

中国の大手テクノロジー企業「Alibaba」のAI研究チームが低コストかつ高性能なAIモデル「Qwen3-Next」を開発して無料公開しました。Qwen3-Nextは従来モデルと比べて10分の1以下のコストでトレーニングされており、入力トークンが多い状況では10倍以上高速な推論処理が可能。それでいて、性能は従来モデルと同等以上で、一部のテストではGoogleのGemini-2.5-Flash-Thinkingを上回っているとアピールされています。
Qwen3-Next: Towards Ultimate Training & Inference Efficiency
https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list
Qwen3-Nextのベースモデルである「Qwen3-Next-80B-A3B-Base」は複数の専門家モデルを内包するMixture of Experts (MoE)アーキテクチャを採用したモデルです。従来のトレーニング方法とは異なり、Gated DeltaNetとGated Attentionを3:1の割合で用いることで性能の高さとトレーニングコストの低さを両立しているとのこと。
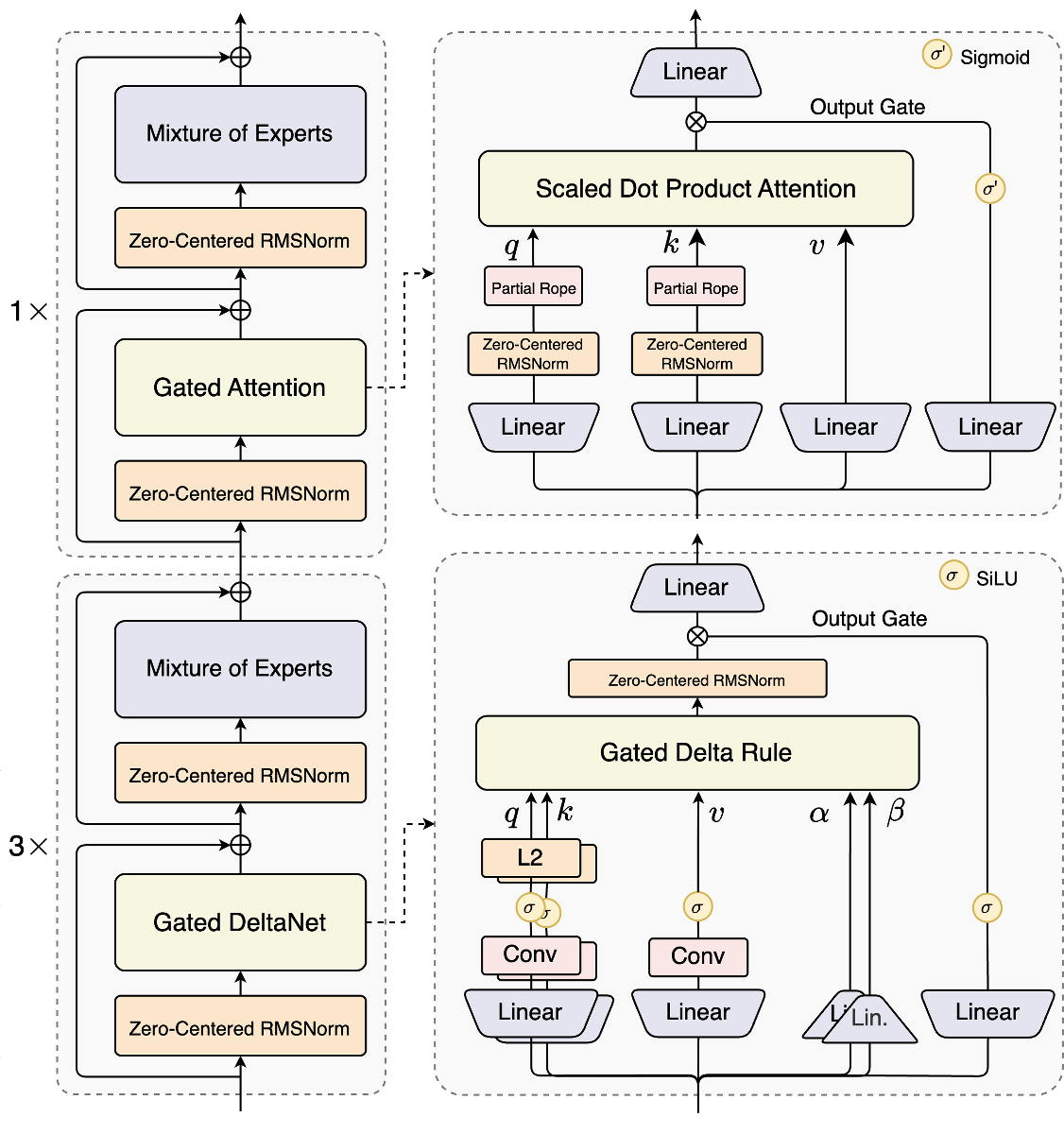
Qwen3-Next-80B-A3B-BaseはQwen3-32Bと比べて10.7倍高速にトレーニング可能。それでいて、ベンチマークスコアはQwen3-32Bを上回っています。
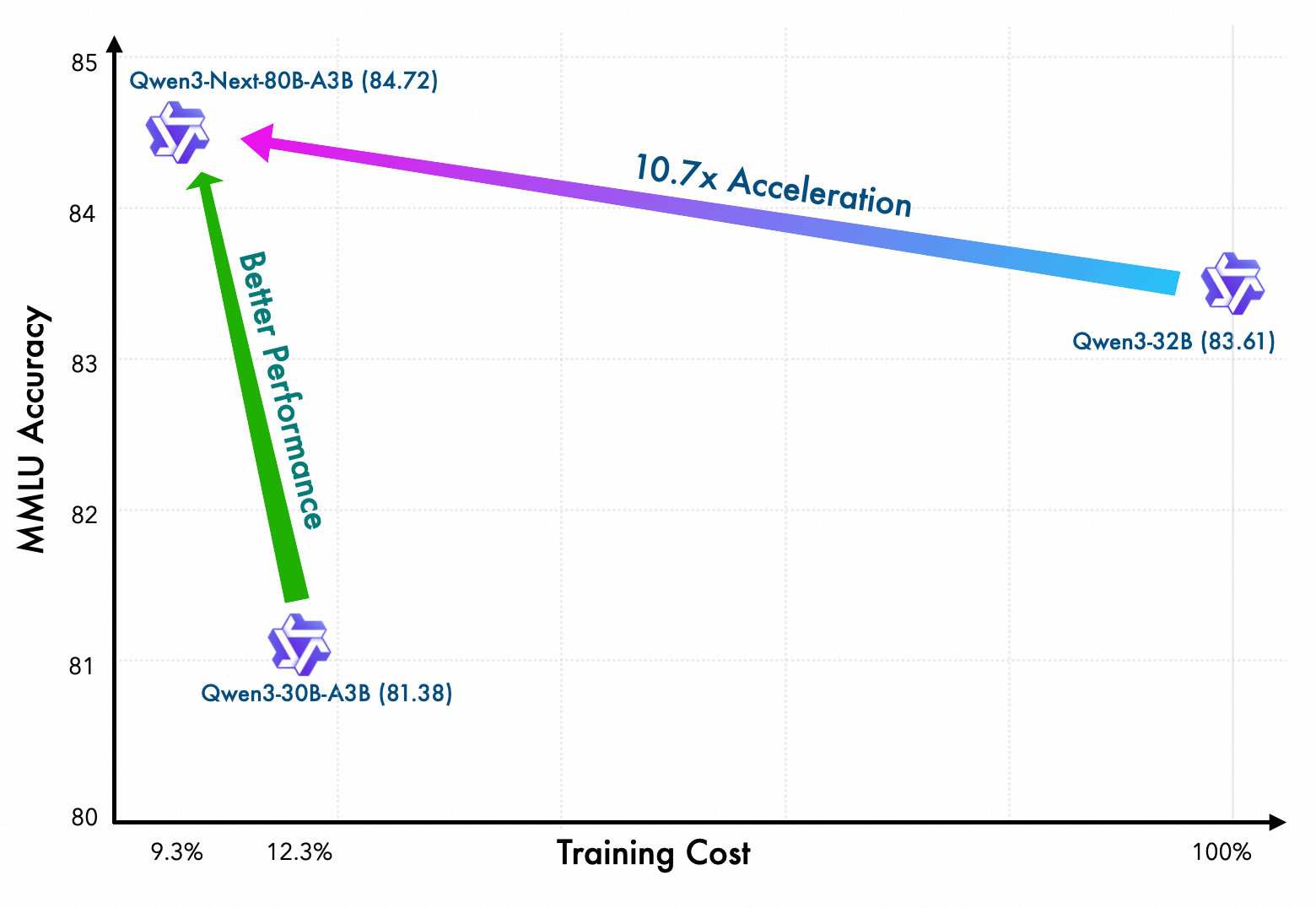
Qwen3-Next-80B-A3B-Baseは512の専門家モデルが含まれる800億パラメータのモデルですが、実際の推論処理では最大30億パラメータのみがアクティブになります。処理速度は従来モデルと比べて大きく向上しており、入力トークン数が3万2000の場合、最初のトークンを出力するまで(Prefillフェーズ)のスピードはQwen3-32Bと比べて10.6倍高速で、それ以降(Decodeフェーズ)の出力速度は10倍高速です。
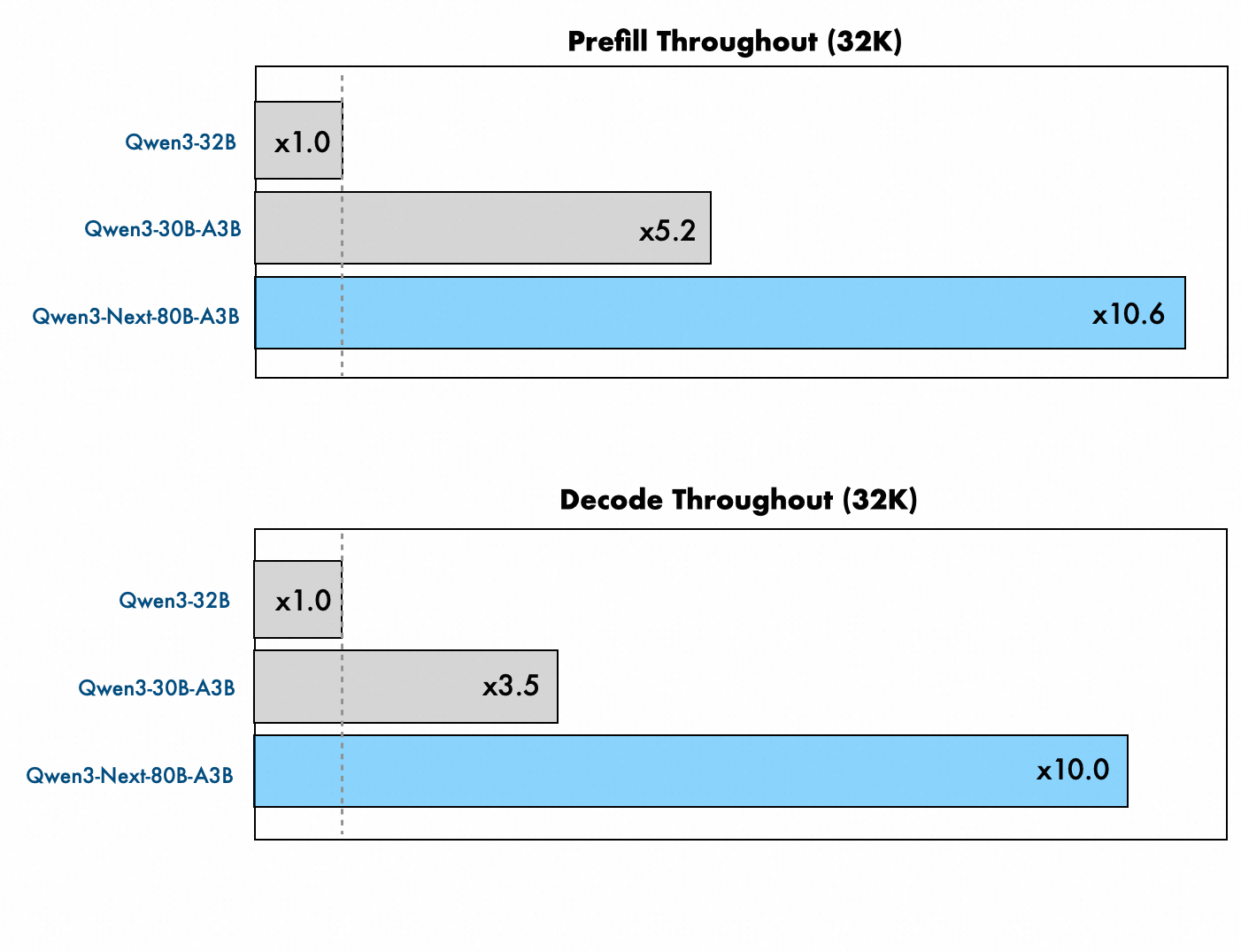
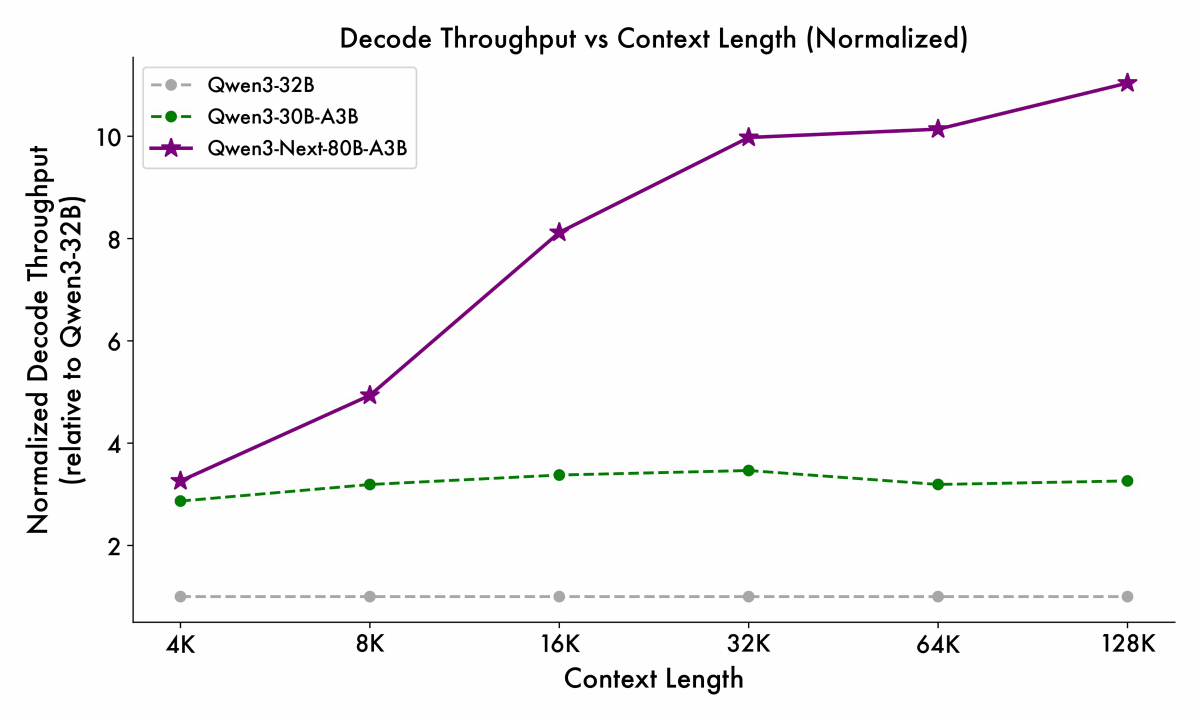
「Qwen3-32B(白)」「Qwen3-30B-A3B(緑)」「Qwen3-Next-80B-A3B-Base(紫)」の3モデルで入力トークン数ごとの最初のトークンを出力するまでの時間を比較したグラフが以下。Qwen3-Next-80B-A3B-Baseの優位性は入力トークンが多くなっても衰えません。
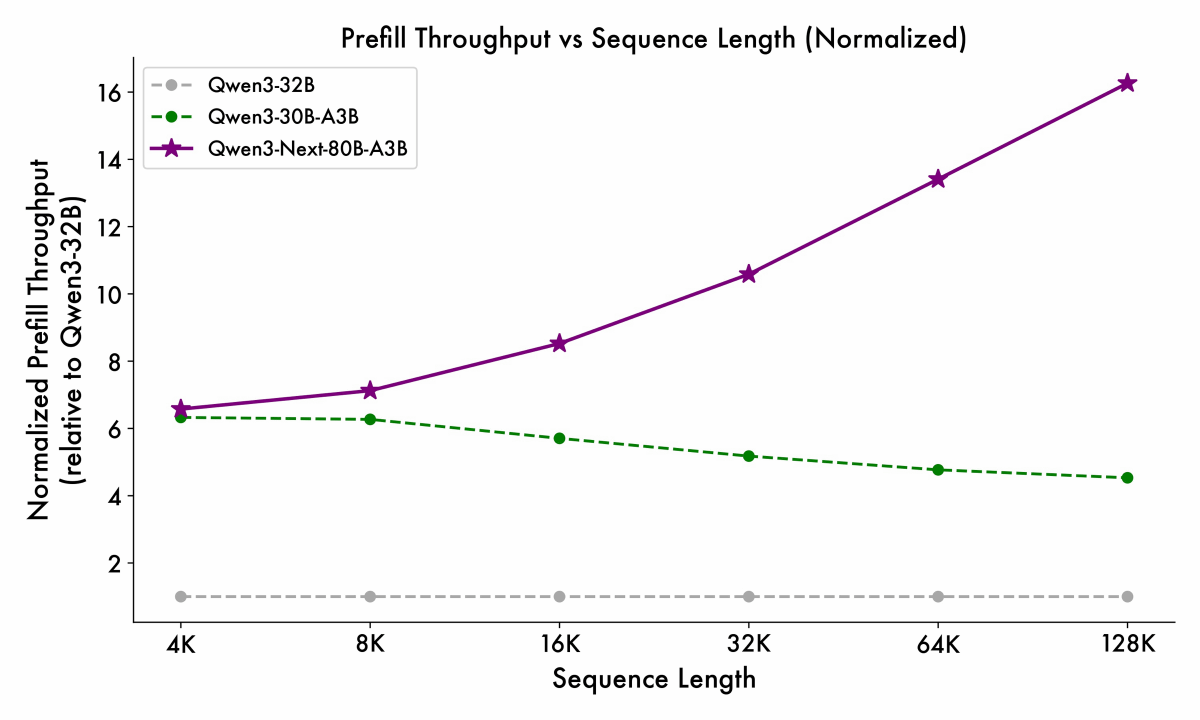
Decodeフェーズでも同様に入力トークンが多くなっても高速な処理が可能です。
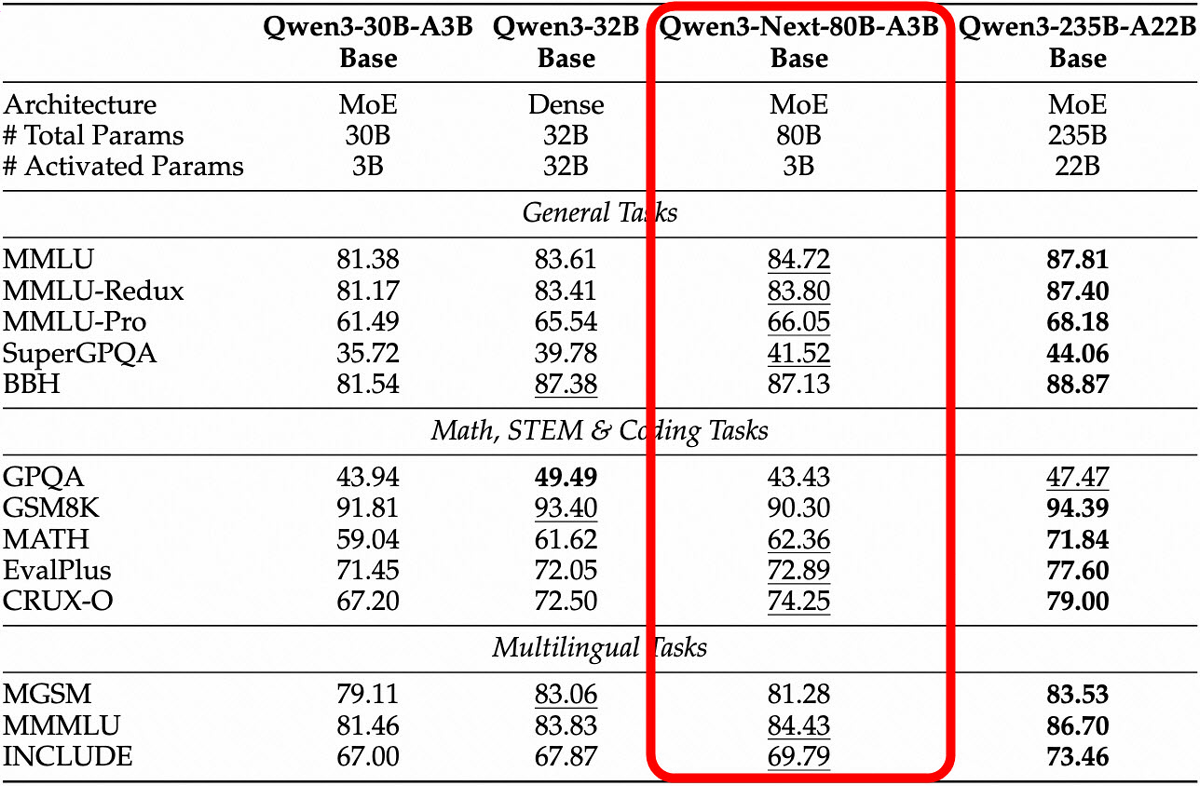
以下の表は、Qwen3-Next-80B-A3B-Baseの各種ベンチマークの結果をまとめたものです。Qwen3-Next-80B-A3B-Baseは低コストかつ高速ながら旧来のモデルと同等以上のスコアを記録しています。
開発チームはQwen3-Next-80B-A3B-Baseをもとに微調整を施した「Qwen3-Next-80B-A3B-Instruct」と「Qwen3-Next-80B-A3B-Thinking」を以下のリンク先で無料公開しています。
Qwen3-Next – a Qwen Collection
https://huggingface.co/collections/Qwen/qwen3-next-68c25fd6838e585db8eeea9d
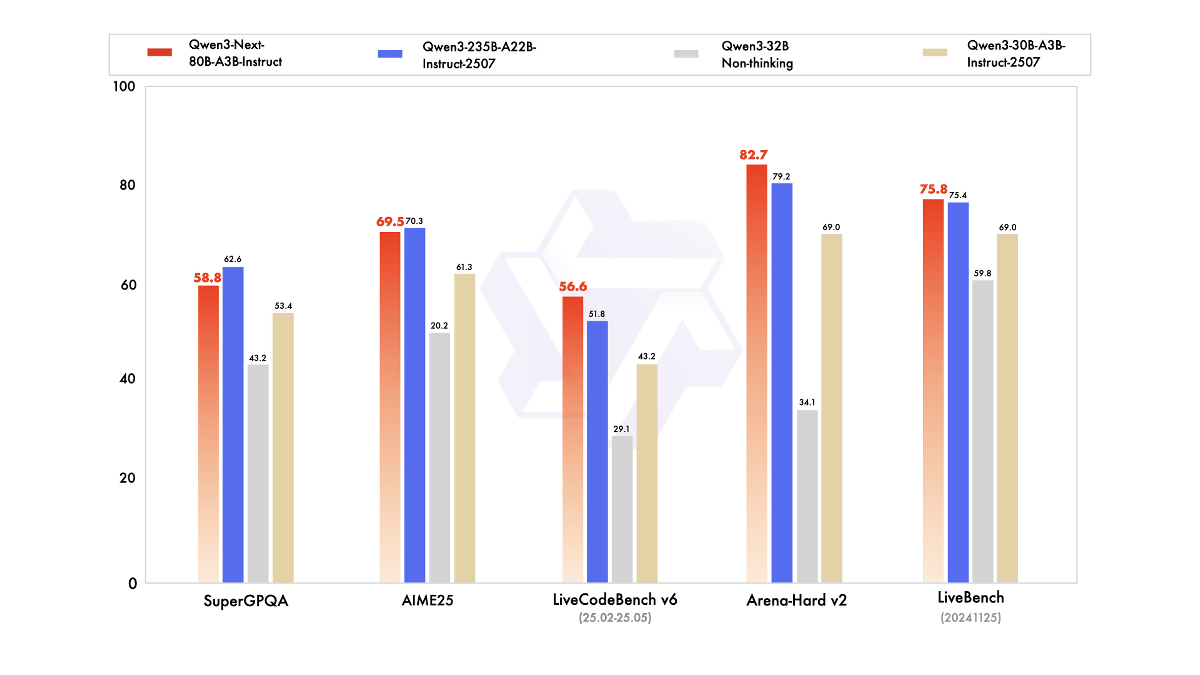
Qwen3-Next-80B-A3B-Instruct(赤)の性能を示したグラフが以下。
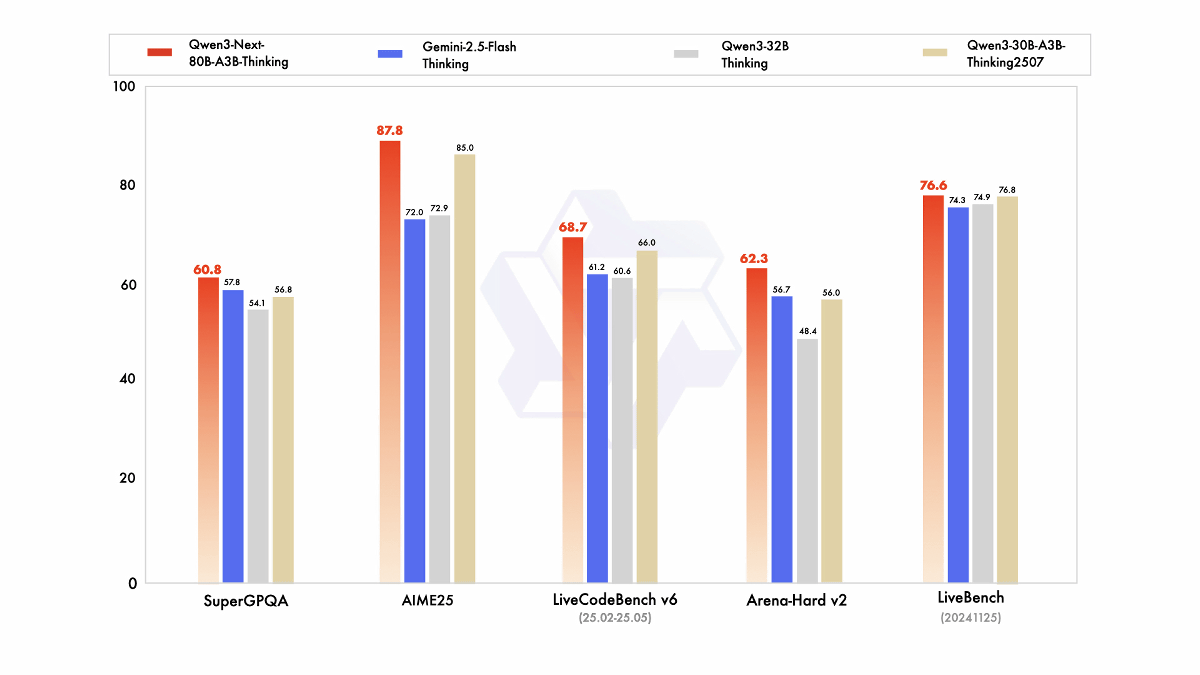
推論モデルであるQwen3-Next-80B-A3B-Thinking(赤)は、すべてのテストで旧来のモデルを超えるスコアを記録しています。開発チームによると複数のベンチマークテストでGoogleのGemini-2.5-Flash-Thinkingを上回っているそうです。
開発チームは将来のQwen3.5のリリースに向けてアーキテクチャの改善に取り組む姿勢を示しています。
この記事のタイトルとURLをコピーする
ソース元はコチラ
{kind=link}
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。