

OpenAIがオープンソースの推論モデル「gpt-oss-safeguard」を2025年10月29日にリリースしました。gpt-oss-safeguardは推論時にコンテンツポリシーを追加できるモデルで、各開発者は「不正行為の議論を禁止する」「偽レビューの生成を禁止する」といったルールを自分で設定することができます。
Introducing gpt-oss-safeguard | OpenAI
https://openai.com/index/introducing-gpt-oss-safeguard/
Technical report | OpenAI
https://openai.com/index/gpt-oss-safeguard-technical-report/
gpt-oss-safeguardはgpt-ossをベースに開発されたモデルで、各開発者が独自のポリシーを設定できるように設計されています。AIのコンテンツポリシーを設定するには「禁止ワードや禁止トピックを検出できる分類器」を用意するのが一般的ですが、gpt-oss-safeguardでは分類器を用意せずとも自然言語でポリシーを指示できます。
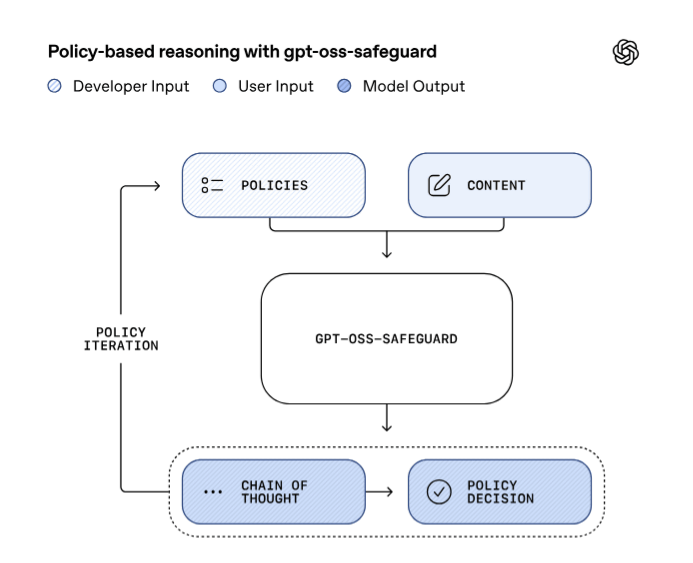
OpenAIはパラメーター数1200億の「gpt-oss-safeguard-120b」とパラメーター数200億の「gpt-oss-safeguard-20b」をApache 2.0 licenseの下で公開しています。また、社内ではgpt-oss-safeguardに追加学習を施した「Safety Reasoner」を活用しているとのこと。
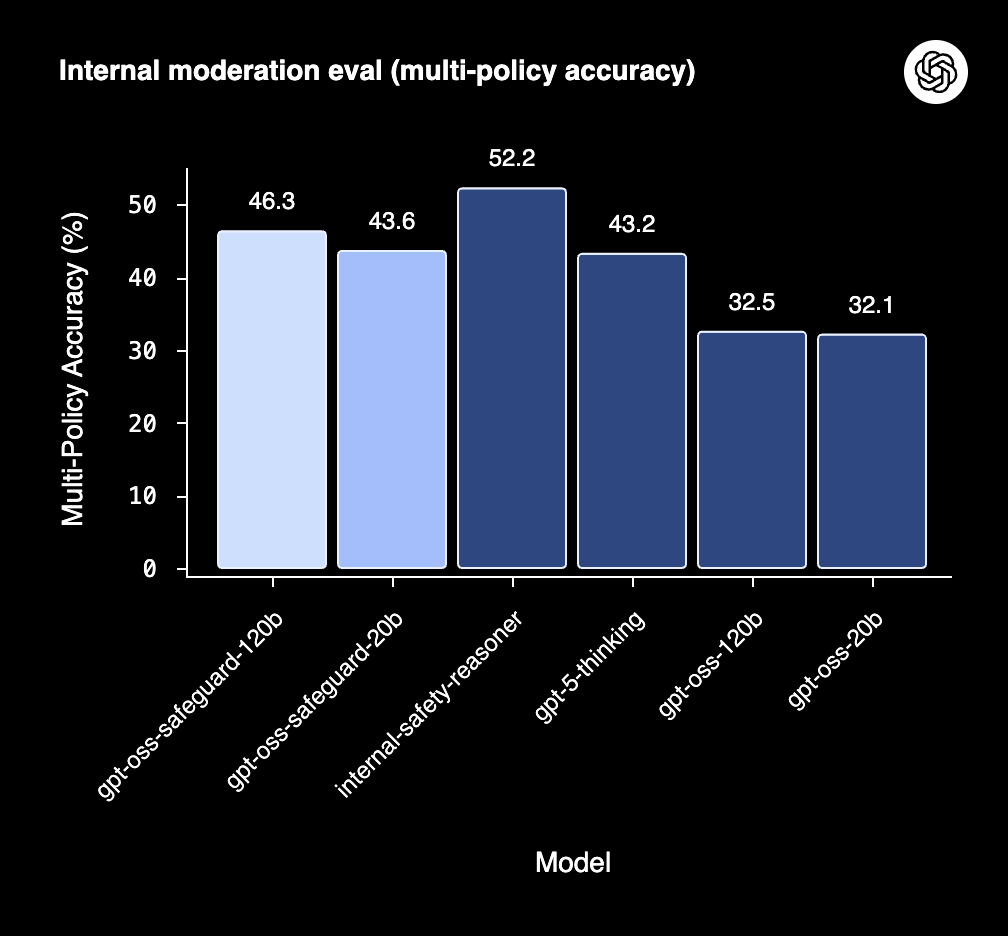
「gpt-oss-safeguard-120b」「gpt-oss-safeguard-20b」「Safety Reasoner」「gpt-5-thinking」「gpt-oss-120b」「gpt-oss-20b」のポリシーに従う制度を比較したグラフが以下。gpt-oss-safeguard-120bとgpt-oss-safeguard-20bはgpt-5-thinkingよりもポリシーに従う割合が高いことが分かります。
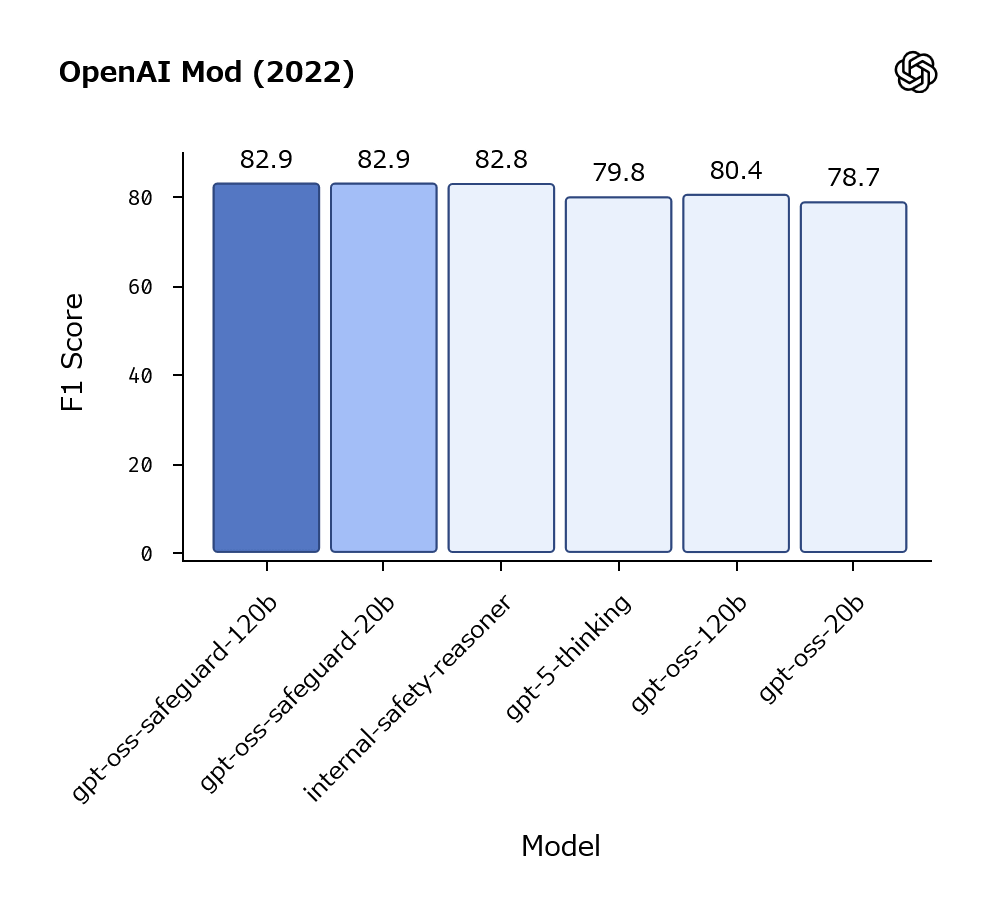
さらに、OpenAIのテスト用データセットを用いて安全ポリシーの順守度を測定した結果が以下。gpt-oss-safeguard-120bとgpt-oss-safeguard-20bはgpt-5-thinkingよりも厳格にポリシーを守ることができました。
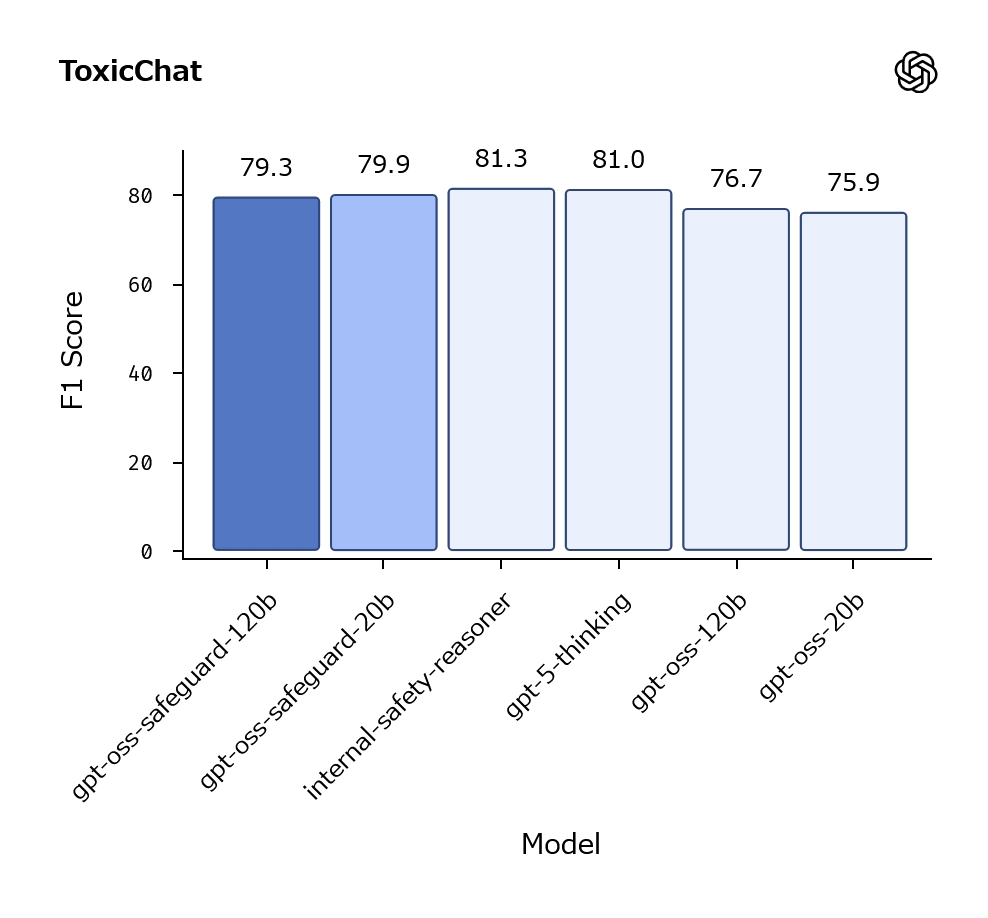
一方で、毒性データセット「ToxicChat」を用いたテストではgpt-5-thinkingよりもポリシー順守度が低くなりました。
gpt-oss-safeguard-120bとgpt-oss-safeguard-20bのモデルデータは以下のリンク先で配布されています。
openai/gpt-oss-safeguard-120b · Hugging Face
https://huggingface.co/openai/gpt-oss-safeguard-120b
openai/gpt-oss-safeguard-20b · Hugging Face
https://huggingface.co/openai/gpt-oss-safeguard-20b
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。