
中国の巨大IT企業であるテンセントが開発する大規模言語モデル(LLM)ファミリーの「Tencent HY」から、高性能推論モデル「Hy3 preview」がオープンソースで公開されました。
Tencent Hy Research
https://hy.tencent.com/hy3-preview
Hy3 previewは総パラメータ数2950億・アクティブパラメータ数120億の混合専門家(MoE)モデルで、コンテキストウィンドウは最大25万トークンです。レイテンシと深度のどちらを優先するかに応じた3つの推論モードを備えているのも特徴です。
テンセントは2026年2月に事前学習と強化学習のインフラストラクチャを再構築し、実用的なAIを構築するための3つの原則として「体系的な能力」「不正操作が可能な公開ベンチマークではなく現実的な評価」「コスト効率」を再設定しました。テンセントによると、Hy3 previewはこの再構築されたインフラストラクチャでトレーニングされた最初のモデルであり、複雑な推論、指示の追従、コンテキスト学習、コーディング、エージェントタスクにおいて大幅な改善を実現し、クラス最高のコスト効率を誇る「これまでリリースした中で最も高度なモデル」であるそうです。
以下は、難易度の高いSTEMベンチマークや大学の博士課程入試、中国高校生物オリンピックなどでHy3 previewと競合モデルを比較したもの。それぞれのグラフで一番左に水色で示されているのが前モデルのHy2で、濃い青で示されているのがHy3 previewとなっており、全てのベンチマークでスコアを上昇させていることが分かります。
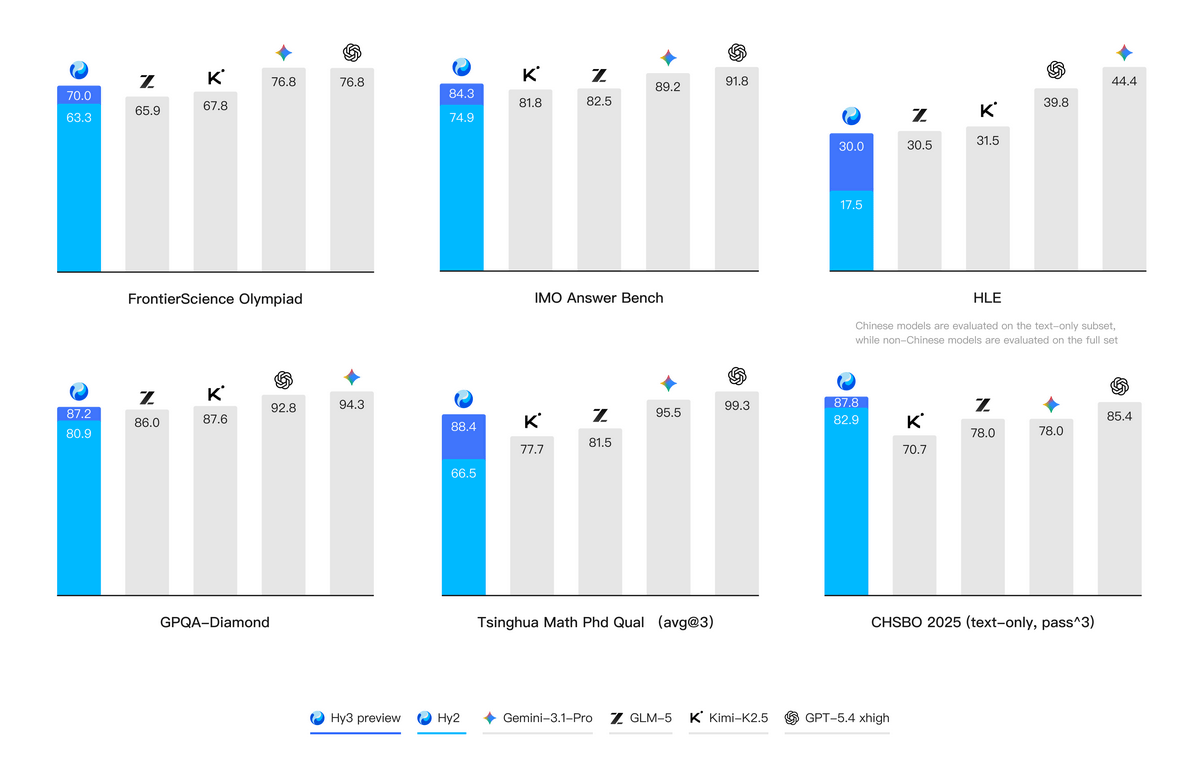
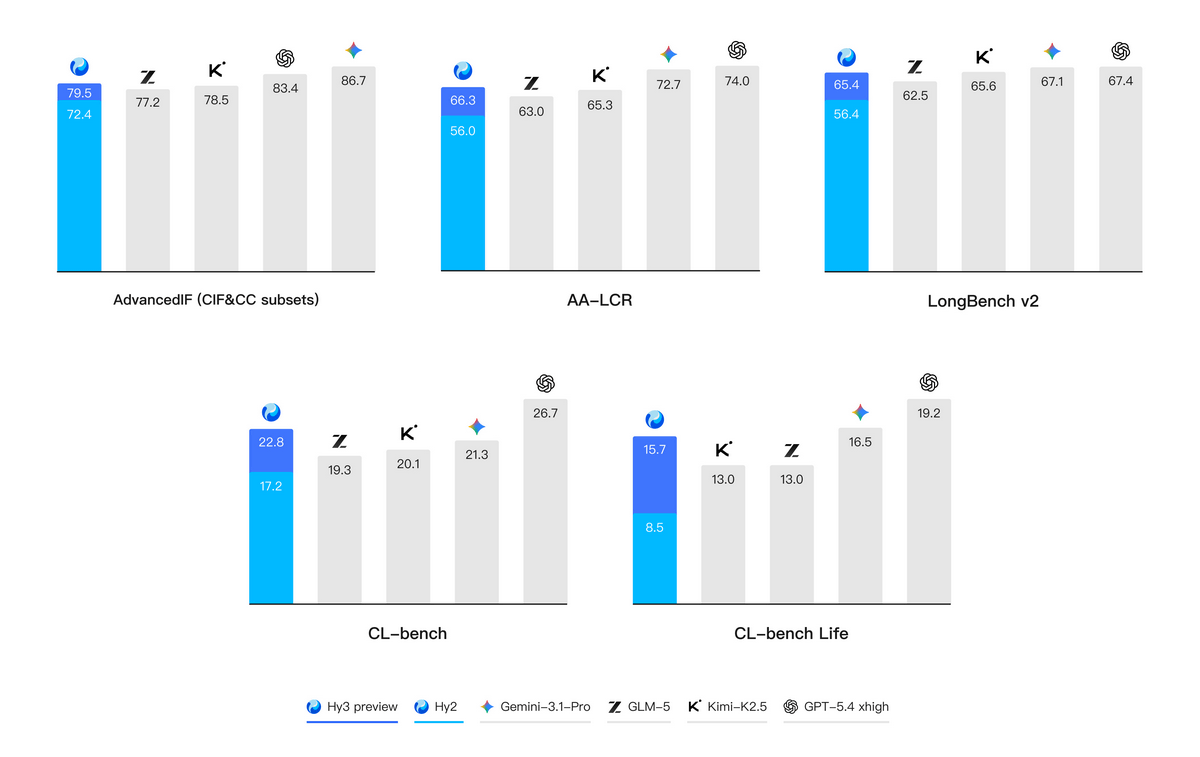
また以下は、実際の業務のシナリオに基づいて開発されたベンチマークでテストした結果。ほとんどのテストでHy3 previewはGemini 3.1 ProやGPT-5.4 xhighといった最先端のモデルに匹敵したスコアを記録しています。
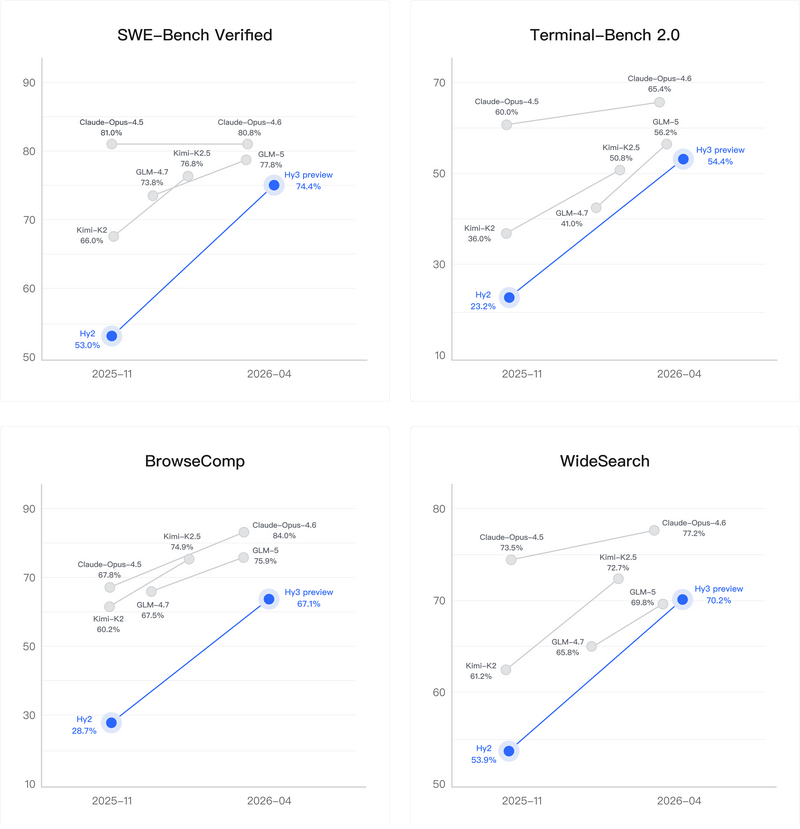
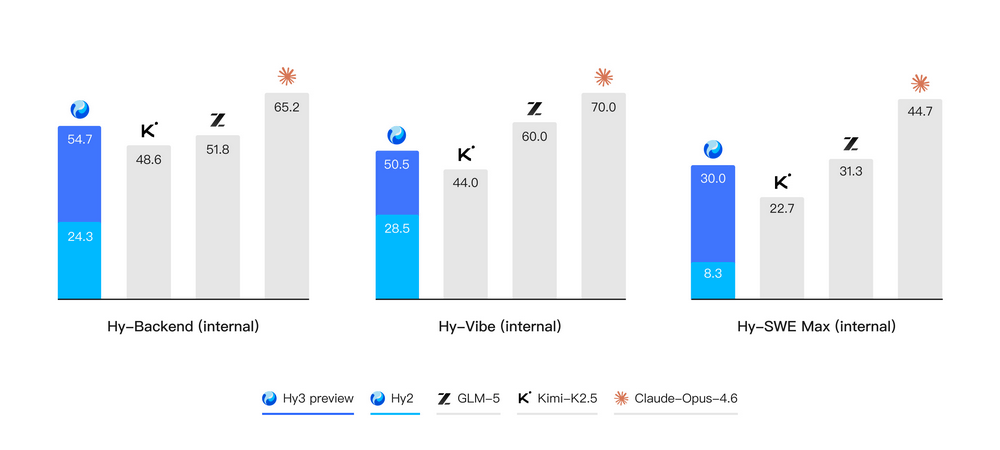
コーディングとエージェントの分野でもHy2からHy3 previewで大きな改善が示されています。Hy3 previewは、主要なコーディングエージェントベンチマークおよび検索エージェントにおいて、競争力のあるスコアを記録したとテンセントは報告しています。
また以下は、実際の開発シナリオでモデルをテストするために作成された評価セットのスコア。ここでも、Hy3 previewが他のオープンソースモデルと遜色ないスコアを記録しています。
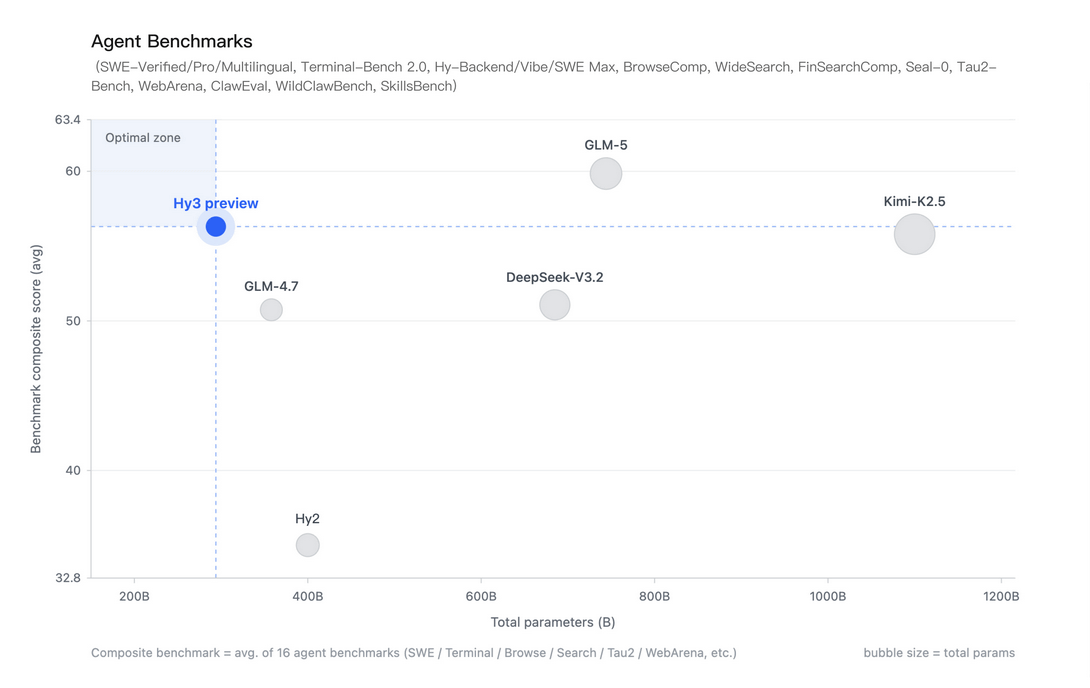
Hy3 previewの特徴の1つは、パラメータの規模とパフォーマンスのバランスにあるとテンセントは主張しています。以下の表は横軸がパラメータ、縦軸がベンチマークスコアで、Hy3 previewはZ.aiのGLM-5よりはパフォーマンスが劣るもののパラメータ数は半分以下で、パラメータ数が4倍近くあるKimi-K2.5と同等のパフォーマンスを発揮しています。
テンセントは「Hy3 previewは再構築の第一歩です。モデルは大幅に改善されましたが、ツール呼び出し時のエラー回復機能の弱さや推論ハイパーパラメータへの感度といった既知の制限事項があります。コミュニティやユーザーからの実際のフィードバックを得るためにオープンソース化し、正式リリース前に最終バージョンを改善していきます。同時に、事前学習と強化学習の規模を拡大し、機能を強化するとともに、製品チームとより緊密に連携してモデルを共同設計していきます。目標は、実世界でのパフォーマンス向上と製品固有の機能強化です」と述べています。
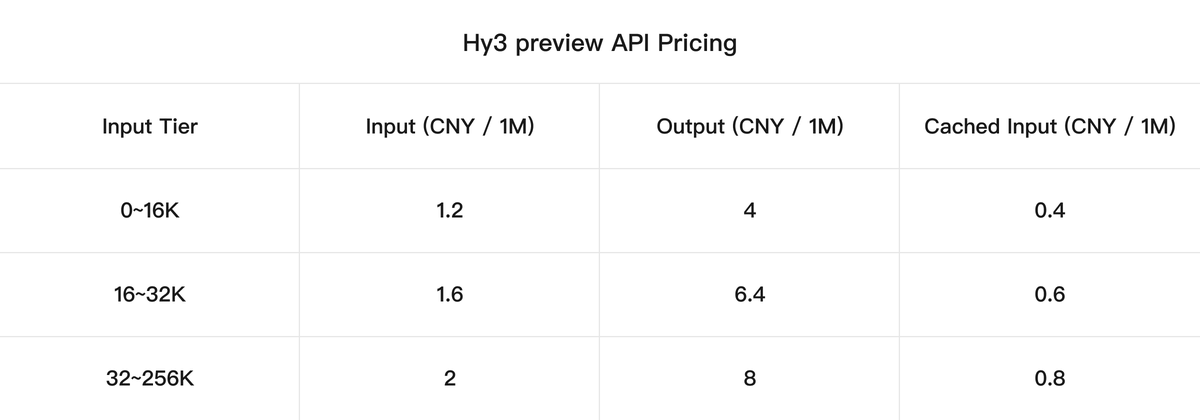
Hy3 PreviewはHugging Faceで公開されており、関連コードがGitHubで公開されています。また、APIも公開されており0~16Kの入力ティアの場合、100万トークン当たりの料金は入力が1.2元(約28円)、出力が4元(約94円)です。
GitHub – Tencent-Hunyuan/Hy3-preview: Hy3 preview (295B A21B), a leading reasoning and agent model in its size, with great cost efficiency · GitHub
https://github.com/Tencent-Hunyuan/Hy3-preview
tencent/Hy3-preview · Hugging Face
https://huggingface.co/tencent/Hy3-preview
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。