

AI企業のInterfazeが、OCRや音声認識、構造化データ出力といった「答えが決まっている作業」を大規模言語モデルよりも高精度かつ低コストで処理することを目指した新しいAIモデルアーキテクチャ「Interfaze」を公開しました。公式ブログによると、Gemini-3-Flash、Claude-Sonnet-4.6、GPT-5.4-Mini、Grok-4.3などの軽量・高速モデルと比較して、OCR、画像認識、音声認識、JSON出力など9種類のベンチマークで高い性能を示したとのことです。
Interfaze: A new model architecture built for high accuracy at scale – Interfaze
https://interfaze.ai/blog/interfaze-a-new-model-architecture-built-for-high-accuracy-at-scale

人間は、文書を読んで意味を理解したり、曖昧な指示をくみ取ったりするのは得意ですが、50ページのPDFを1文字ずつ読み取り、各単語の座標を記録し、さらに別言語へ翻訳するような作業には向いていません。時間がかかり、ミスも増え、コストも高くなります。
Interfazeの記事によると、現在広く使われているTransformerベースの大規模言語モデルも同様の性質を持っているとのこと。つまり、文脈理解や創造的な処理には強い一方で、OCRやデータ抽出のように正確さと再現性が求められる作業では人間のようなミスが残りやすいというわけです。
そこでInterfazeが採用しているのが、DNNやCNNといったタスク特化型のニューラルネットワークと、Transformerデコーダーを組み合わせたハイブリッド構成です。DNNやCNNは、OCR、翻訳、GUI検出など特定の作業に最適化しやすく、文字の位置情報や信頼度スコアといったメタデータも出力できます。一方で、単体では柔軟な推論や言語的な判断が苦手です。Interfazeはこの弱点をTransformerで補うことで、決まりきった作業の正確さと、LLM的な柔軟さを両立しようとしているとのこと。
下図は、Interfazeが入力を処理して出力を生成するまでの流れを示した図です。プロンプトは前処理を経て、DNNやCNNとTransformerを組み合わせた中核部分に送られ、OCR、物体検出、翻訳、音声認識などのタスク別アダプターと連携します。その後、必要な情報だけが整理され、デコーダーや構造化出力モデルを通じてテキストやJSONとして出力されるため、Interfazeが「専門モデルの正確さ」と「Transformerの柔軟さ」を組み合わせる設計になっていることが分かります。
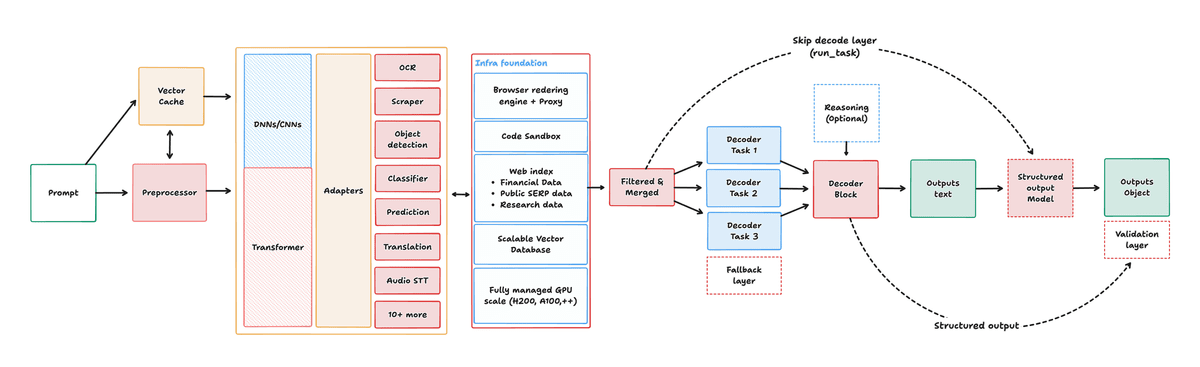
中心となるポイントは、Interfazeが「LLMを置き換える万能AI」ではなく、「OCRや音声認識、構造化出力など、開発者が大量に処理する定型タスクに特化したAI」として設計されていることです。記事でも、Claude OpusやGPT-5.5のような高性能な汎用モデルはコーディングや複雑な推論では強力だとしつつ、OCRや翻訳のような大量処理ではコストや速度の面で使いにくいと説明しています。
Interfazeの仕様としては、コンテキストウィンドウが100万トークン、最大出力が3万2000トークンで、入力はテキスト、画像、音声、ファイルに対応。推論機能も用意されていますが、標準では無効です。価格はGemini-3-Flashに近い水準で、入力100万トークンあたり1.50ドル(約236円)、出力100万トークンあたり3.50ドル(約552円)とされています。
Interfazeが特に重視している用途がOCRです。長いPDFや複雑なレイアウトの文書、画像内の文字認識などで、文字だけでなく図表やグラフィックの位置も同時に扱える点が売りとのこと。たとえば雑誌のような複数段組みのページを入力すると、ページ内のテキストを抽出しつつ、イラストや図版の座標もJSON形式で返すことができます。
下図は、長くレイアウトが複雑なPDFに対するOCR精度を比較したグラフです。Interfazeが85.7%で最も高く、Chandra OCR、olmOCR、Grok-4.3、GPT-5.4-Miniなどを上回っていることが分かります。
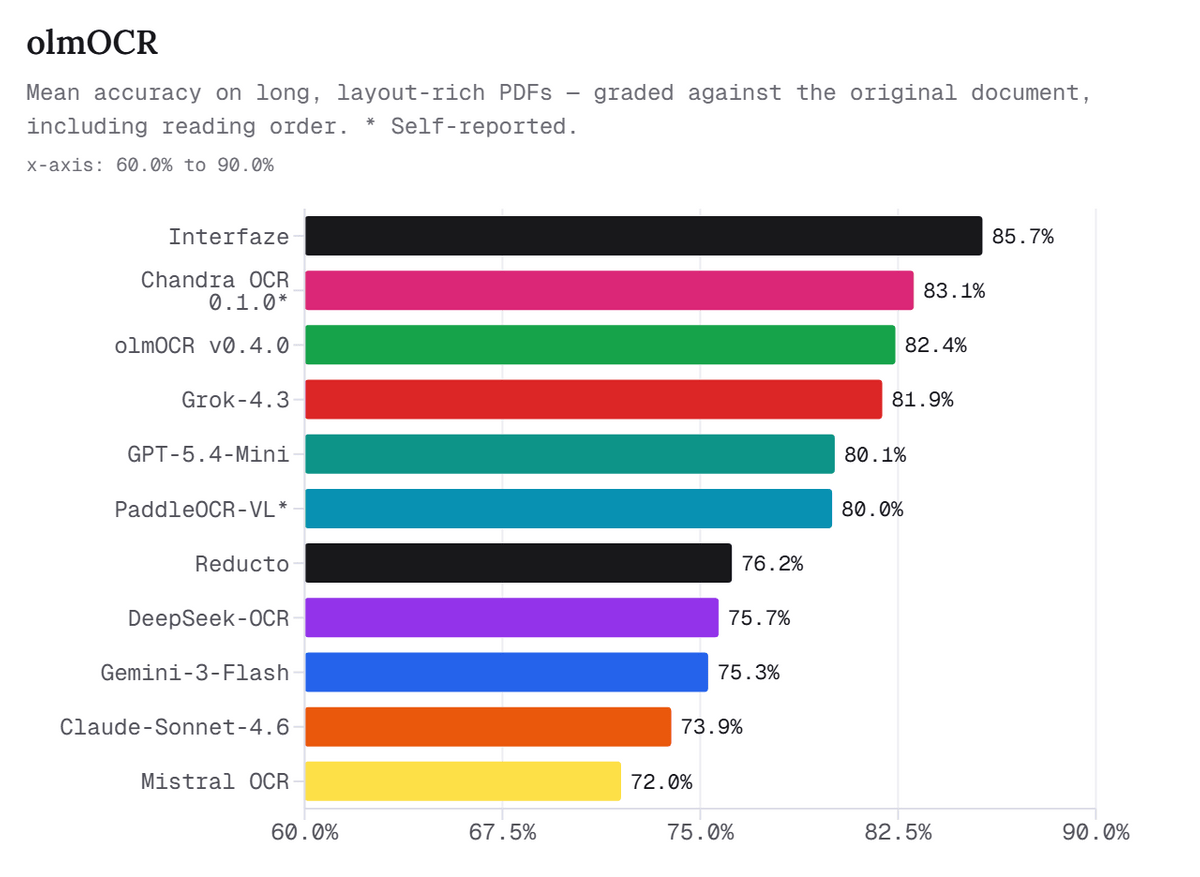
InterfazeがOCRで強い理由として、記事では単にCNNエンコーダーが文字をうまく読むだけではなく、図版やグラフィックの検出、翻訳レイヤー、Transformerによる意味理解を同じベクトル空間で組み合わせられる点が挙げられています。
もう1つの重要なテーマが、構造化出力です。多くのLLMはJSONスキーマに従った形式で出力することは得意ですが、その中に入る値が正しいとは限りません。たとえば「氏名」「住所」「日付」「金額」といった欄をきれいなJSONで返せても、値そのものが間違っていれば実務では使えません。
Interfazeはこの問題を測るために、Structured Output Benchmark(SOB)を公開しました。SOBでは、モデルに正解となる情報をコンテキストとして与え、その情報をJSONとして正しく出力できるかを測定します。評価対象はテキスト、画像、音声を含み、最終的にはJSONの末端の値が正解と完全一致しているかどうかで精度を測るという仕組み。
下図は、JSONの末端値が正解と完全一致した割合を示すSOB Value Accuracyのグラフです。Interfazeは79.5%でトップとなっており、Grok-4.3、Claude-Sonnet-4.6、Gemini-3-Flash、GPT-5.4-Miniをわずかに上回っていることが分かります。
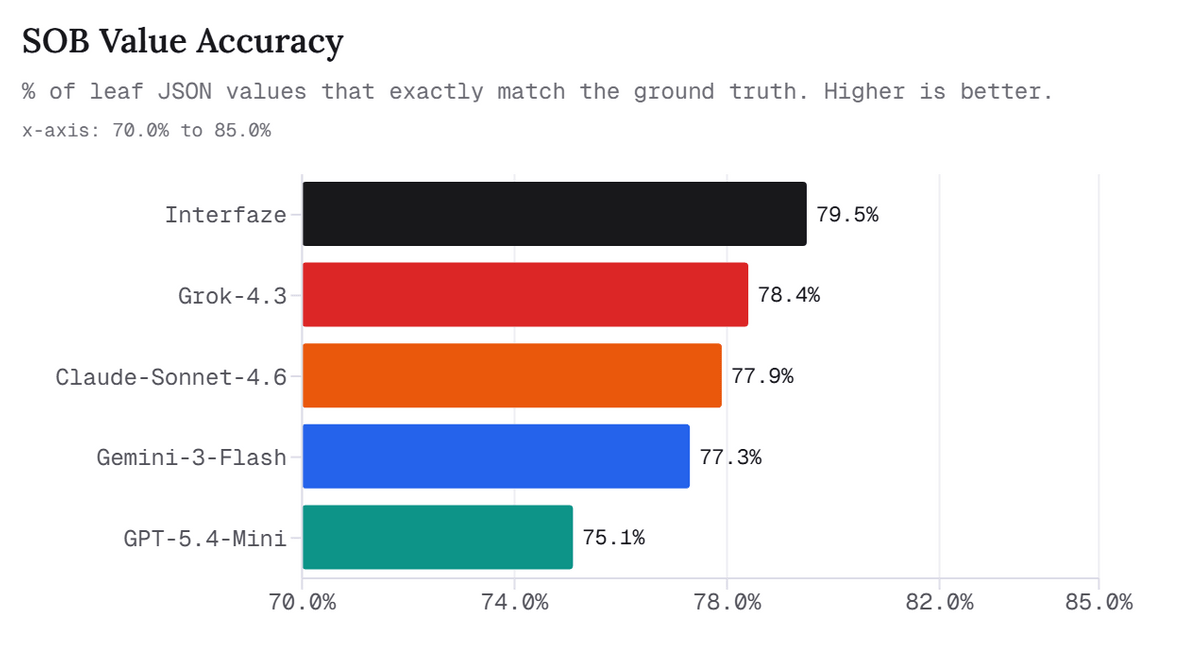
多言語性能でも、Interfazeは高いスコアを示しています。MMMLUは複数言語での知識・理解力を測るベンチマークで、英語以外の処理をどの程度安定して扱えるかを見る指標になります。
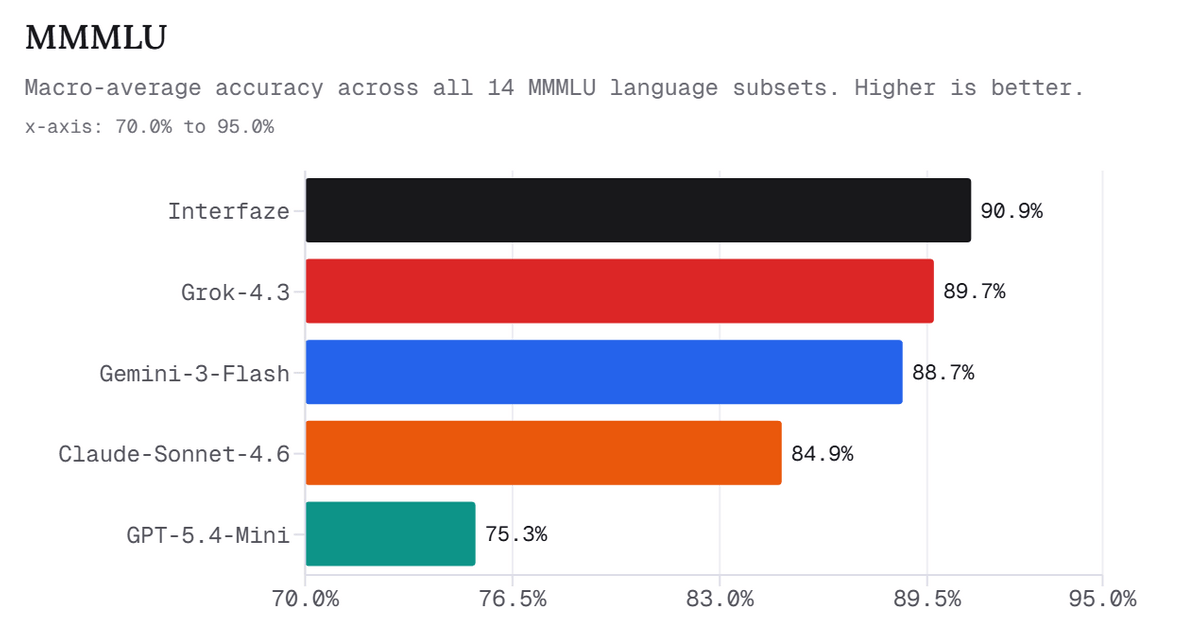
下図は、14言語のMMMLUサブセットにおけるマクロ平均精度を示したグラフです。Interfazeは90.9%で、Grok-4.3の89.7%、Gemini-3-Flashの88.7%を上回っていることが分かります。
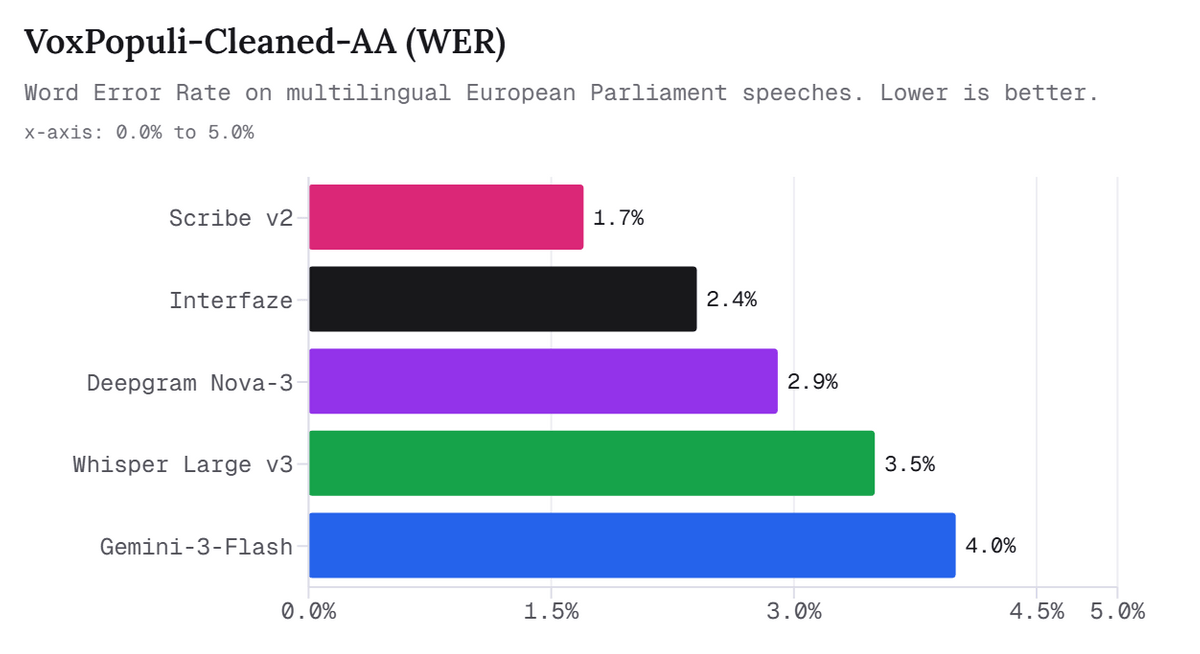
文字起こしでも、Interfazeは専門の音声認識サービスに近い性能を示しています。VoxPopuli-Cleaned-AAは、欧州議会の多言語スピーチを対象にした音声認識ベンチマークで、単語誤り率(WER)で評価します。
下図は、VoxPopuli-Cleaned-AAにおけるWERを比較したグラフです。最も低いのはScribe v2の1.7%で、Interfazeは2.4%と2位ですが、Deepgram Nova-3、Whisper Large v3、Gemini-3-Flashより低い誤り率になっていることが分かります。
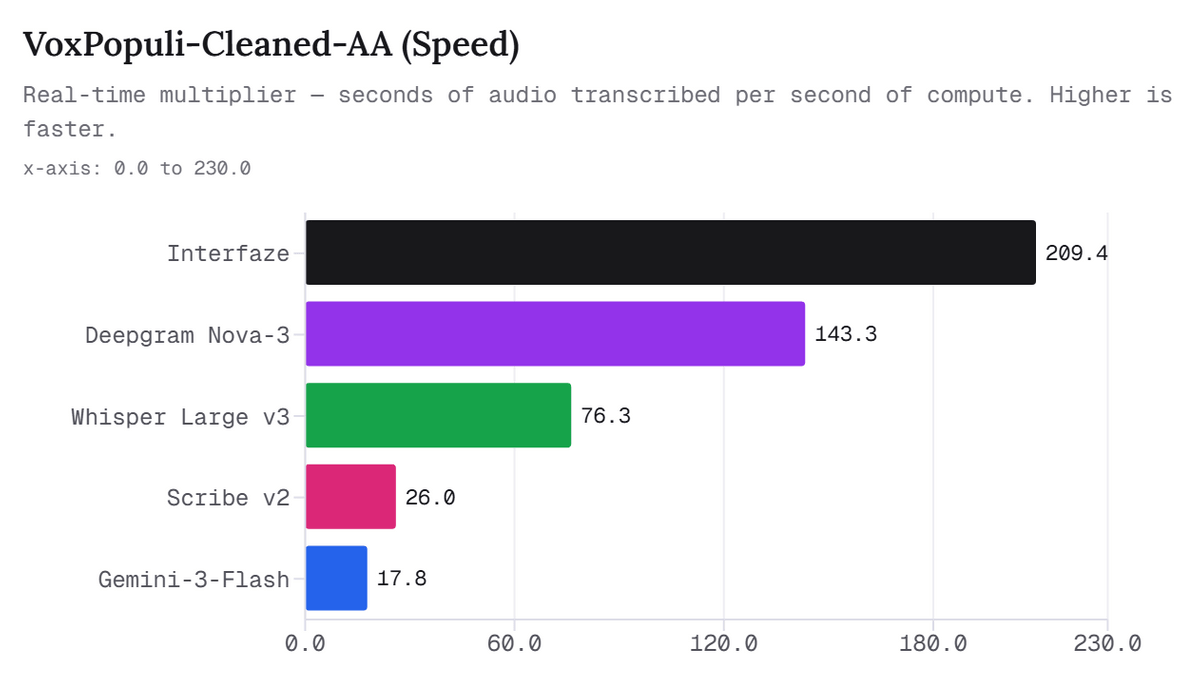
さらにInterfazeは、音声認識の速度でも強みを示すとのこと。記事によると、Interfazeは1秒の計算時間で209秒分の音声を処理できるとのことです。これはDeepgram Nova-3の約1.5倍、Scribe v2の約8倍、Gemini-3-Flashの11倍以上に相当します。
下図は、VoxPopuli-Cleaned-AAにおける文字起こし速度の比較です。Interfazeが209.4でトップとなっており、Deepgram Nova-3の143.3、Whisper Large v3の76.3を大きく上回っていることが分かります。
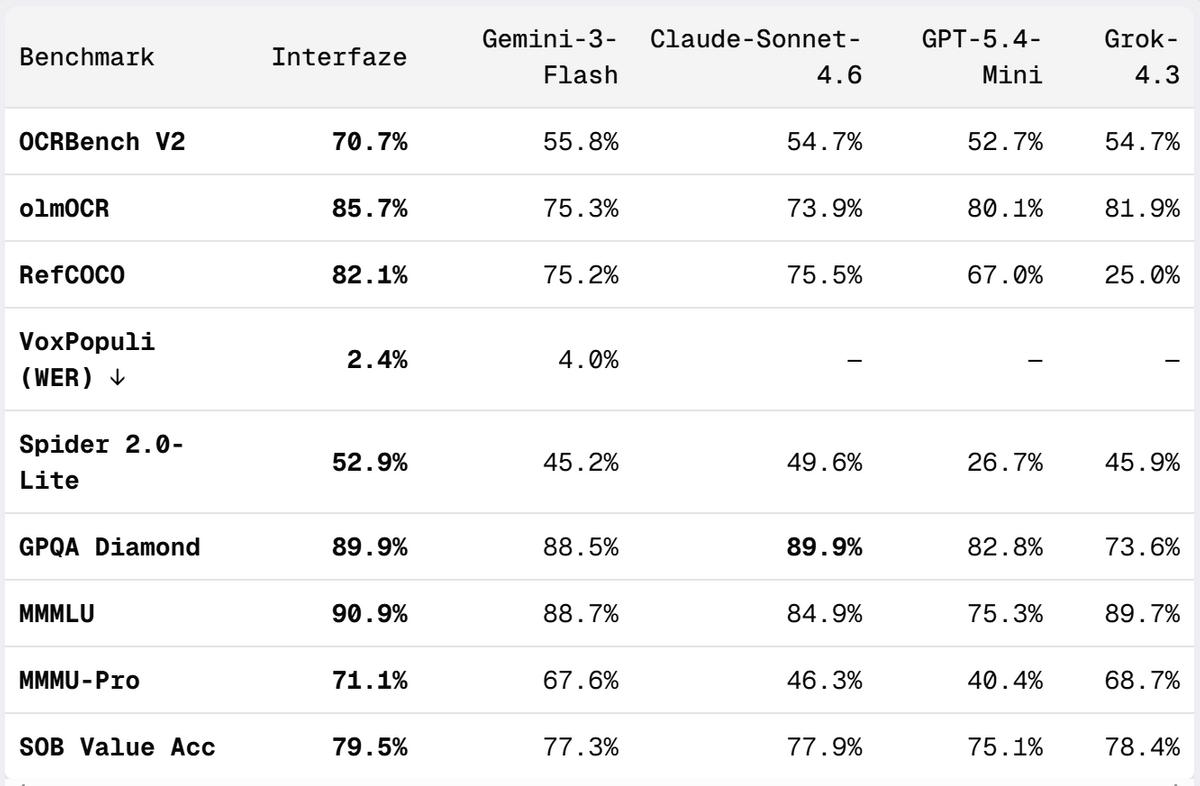
記事全体のベンチマークでは、OCRBench V2、olmOCR、RefCOCO、VoxPopuli、Spider 2.0-Lite、GPQA Diamond、MMMLU、MMMU-Pro、SOB Value Accuracyの9項目が比較されています。Interfazeは多くの項目で最上位または上位に入り、特にOCR、構造化出力、多言語処理、音声認識速度で目立つ結果を出しました。
InterfazeはOpenAI互換のChat Completions APIとして利用可能で、既存のOpenAI SDK、Vercel AI SDK、LangChainなどを使って、baseURLをInterfazeのAPIに向けるだけで導入できるとのこと。
また、モデル全体を毎回動かすのではなく、一部だけを起動する「partial model activation」も用意されています。たとえばシステムプロンプトでOCRタスクを指定すると、純粋なOCR処理だけを走らせ、より高速かつ低コストで結果を得ることができるとのこと。その代わり、1回のリクエストで実行できるタスクは1つに限られ、出力形式も固定的になると述べられています。
Interfazeにはウェブ検索やスクレイピング、コードサンドボックスも組み込まれており、人物情報の補完やウェブ抽出にも使えるとされています。さらに、1時間35分のポッドキャスト音声を約50秒で文字起こしし、タイムスタンプ付きのチャンクとして返す例も紹介されています。
Interfazeは、自社のモデルについて「何でもできる巨大AI」ではなく、「大量の文書を読む」「音声を高速に文字起こしする」「画像やPDFから正確な値を取り出してJSON化する」といった、企業や開発者が日常的に大量処理する作業に焦点を絞ったモデルだと説明。LLMが得意とする創造性や高度な推論を置き換えるのではなく、ミスが許されにくい定型作業を速く、安く、正確に処理することを重視しているとのこと。
Interfazeは、すべての処理を汎用LLMに任せるのではなく、用途に応じてDNNやCNNの専門性とTransformerの柔軟性を組み合わせることが重要だと強調しています。同社は、答えが決まっている処理をより効率的で扱いやすいものにするため、今後も研究と改善を続けていくと述べました。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。