
Appleが独自の視覚言語モデル(VLM)となる「FastVLM」を発表しました。従来のVLMは精度が高くなると効率性が低下するという問題を抱えていたのですが、FastVLMは高い精度を保ちながら効率の面でも優れた性能を発揮しており、オンデバイスでのリアルタイムビジュアルクエリ処理に適したAIモデルになっているとのことです。
FastVLM: Efficient Vision Encoding for Vision Language Models – Apple Machine Learning Research
https://machinelearning.apple.com/research/fast-vision-language-models
GitHub – apple/ml-fastvlm: This repository contains the official implementation of “FastVLM: Efficient Vision Encoding for Vision Language Models” – CVPR 2025
https://github.com/apple/ml-fastvlm
視覚言語モデル(VLM)はテキスト入力に加え、視覚的な理解を可能にするというAIモデルです。VLMは通常、事前学習済みのビジョンエンコーダーから投影層を介して事前学習済みの大規模言語モデル(LLM)へ視覚トークンを渡すことで構築されます。ビジョンエンコーダーの豊富な視覚表現と、LLMの世界知識および推論機能を活用することで、VLMはアクセシビリティアシスタント、UIナビゲーション、ロボット工学、ゲームなど幅広いアプリケーションで活用可能です。
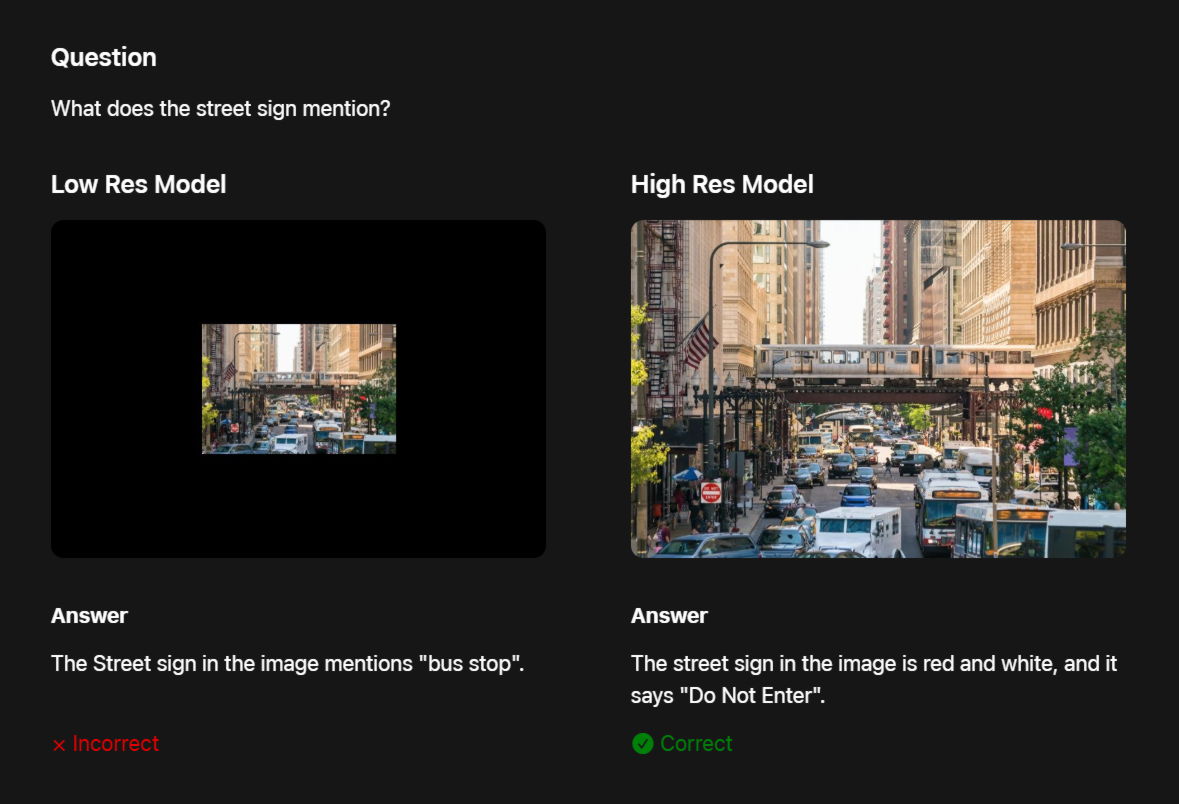
VLMの精度は一般的に入力画像の解像度が高いほど向上するため、精度と効率性の間にはトレードオフが生じます。特に、文書分析、UI認識、画像に関する自然言語クエリへの回答など、詳細な理解を必要とするタスクでは顕著です。例えば、画像に表示されている道路標識についてVLMに質問すると、入力画像が低解像度画像だと正しく応答できませんが、高解像度画像だと標識を正しく識別可能となります。
一方、多くの実稼働ユースケースにおいて、VLMはリアルタイムアプリケーションの低レイテンシー要件を満たし、プライバシー保護されたAIエクスペリエンスを実現するために、デバイス上で実行する必要があるだけでなく、精度と効率性の両方を備えている必要があります。
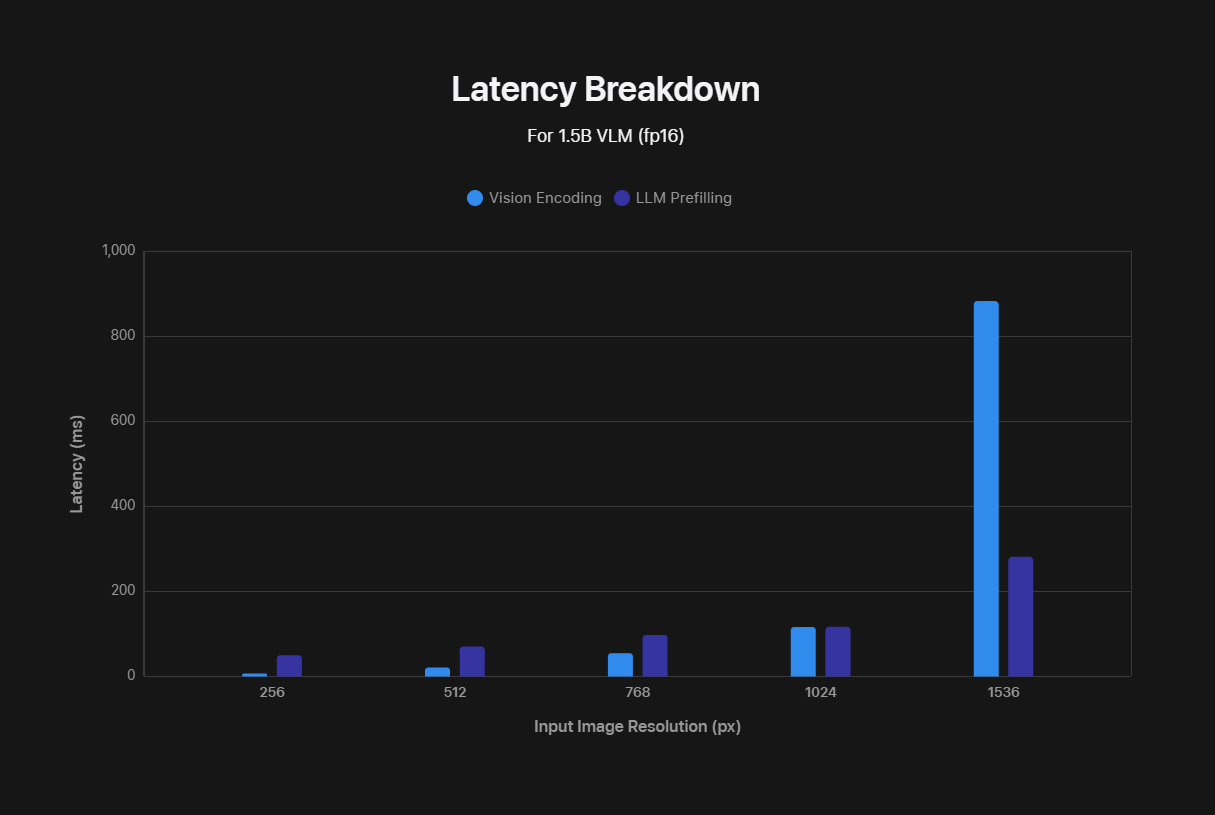
しかし、高解像度画像はVLMのレイテンシーを大幅に増加、つまりは効率性を大幅に低下させてしまいます。効率低下は2つの点で起きるそうで、ひとつは「高解像度画像ではビジョンエンコーダーの処理時間が長くなる」という点です。もうひとつは「エンコーダーがより多くのビジュアルトークンを作成するため、LLMの事前入力時間が長くなる」という点。これらの要素により、ビジョンエンコード時間とLLM事前入力時間の合計である「最初のトークンまでの時間(TTFT)」が増加します。
以下の図は画像解像度が高くなると、ビジョンエンコード時間とLLM事前入力時間がどちらも長くなることを示したもの。横軸が入力画像の解像度、縦軸がレイテンシーです。
Appleの機械学習研究者は、このようなVLMが抱える課題に独自に対処した「FastVLM」を発表しました。FastVLMはシンプルな設計で精度とレイテンシーのトレードオフを大幅に改善することに成功したVLMです。高解像度画像向けに設計されたハイブリッドアーキテクチャのビジュアルエンコーダーを活用しており、正確で高速かつ効率的なビジュアルクエリ処理を実現しているだけでなく、デバイス上で動作するリアルタイムアプリケーションの開発にも適しているとのこと。
Appleはまずどのアーキテクチャが最高の精度とレイテンシーのトレードオフを実現するかを特定するため、トレーニングデータ・レシピ・LLMなどすべてを同じものに保ち、ビジョンエンコーダーのみを変更して体系的に比較しました。調査対象となったのはFastViT、ViT-L/14、SigLIP-SO400、ConvNeXTなど。調査の結果、FastViTは他のVLMと比較して最高の精度とレイテンシーのトレードオフを実現していることが明らかになっています。
FastViTは効率的なVLMに最適な選択肢ですが、困難なタスクにおける精度向上にはより大規模なビジョンエンコーダーが必要です。当初、AppleはFastViTの各レイヤーのサイズを単純に拡大しようとしたそうですが、この単純なスケーリングでは高解像度画像において、FastViTは完全な畳み込みエンコーダーよりも効率が悪くなってしまう模様。この問題に対処するため、Appleは高解像度画像専用の新しいバックボーンとなるFastViTHDを設計しました。FastViTHDはFastViTに比べてステージが追加されており、MobileCLIPを使用して事前学習することで、より少ない数でより高品質なビジュアルトークンを生成可能となります。
FastViTHDはFastViTと比較して高解像度画像でのレイテンシーが優れていますが、VLMにおいてどちらが優れているかを評価するために、様々なサイズのLLMと組み合わせた場合のパフォーマンスも比較しています。画像解像度とLLMサイズの異なる組み合わせおよび、異なるパラメーターを持つ3つのLLMを評価し、異なる解像度で動作するビジョンバックボーンと組み合わせました。その結果、同じ精度で最大3倍もFastViTHDが高速に動作可能であることが明らかになっています。
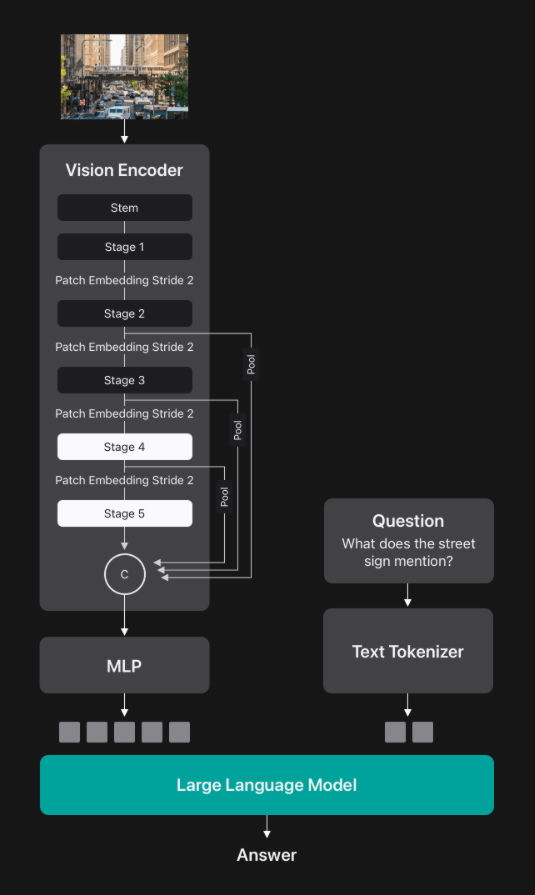
このFastViTHDをビジョンエンコーダーとして使用し、ビジュアルトークンをLLMの埋め込み空間に投影するシンプルな多層パーセプトロン(MLP)モジュールを備えたVLMがFastVLMです。
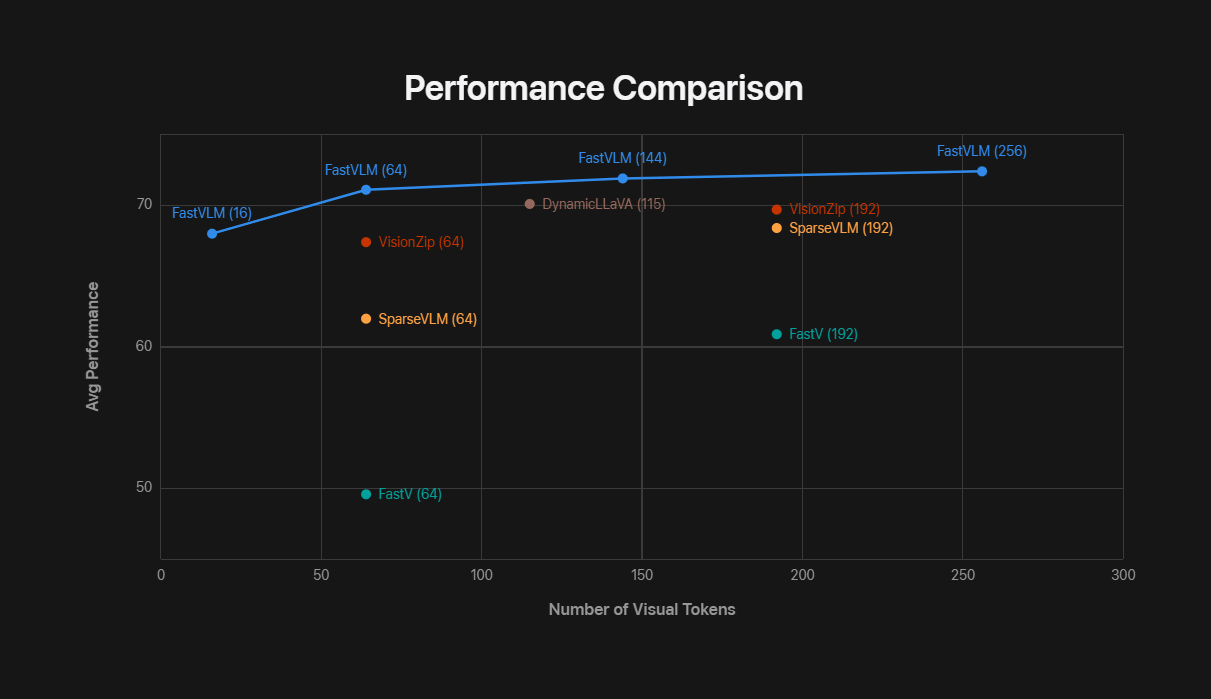
以下のグラフは、FastVLMとその他VLMのパフォーマンスおよび必要とするビジュアルトークン数を比較したもの。横軸がビジュアルトークン数、縦軸がさまざまなVLMタスクにおける平均パフォーマンスを示しています。
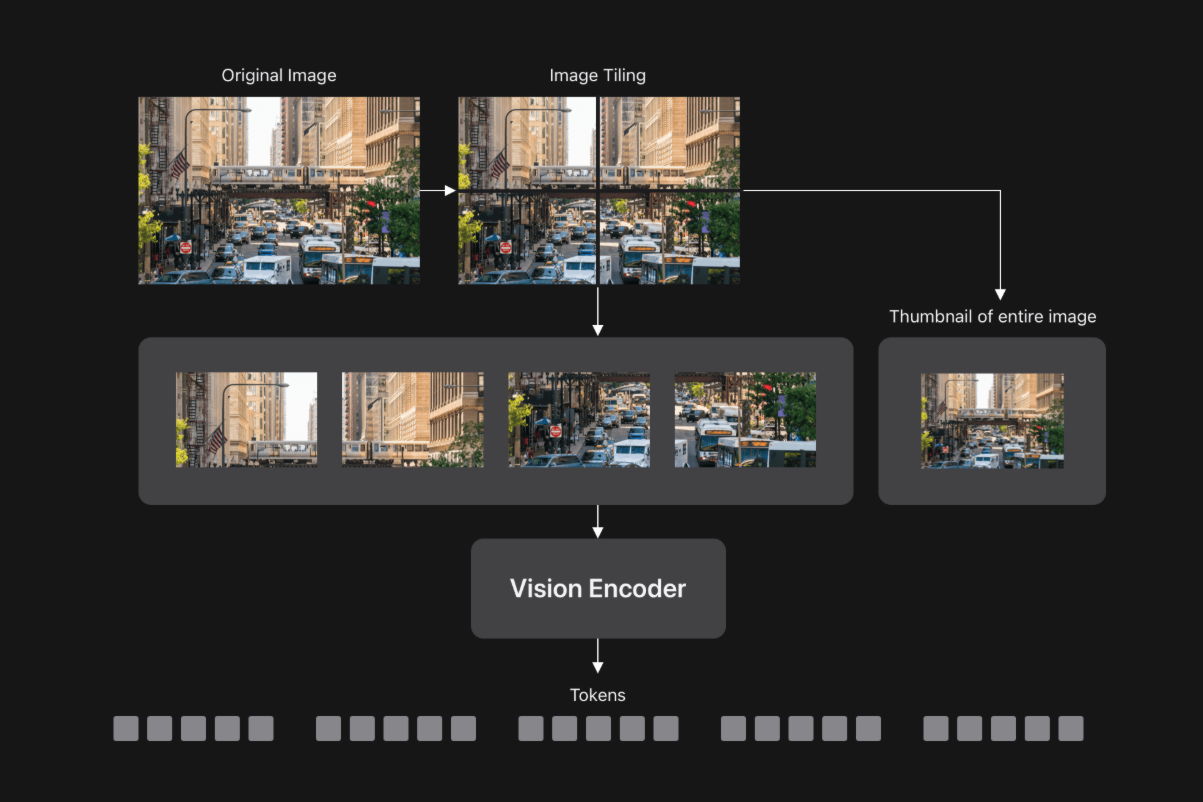
FastVLMは高解像度画像を高速に処理するため、画像を小さく分割し、分割した画像をビジョンエンコーダーで個別に処理したあと、すべてのトークンをLLMに送信します。
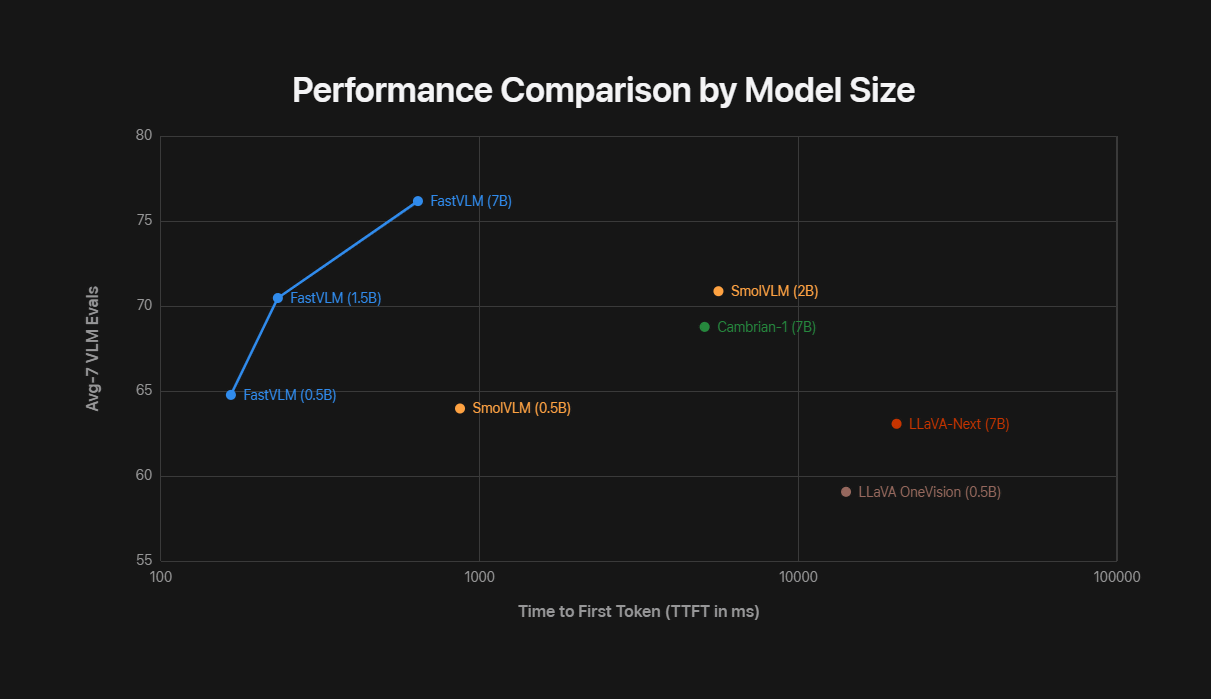
これによりFastVLMは同等サイズのVLMよりも高速かつ正確に動作可能です。以下のグラフは横軸がTTFT、縦軸が7つのVLMベンチマークにおけるパフォーマンスの平均値を示しています。FastVLMはパフォーマンスだけでなく、圧倒的にTTFTが短い、つまりは効率性が高いです。
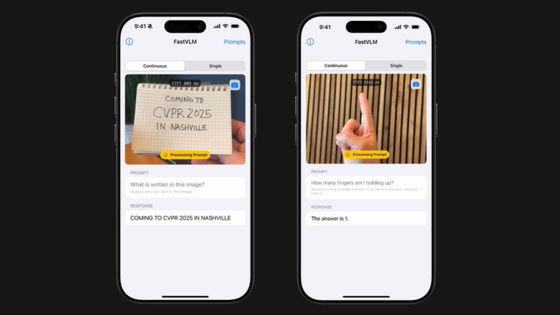
以下はiPhone上でローカルにFastVLMを実行した例です。ほぼリアルタイムで正確に入力画像の内容を認識することに成功していることがわかります。
VLMは視覚的理解とテキスト理解を組み合わせることで、様々なアプリケーションを実現可能です。これらのモデルの精度は一般的に入力画像の解像度に対応するため、精度と効率性の間でパフォーマンスのトレードオフが生じることが多く、高い精度と優れた効率性の両方が求められるアプリケーションではVLMの価値が限られていました。
FastVLMは高解像度画像向けに構築されたハイブリッドアーキテクチャのビジョンエンコーダであるFastViTHDを活用することで、このトレードオフに対処。シンプルな設計により、FastVLMは精度と効率の両方において従来のアプローチを凌駕しており、リアルタイムのデバイス内アプリケーションに適したデバイス内ビジュアルクエリ処理を実現できるとAppleは主張しています。
なお、AppleのMLXをベースとした推論コード、モデルチェックポイント、iOSおよびmacOSデモアプリのコードがGitHubで公開されています。
GitHub – apple/ml-fastvlm: This repository contains the official implementation of “FastVLM: Efficient Vision Encoding for Vision Language Models” – CVPR 2025
https://github.com/apple/ml-fastvlm
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。