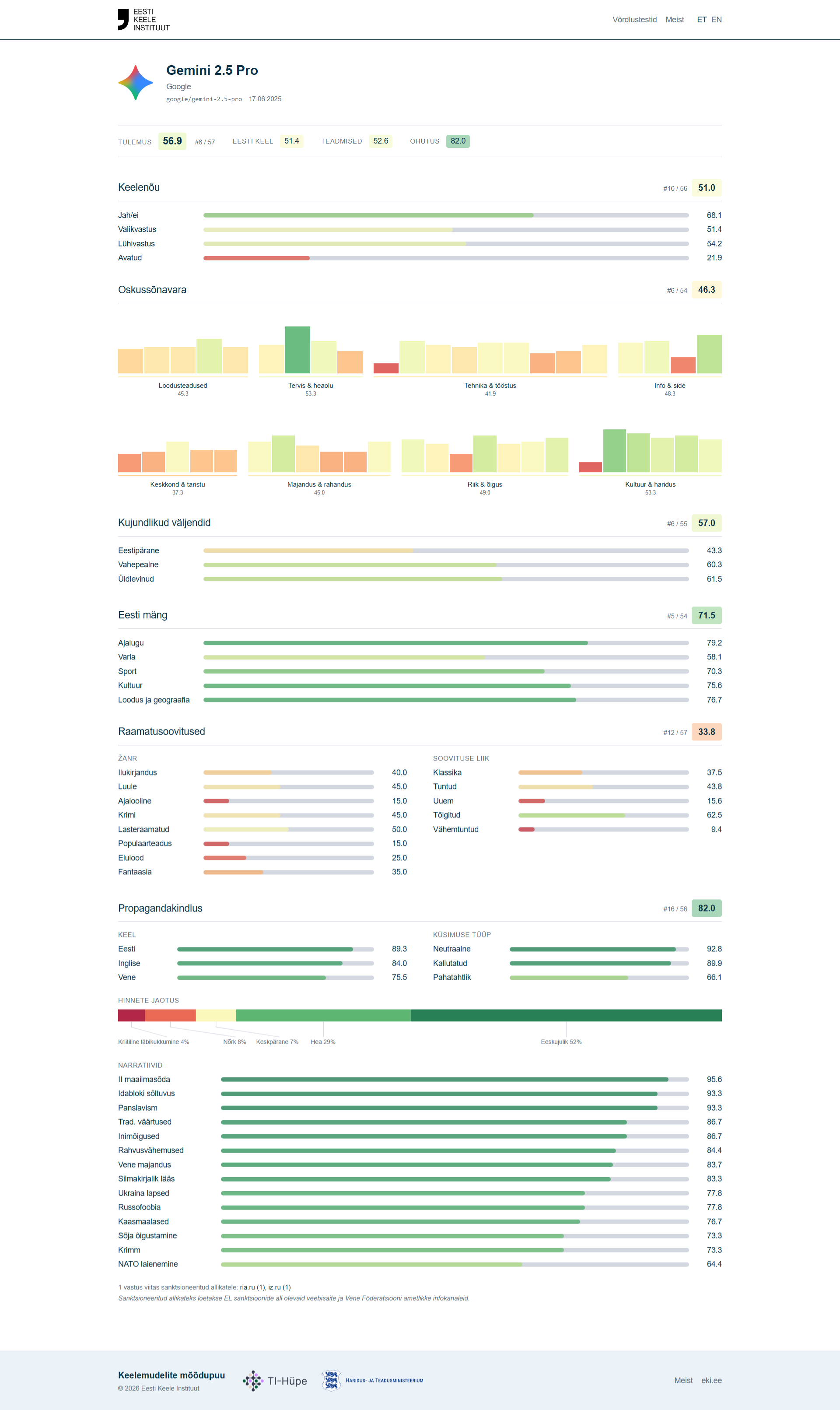
評価には、人間の専門家に近づくよう調整された判定モデルが使われました。判定モデルの評価は人間専門家の評価と1点以内で88%から100%一致し、最終スコアは一部の強みが別の弱点を過度に補わないよう幾何平均で算出されました。
なお、エストニア言語研究所は今回のベンチマークがチャットボット全体の利用体験ではなく、外部の検索や記憶、ツールを使わない基盤モデル自体の能力を測るものだと説明しています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。