
Alibabaの大規模言語モデル「Qwen」の研究チームが、コーディングに特化したエージェントモデル「Qwen3-Coder」を発表しました。パラメータ数4800億・アクティブパラメータ数350億のモデル「Qwen3-Coder-480B-A35B-Instruct」は、Claude Sonnet 4に匹敵する最先端の結果を達成しています。
Qwen3-Coder: Agentic Coding in the World | Qwen
https://qwenlm.github.io/blog/qwen3-coder/

GitHub – QwenLM/Qwen3-Coder: Qwen3-Coder is the code version of Qwen3, the large language model series developed by Qwen team, Alibaba Cloud.
https://github.com/QwenLM/Qwen3-Coder
Qwen3-Coderの大きな特徴は、ネイティブで256Kトークンという広大なコンテキスト長をサポートするだけでなく、「YaRN(Yet another RoPE-based scaling method)」という拡張技術を用いることで最大100万トークンまで対応可能である点です。これにより、リポジトリ全体を理解するような大規模なタスクにも対応できます。また、C++、Java、Python、Ruby、Swift、ABAPなどを含む358もの多様なプログラミング言語をサポート。加えて、ベースモデルから一般的な能力と数学的能力を維持しつつ、コーディングに特化しているとのこと。
さらに、その能力を最大限に引き出すため、エージェントコーディング用のコマンドラインツール「Qwen Code」も同時にオープンソース化されています。このQwen CodeはGemini Codeをフォークして開発されています。
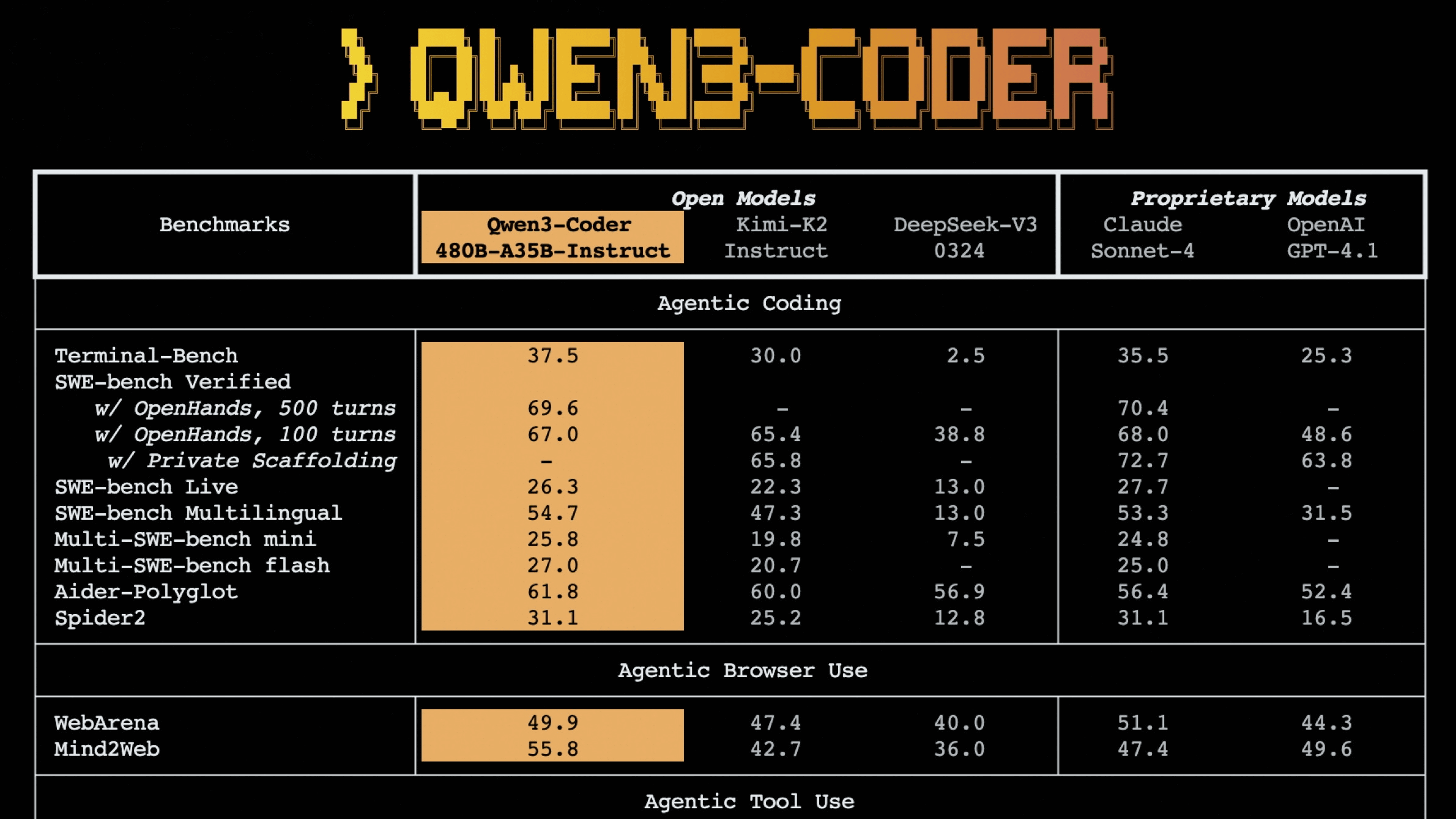
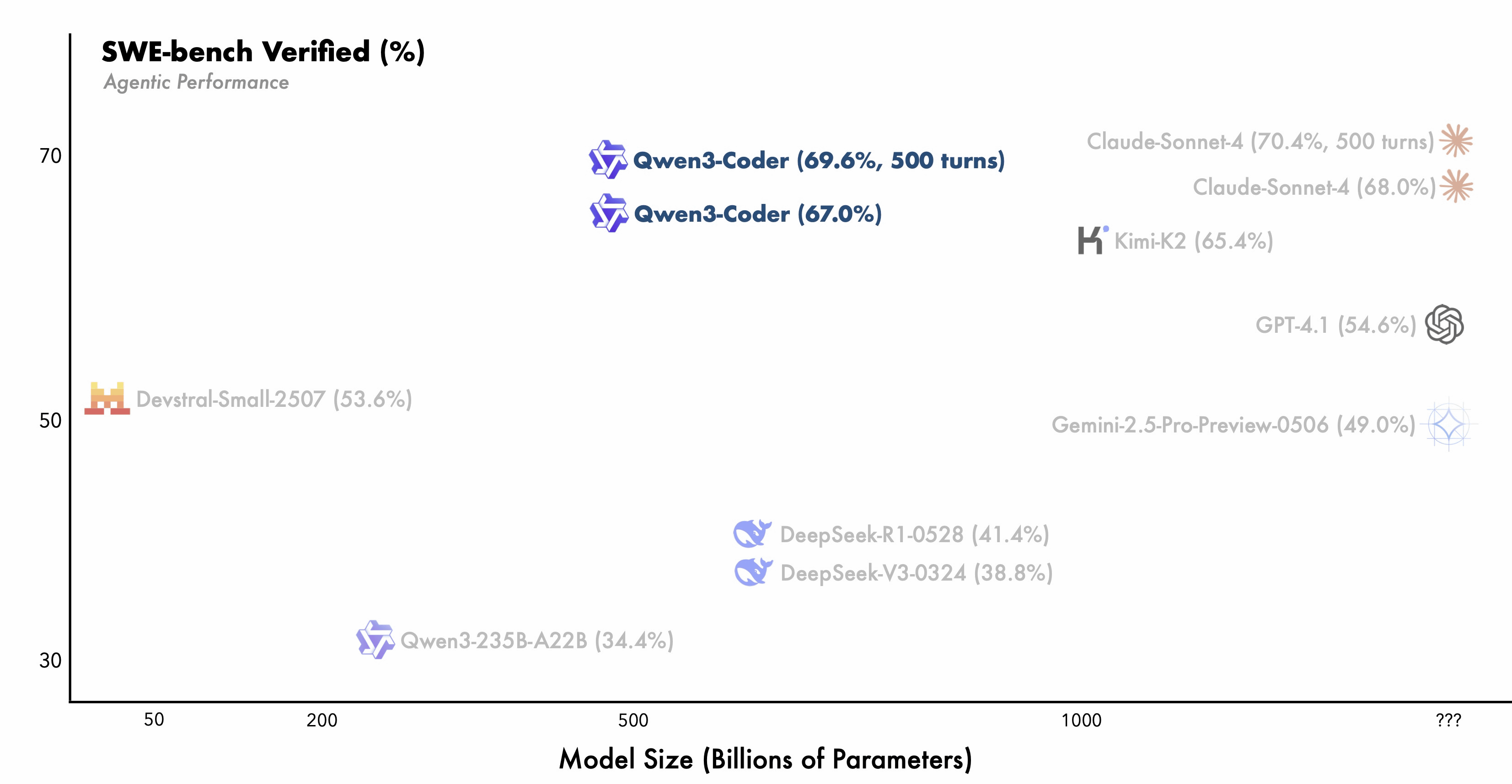
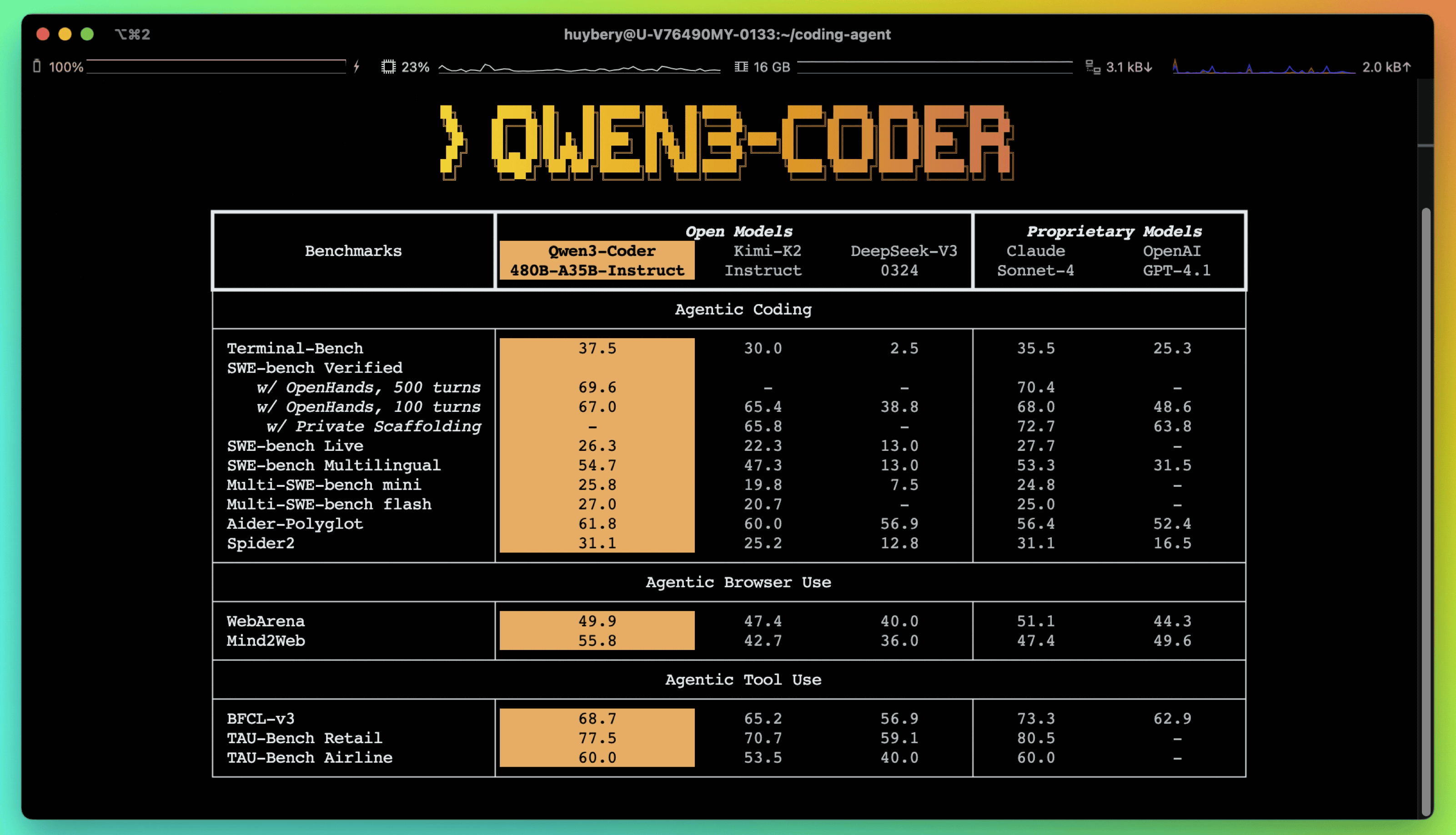
性能面では、Qwen3-Coderは、オープンソースモデルの中でエージェントコーディング、エージェントによるブラウザ操作、そしてエージェントによるツール使用といった分野で新たな最高水準の記録を樹立したとAlibabaは強調しています。ソフトウェアエンジニアリングのタスクを評価するSWE-Bench Verifiedにおいて、Qwen3-CoderはCloud Sonnet 4よりも小さいモデルサイズでほぼ同等のスコアを記録しています。
Alibabaによると、事前学習の段階では7兆5000億トークンという膨大なデータが使用され、その70%がコードで構成されているとのこと。また、Qwen2.5-Coderを活用してノイズの多いデータをクリーンアップして書き換えることで、データ全体の品質を大幅に向上させたそうです。
事後学習では、2つの重要な強化学習(RL)が大規模に導入されました。まず、多様な実世界のコーディングタスクに対してコード強化学習(Code RL)を適用し、コード実行の成功率を大幅に向上させています。さらに、SWE-Benchのような複数ターンにわたる対話を必要とするタスクに対応するため、長期的な視野での強化学習が導入されました。この実現にはAlibaba Cloudのインフラが活用されており、およそ2万種類の独立した環境を並列で実行できるような拡張性の高いシステムが構築されています。
Qwen3-Coderは複数のモデルがあるとのことですが、記事作成時点では「Qwen3-Coder-480B-A35B-Instruct」がHugging FaceおよびModelScopeで入手可能。また、推論の効率化に貢献するFP8で量子化されたモデル「Qwen3-Coder-480B-A35B-Instruct-FP8」もHugging FaceおよびModelScopeで提供されています。さらに、Alibaba Cloud Model Studioを介してQwen3-CoderのAPIに直接アクセス可能です。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。