

現地時間の2026年4月28日、NVIDIAが視覚・音声・言語モデルを統合したオムニモーダル推論モデルの「Nemotron 3 Nano Omni」を発表しました。コンピューターの使用、文書の分析、音声や映像の推論といったエージェント型ワークフローを支える最高の効率性と精度を実現しています。
NVIDIA Launches Nemotron 3 Nano Omni Model, Unifying Vision, Audio and Language for up to 9x More Efficient AI Agents | NVIDIA Blog
https://blogs.nvidia.com/blog/nemotron-3-nano-omni-multimodal-ai-agents/
NVIDIA Nemotron 3 Nano Omni Powers Multimodal Agent Reasoning in a Single Efficient Open Model | NVIDIA Technical Blog
https://developer.nvidia.com/blog/nvidia-nemotron-3-nano-omni-powers-multimodal-agent-reasoning-in-a-single-efficient-open-model/
既存のAIエージェントシステムの多くは、視覚・音声・言語それぞれに別々のAIモデルを利用しています。そのため、AIエージェントが何かしらの作業を実行する場合、あるAIモデルから別のAIモデルへデータを渡すこととなり、このタイミングで時間および文脈が失われてしまいます。
そこでNVIDIAが開発したのが、オムニモーダル推論モデルの「Nemotron 3 Nano Omni」です。視覚・音声・言語という異なる分野にまたがる作業をひとつのシステムに統合しています。これにより、エージェントは動画・オーディオ・画像・テキストにわたる高度な推論が可能となり、より高速でスマートな応答を提供できるようになるわけです。
Nemotron 3 Nano Omniは卓越した精度と低コストを実現し、オープンなマルチモーダルモデルの効率性に新しい境地を切り開くこととなります。NVIDIAによると、Nemotron 3 Nano Omniは複雑な文書の認識、動画および音声の理解において、6つのランキングでトップに立っているとのこと。
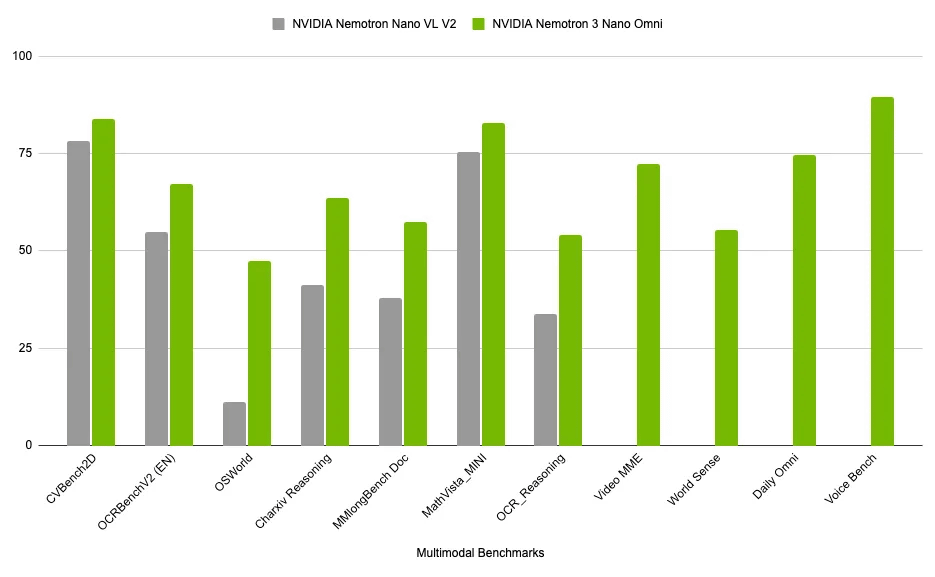
以下はNemotron 3 Nano Omniと前世代のAIモデルであるNVIDIA Nemotron Nano VL V2のパフォーマンスを比較するべく、AI関連のベンチマークテストのスコアを並べたもの。あらゆるパフォーマンスで前モデルを圧倒していますが、特にマルチモーダルエージェント向けのベンチマークであるOSWorldで大幅な成長を記録しています。
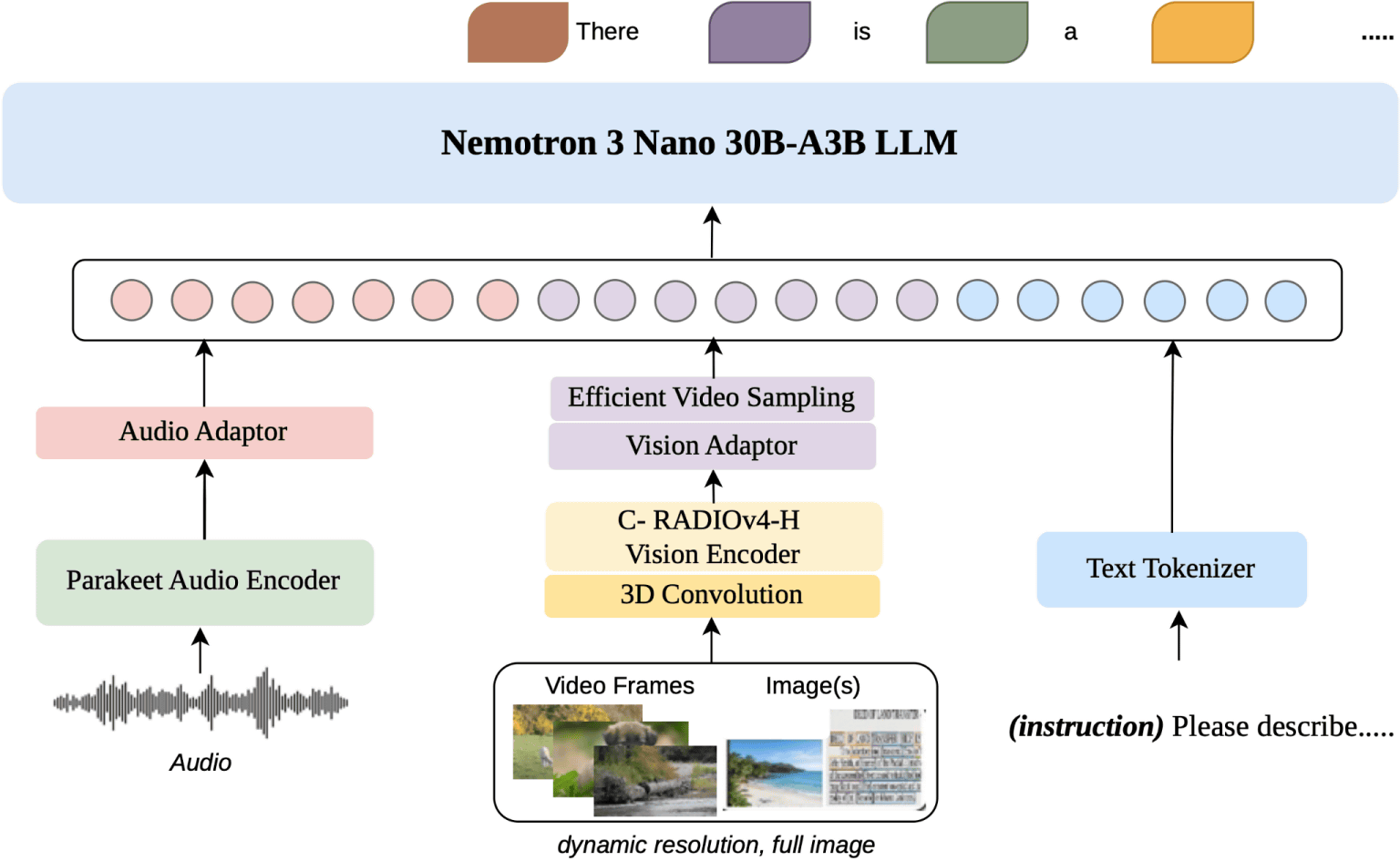
Nemotron 3 Nano Omniは総パラメーター数300億、アクティブパラメーター数30億のMoEモデルです。Nemotron 3 Nano OmniのハイブリッドMoEコアアーキテクチャは、シーケンスとメモリ効率を高めるMambaレイヤーと精密な推論を実現するトランスフォーマーレイヤーを組み合わせることで、最大4倍のメモリ効率と計算効率の向上を実現しているそうです。
また、動画フレームを効果的に処理するために、3D畳み込みを使用してフレーム間の動きをキャプチャ。推論時の効率的な動画サンプリングレイヤーは、複数のフレームから高密度の視覚トークンを圧縮し、大規模言語モデル(LLM)がコンテキストウィンドウを過負荷なく処理することを可能にします。
Nemotron 3 Nano Omniは強力なテキストモデルを中央デコーダーとして使用し、基盤モデルの言語能力を維持しつつ、クロスモーダルブリッジをトレーニングします。これにより、マルチモーダルトレーニングの不安定性とコストが削減され、連続知覚タスクにおいて最高の効率と精度を実現。音声面は、リアルタイム文字起こしモデルのNVIDIA Parakeetと、単純な文字起こしを超えた特殊なデータセットに基づいて構築。さらに、基盤モデルにC-RADIOv4-Hを使用することで、高解像度で画像を処理することが可能になっています。
Nemotron 3 Nano OmniのハイブリッドMoEアーキテクチャを簡単に図示したのが以下の画像。
すでにNemotron 3 Nano Omniを採用している企業には、Aible、Applied Scientific Intelligence(ASI)、Eka Care、Foxconn、H Company、Palantir、Pylerなどがあります。さらに、Dell Technologies、DocuSign、Infosys、K-Dense、Lila、Oracle、Zefrなども評価を実施中です。
Nemotron 3 Nano Omniはオープンモデルとして公開されており、Hugging Faceからダウンロード可能です。また、OpenRouterでAPIが公開されているほか、build.nvidia.comでデモを実行することもできます。
nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 · Hugging Face
https://huggingface.co/nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16
Nemotron 3 Nano Omni (free) – API Pricing & Providers | OpenRouter
https://openrouter.ai/nvidia/nemotron-3-nano-omni-30b-a3b-reasoning:free
nemotron-3-nano-omni-30b-a3b-reasoning Model by NVIDIA | NVIDIA NIM
https://build.nvidia.com/nvidia/nemotron-3-nano-omni-30b-a3b-reasoning
Fireworks AIでもNemotron 3 Nano Omniが利用可能になるそうで、Fireworks AIは「NVIDIAのNemotron 3 Nano Omniをサポートできることに興奮しています。今、Nemotron 3 Nano OmniはFireworks AIで利用可能です。Nemotron 3 Nano Omniは単一の推論ループと視覚・音声・動画・テキストを処理する最初のオープンモデルです。スケーラブルなマルチモーダルサブエージェント向けに構築されており、Qwen3 30Bよりも9倍高いスループットを実現しています」と投稿しています。
Excited to support @NVIDIA Nemotron 3 Nano Omni, now available on Fireworks.
It’s the first open model that handles vision, audio, video, and text in a single inference loop. Built for multimodal sub-agents at scale, with 9× higher throughput than Qwen3 30B. 256K context.
Now… pic.twitter.com/EqWcuATF0W
— Fireworks AI (@FireworksAI_HQ) April 28, 2026
AWSも「NVIDIAのNemotron 3 Nano OmniがAmazon SageMaker JumpStartで利用可能になりました。このマルチモーダルモデルは、動画・オーディオ・画像・テキストをサポートし、企業向けQ&A、要約、文字起こし、OCR、ドキュメントインテリジェンスを実現します。Nemotron 3 Nano Omniを使用することで、組織は会議、トレーニングビデオ、ドキュメントのエンドツーエンドの処理を効率化できます」と投稿しました。
NVIDIA Nemotron 3 Nano Omni is now available on Amazon SageMaker JumpStart.
This multimodal model supports video, audio, image, and text, enabling enterprise Q&A, summarization, transcription, OCR, and document intelligence.
With @nvidia Nemotron 3 Nano Omni, organizations can… pic.twitter.com/NT6bQJyBLf
— AWS AI (@AWSAI) April 28, 2026
この記事のタイトルとURLをコピーする
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。