

Anthropicが「Claude Opus 4.7」を発表しました。Claude Opus 4.7はClaude Opus 4.6の直接的な後継モデルとして位置付けられており、特に高度なソフトウェア開発や難度の高い作業で性能を高めたほか、指示追従性と高解像度画像の処理能力も強化されたとしています。
Introducing Claude Opus 4.7 \ Anthropic
https://www.anthropic.com/news/claude-opus-4-7
Anthropicによると、Claude Opus 4.7は複雑で長時間に及ぶタスクを厳密かつ一貫して処理でき、指示をより正確に読み取り、自身の出力を返答前に検証するような振る舞いも強めているとのこと。初期テスターからは、従来は人間の綿密な監督が必要だった難しいコーディング作業を、より安心して任せられるようになったとの評価が寄せられているそうです。
ただし、Opus 4.7は指示追従性の向上によってプロンプトに対する動作が変化しており、旧モデル向けに作ったプロンプトをそのまま入力すると想定外の結果を返す場合があるそうで、Anthropicはプロンプトや実行環境の再調整を勧めています。
画像認識に関する大きな変更点として、高解像度画像への対応が挙げられます。Opus 4.7は長辺2576ピクセル、約375万画素までの画像を受け付けられるようになり、従来のClaudeモデルの3倍超の情報量を扱えるようになったとのこと。特に細かい文字が並ぶスクリーンショットの読解や複雑な図表からのデータ抽出、ピクセル単位の整合性が必要な作業に役立つとしています。
実際に、ベンチマーク表では視覚推論の「ChartX Reasoning」で、Opus 4.7はツールなしで82.1%、ツールありで91.0%となっており、Opus 4.6の69.1%、84.7%から伸びています。コーディング系でも「SWE-bench Pro」で64.3%、「SWE-bench Verified」で87.6%、「OSWorld-Verified」で78.0%を記録し、金融分析の「Finance Agent」でも64.4%と、Opus 4.6を上回る数値が示されています。
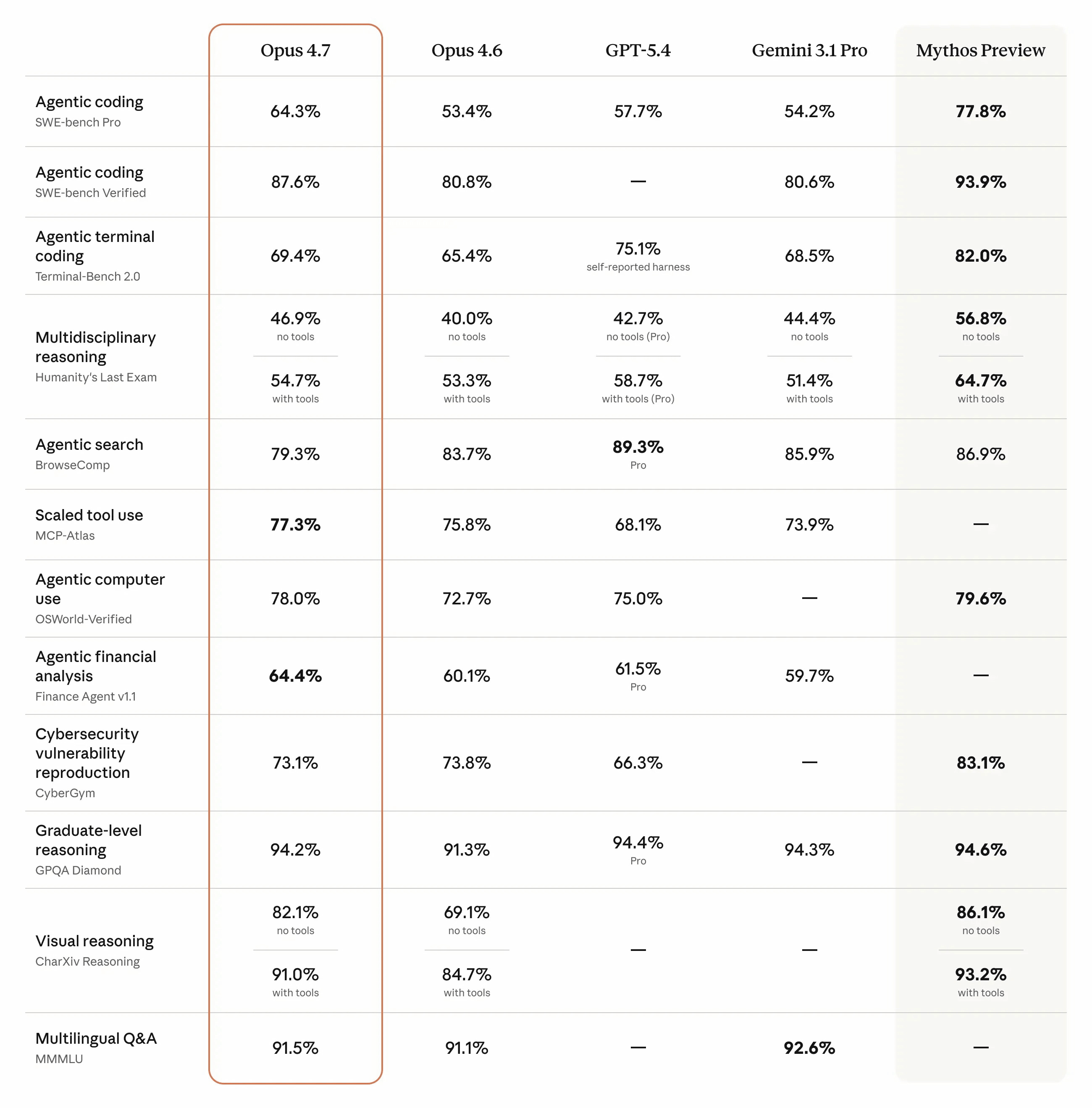
知識労働に関するGDPVal-AAベンチマークでは、Opus 4.7はGPT-5.4やGemini 3.1 Proを超える結果を出しています。
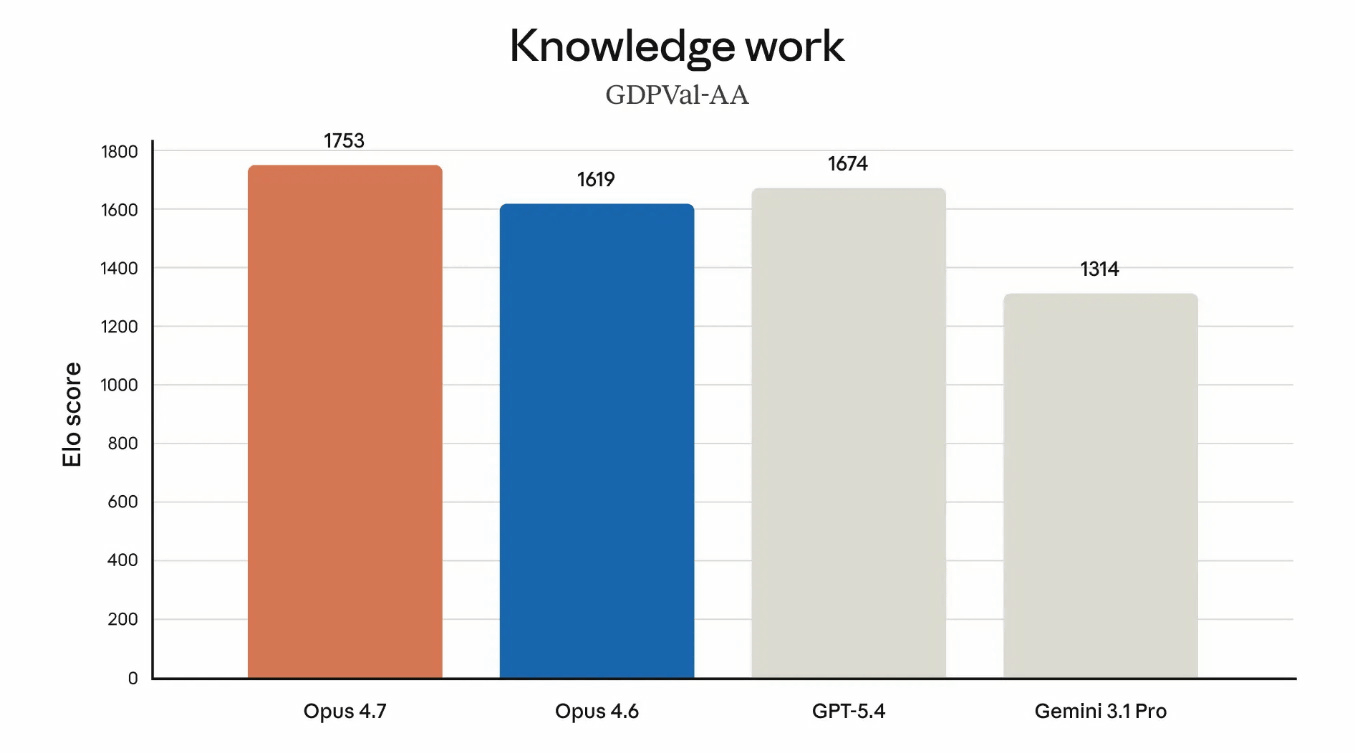
文書推論能力を測るOfficeQA Proでは、Opus4.7はOpus 4.6、GPT-5.4、Gemini 3.1 Proよりもはるかに高い精度をたたき出したとのこと。
一方で、AnthropicはOpus 4.7が同社の最上位モデルとされる「Claude Mythos Preview」ほど広範な能力を持つわけではないとも説明しています。Mythos Previewの公開は限定的に続けつつ、まずはそれより能力を抑えたOpus 4.7でサイバーセキュリティ向けの新たな安全対策を実地検証する方針で、危険なサイバー用途を示す要求を自動検出して遮断する仕組みを導入。正当な脆弱性調査やペネトレーションテストなどに使う専門家向けにCyber Verification Programも新設しました。
安全性については、全体としてOpus 4.6に近いプロファイルを示しつつ、誠実性や悪意あるプロンプトインジェクションへの耐性では改善が見られたとのこと。ただし、規制薬物に関する過度に詳細な危害低減助言のような一部項目ではわずかに弱い面もあり、Anthropicの整合性評価では「概ね適切に整合し信頼できるが、挙動はまだ理想的ではない」と位置付けられています。
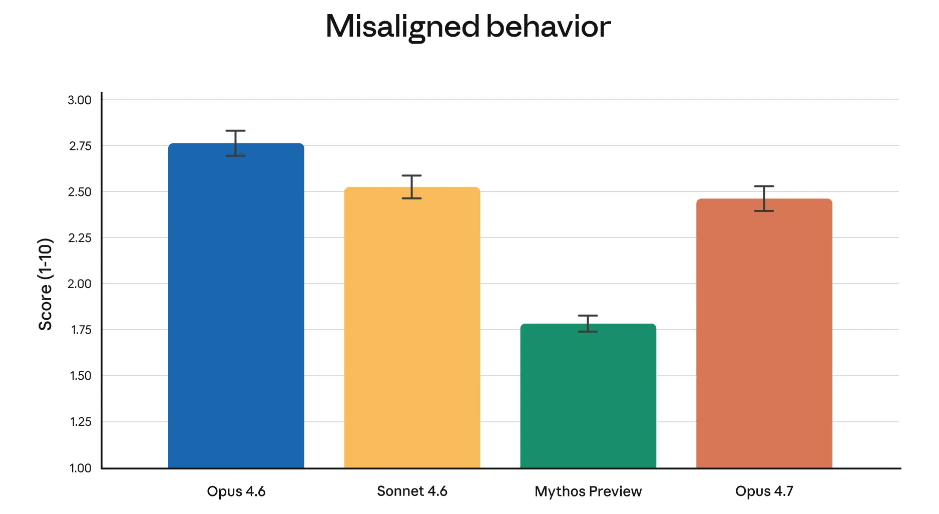
以下は自動行動監査による行動不一致率を示した棒グラフで、スコア(行動不一致率)が低いほど安全性が高いことを示しています。Opus 4.7はOpus 4.6と比べてわずかに改善されているものの、Mythos Previewはそれよりもはるかに行動不一致率が低いことがわかります。
Opus 4.7はClaude製品群全体に加え、Anthropic API、Amazon Bedrock、Google CloudのVertex AI、Microsoft Foundryから利用可能。価格はOpus 4.6から据え置きで、100万入力トークン当たり5ドル(約800円)、100万出力トークン当たり25ドル(約3980円)です。
さらに、Opues 4.7はトークナイザーが更新されたことで、同じ入力でも内容によってはOpus 4.6の1~1.35倍程度までトークン数が増える可能性があること。また、高いeffort設定では特にエージェント的な利用時の後半ターンで思考量が増え、出力トークンも増えやすくなるそうです。それでも、Anthropicは内部のコーディング評価では総合的な効率は改善したとしており、実運用のトラフィックで差分を確認しながら移行するよう勧めています。
なお、Claude Codeでは推論量を細かく調整できる新しいxhigh設定や、コードレビュー用の「/ultrareview」コマンド、Maxユーザー向けのauto mode拡張も同時に発表されています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。