

NVIDIAが拡散モードと自己回帰モードを備えたAIモデル「Nemotron-Labs-Diffusion」を発表しました。Nemotron-Labs-Diffusionは拡散モードと自己回帰モードを組み合わせることで高速かつ高品質な応答が可能とされています。
nvidia/Nemotron-Labs-Diffusion-14B · Hugging Face
https://huggingface.co/nvidia/Nemotron-Labs-Diffusion-14B
Most language models only generate one token at a time.
We just released Nemotron-Labs-Diffusion, a family of diffusion language models that take a different approach, generating multiple tokens in parallel within a single model. Rather than committing to each token permanently,… pic.twitter.com/fTOBmQ8KaM
— NVIDIA AI (@NVIDIAAI) May 19, 2026
主流の言語モデルは「次の単語を予測する」という計算処理を繰り返すことで文章やコードを生成する「自己回帰モデル」がほとんどです。自己回帰モデルには正確な文章を生成しやすいという特徴がある一方で、一度に1つの単語しか予測できないため処理速度が遅いという欠点があります。自己回帰モデルの欠点を克服するために、画像生成や動画生成で主流の「拡散モデル」を言語モデルに取り入れる研究も行われています。拡散モデルは精度が低くなる変わりに一度に複数の単語を予測して高速な処理を実現できます。拡散言語モデルを開発する取り組みは複数の研究機関によって実施されており、Googleが「Gemini Diffusion」を開発しているほか、日本ではAI開発企業のELYZAが「ELYZA-LLM-Diffusion」を開発しています。
Google DeepMindが爆速でテキストを生成する拡散モデル「Gemini Diffusion」を発表 – GIGAZINE

NVIDIAが開発したNemotron-Labs-Diffusionは「自己回帰モード(AR Mode)」「拡散モード(Diffusion Mode)」「自己投機モード(Self-Speculation Mode)」の3つのモードを切り替えて推論することができます。自己投機モードは「拡散モードで下書きを生成し、自己回帰モードで下書きを検証する」というモードで、高精度かつ高速な処理が可能です。
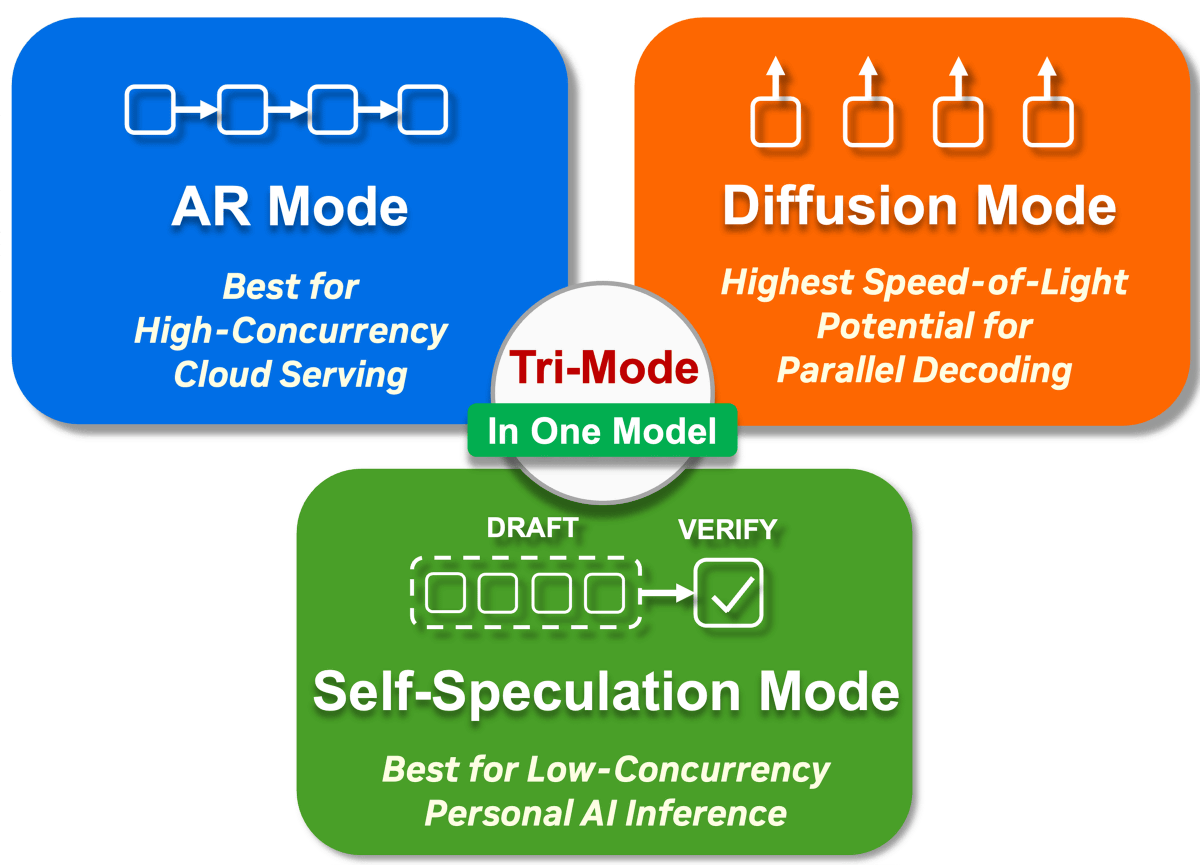
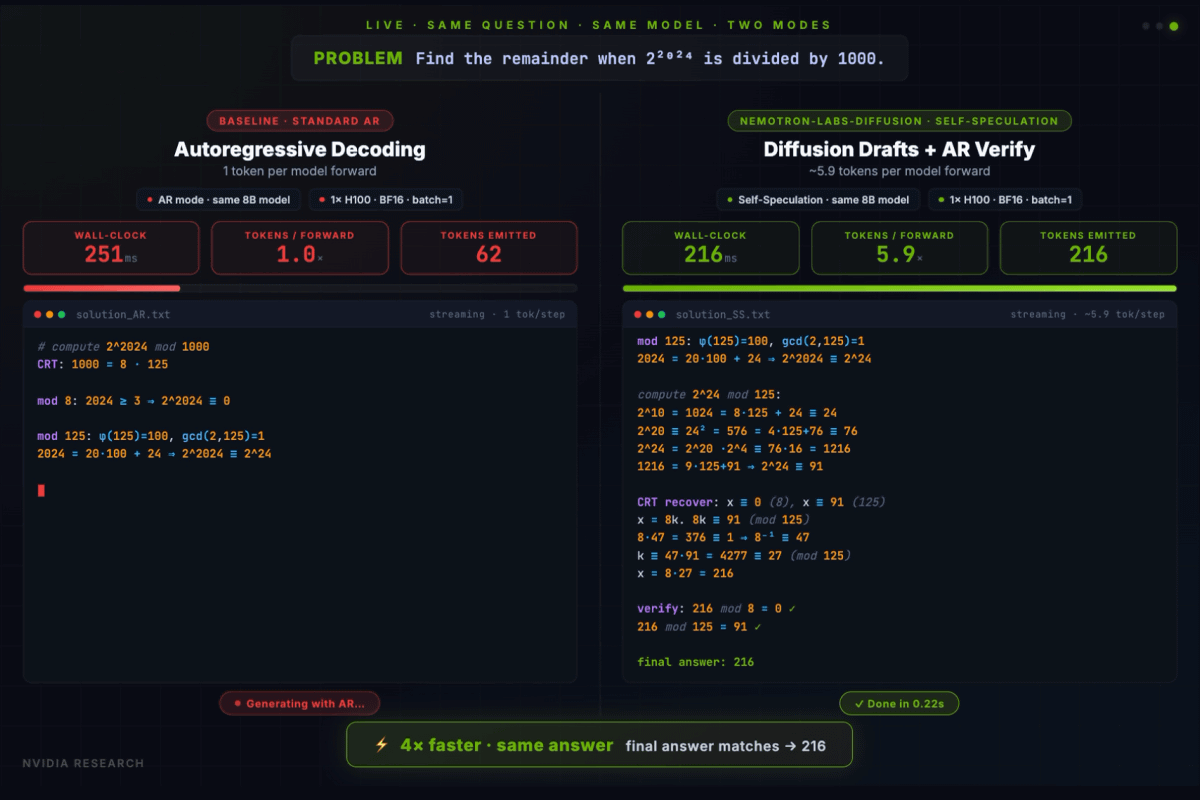
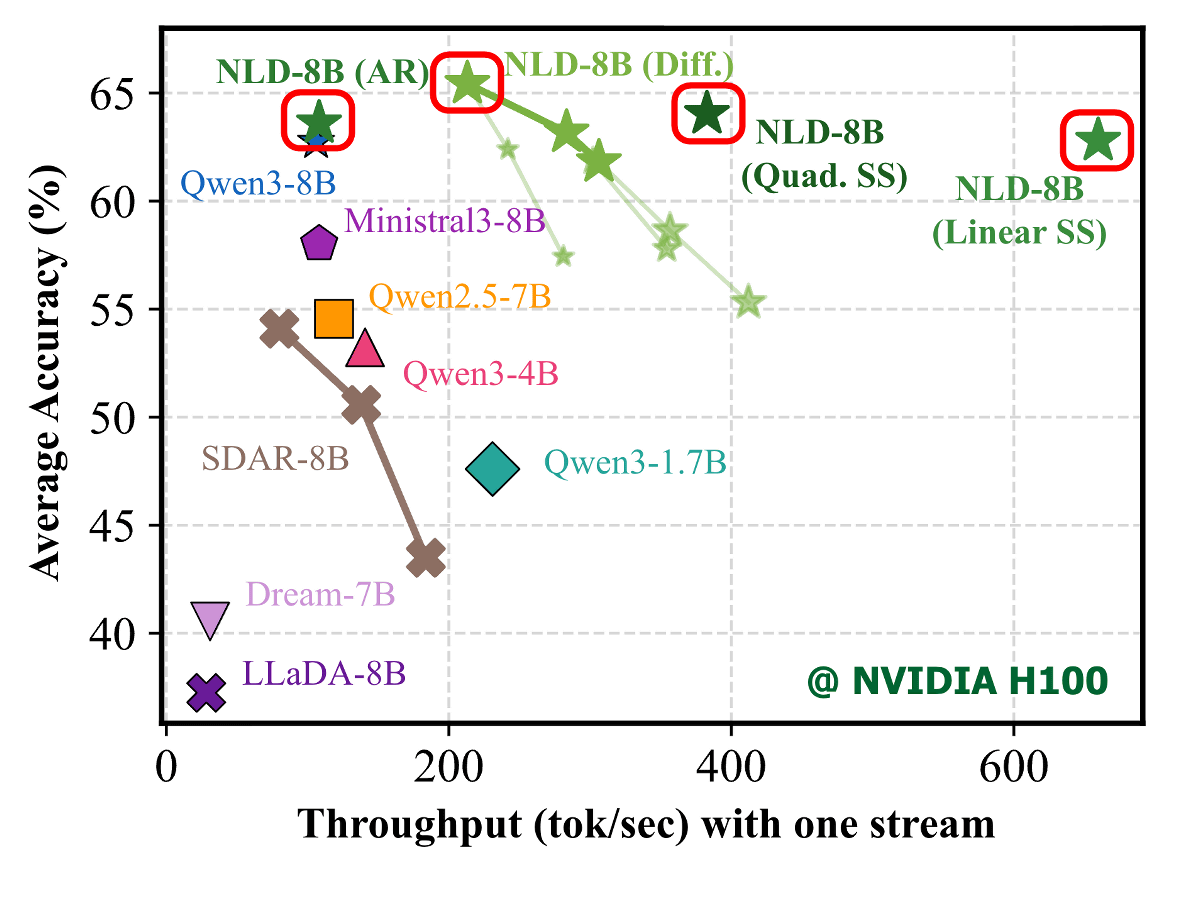
Nemotron-Labs-Diffusionは「Nemotron-Labs-Diffusion-3B」「Nemotron-Labs-Diffusion-8B」「Nemotron-Labs-Diffusion-VLM-8B」「Nemotron-Labs-Diffusion-14B」の4種類がオープンモデルとして公開されています。Nemotron-Labs-Diffusion-8BをH100で実行した場合、自己投機モードは自己回帰モードと同じ結果を4倍高速に出力可能です。
Nemotron-Labs-Diffusion-8B処理性能も高めで、正確性を測定するベンチマークテストでは自己回帰モード・拡散モード・自己投機モードのすべてでQwen3-8Bを上回るスコアを記録しています。
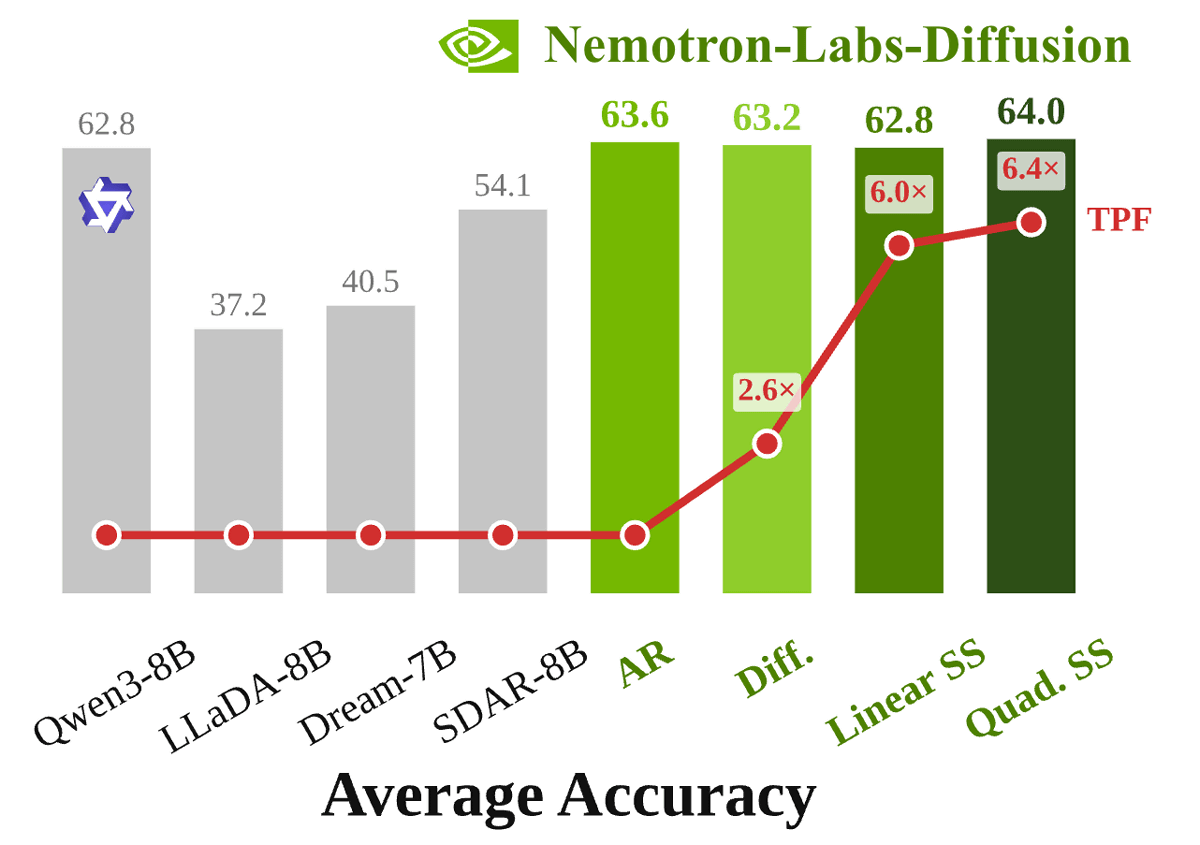
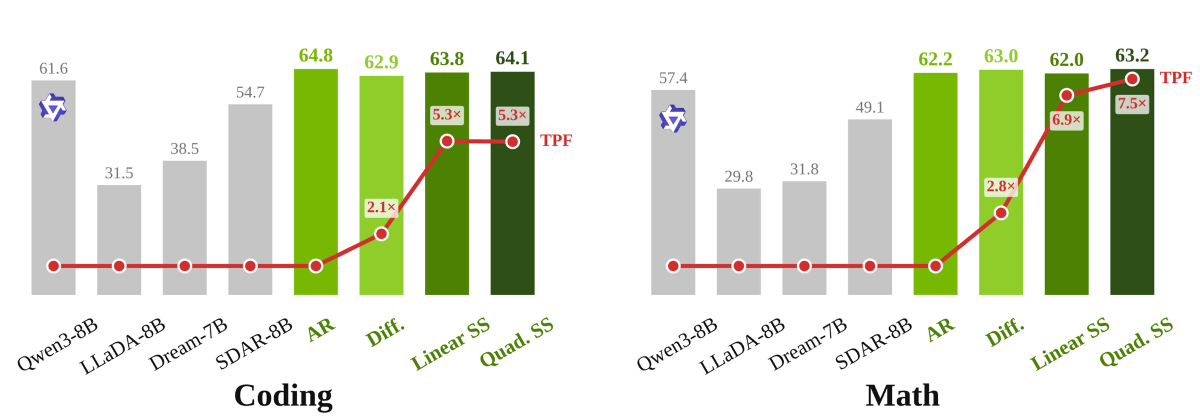
また、コーディング性能や数学性能もQwen3-8Bより高いスコアを示しています。
以下のグラフが横軸が1秒当たりの出力トークン数で、縦軸が精度を示しています。Nemotron-Labs-Diffusion-8Bは拡散モードだと他モデルより高速な処理が可能で、自己投機モードでは飛び抜けて高速な処理速度を実現しています。
Nemotron-Labs-Diffusionの各種モデルは以下のリンク先で配布されています。ライセンスはNVIDIA Nemotron Open Model Licenseです。
Nemotron-Labs-Diffusion – a nvidia Collection
https://huggingface.co/collections/nvidia/nemotron-labs-diffusion
また、Nemotron-Labs-Diffusionに関する研究論文が以下のリンク先で公開されています。
Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding
(PDFファイル)https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron_Diffusion_Tech_Report_v1.pdf

この記事のタイトルとURLをコピーする
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。