

こんにちは!Data Intelligenceチームのキムです。
GoogleのAIモデル「Gemini 2.5 Pro」が正式に公開され、無料プランでも利用できるようになりました。*1
公式ドキュメントによると、「オブジェクト検出に加えて、強化されたセグメンテーションをサポートするようにさらにトレーニングされています」*2 とのことなので
どのぐらい実用的に進化したのか、公開されているColabノートブックを使って「Gemini 2.5 Pro」の画像処理機能を試してみました。
同じく注目される「GPT-5」との物体検出精度についても比較してみましたので、その結果と感想を共有したいと思います。
目次
それでは、以下の公式ドキュメントで公開されている Google Colabノートブックを使って、実際に試してみましょう!
事前準備
Google Colabノートブックを使用するには、以下の項目を事前に準備しておく必要があります。
-
Googleアカウント:APIキーの発行や、Colabノートブックの実行に使用します。
-
APIキー:Geminiモデルの機能をColabノートブック内で使用する際に必要です。事前にAPIキーを取得しておく必要があります。
-
Colabノートブック:公式ドキュメントで公開されているColabノートブックを準備します。
APIキー
まだGeminiのAPIキーを取得していない方は、まずAPIキーを発行する必要があります。
Google AI Studio にアクセスしてログインした後、「Get API key」-「APIキーを作成」 をクリックします。
以下のようなポップアップが表示された場合、プロジェクトを選択し、「既存のプロジェクトでAPIキーを作成」ボタンをクリックしてキーの作成を完了します。
作成が完了すると、画面下部にてAPIキーを確認できます。
Colabノートブック
コード実行のため、以下の2つのColabノートブックをダウンロード、またはGoogleドライブにコピーしておきましょう。
あわせて、先ほど発行したAPIキーを GOOGLE_API_KEY という名前でシークレットに登録してください。
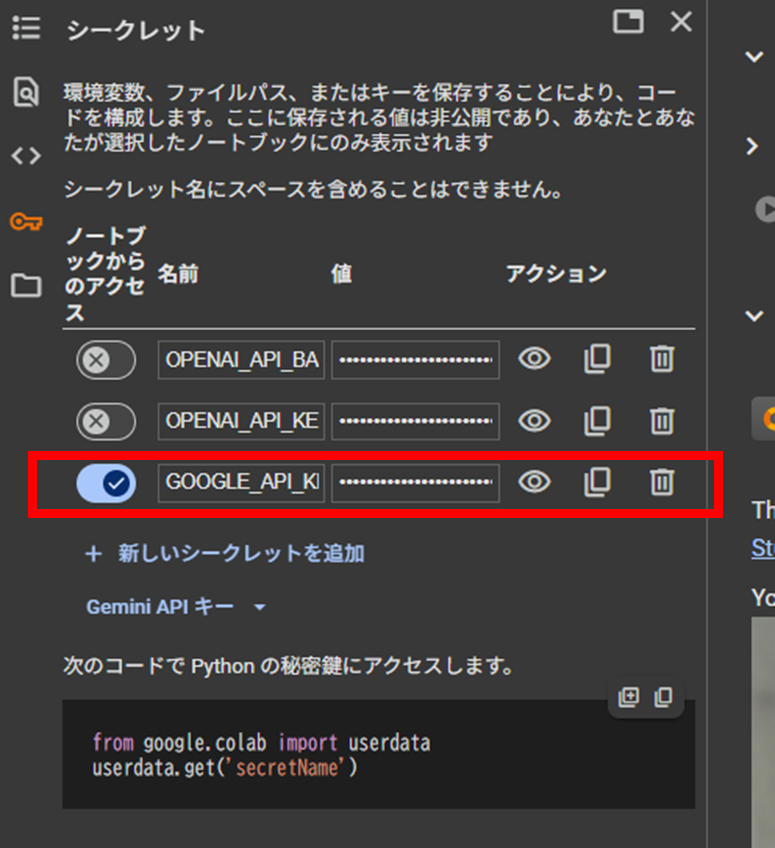
内容
2つのColabノートブックを使って、以下の機能を検証します。
「Spatial_understanding.ipynb」では物体検出を、「Spatial_understanding_3d.ipynb」では3D空間におけるマルチビュー機能を試し、それぞれの結果を確認していきます。
物体検出
Colabノートブック上で提供するカップケーキの画像を用いて、物体検出を行います。
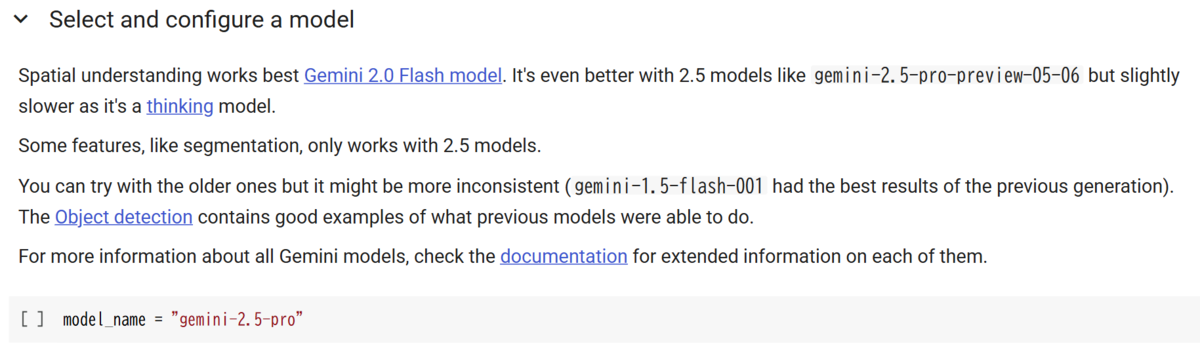
まず、モデル名として gemini-2.5-pro を指定します。
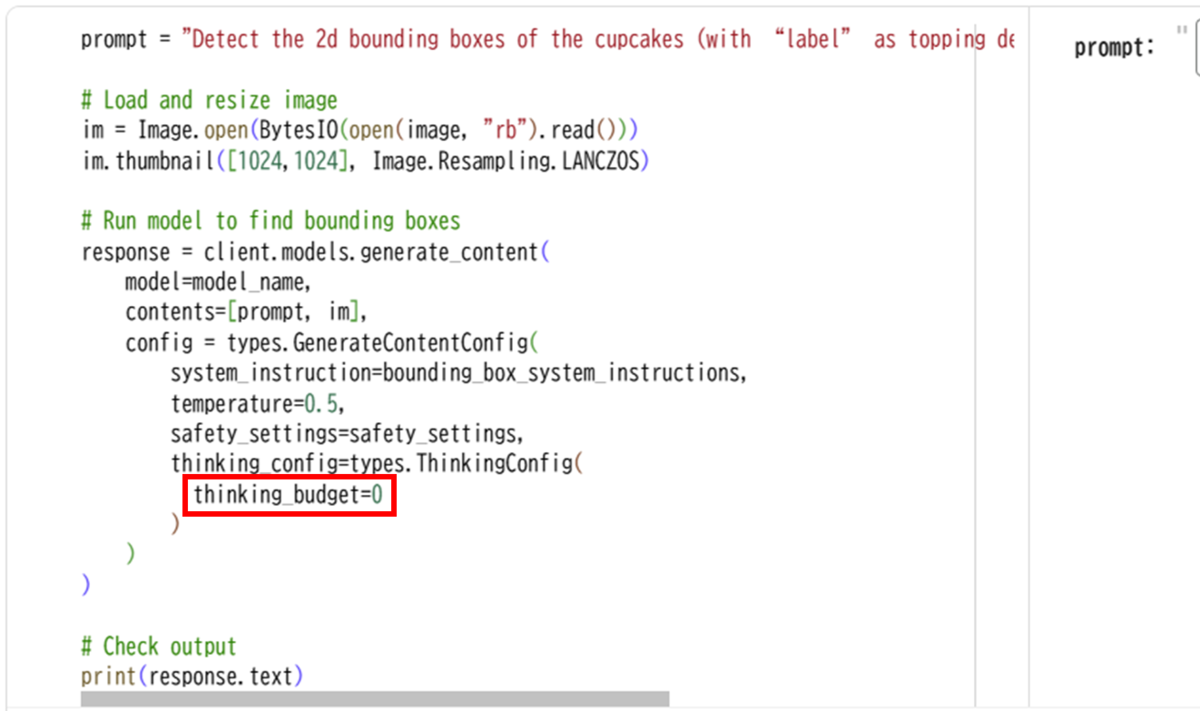
そのあと、以下のコードブロックを実行し、各カップケーキのバウンディングボックスとラベル情報を取得します。
元のコードブロックでは、デフォルトで思考予算がオフ(thinking_budget= 0)に設定されています。
しかし、gemini-2.5-pro モデルは思考予算を無効にすることができないため、thinking_budget= -1 に設定して動的思考をオンにします。*3
思考予算を手動で指定したい場合は、有効な範囲内で直接数値を設定することも可能です。
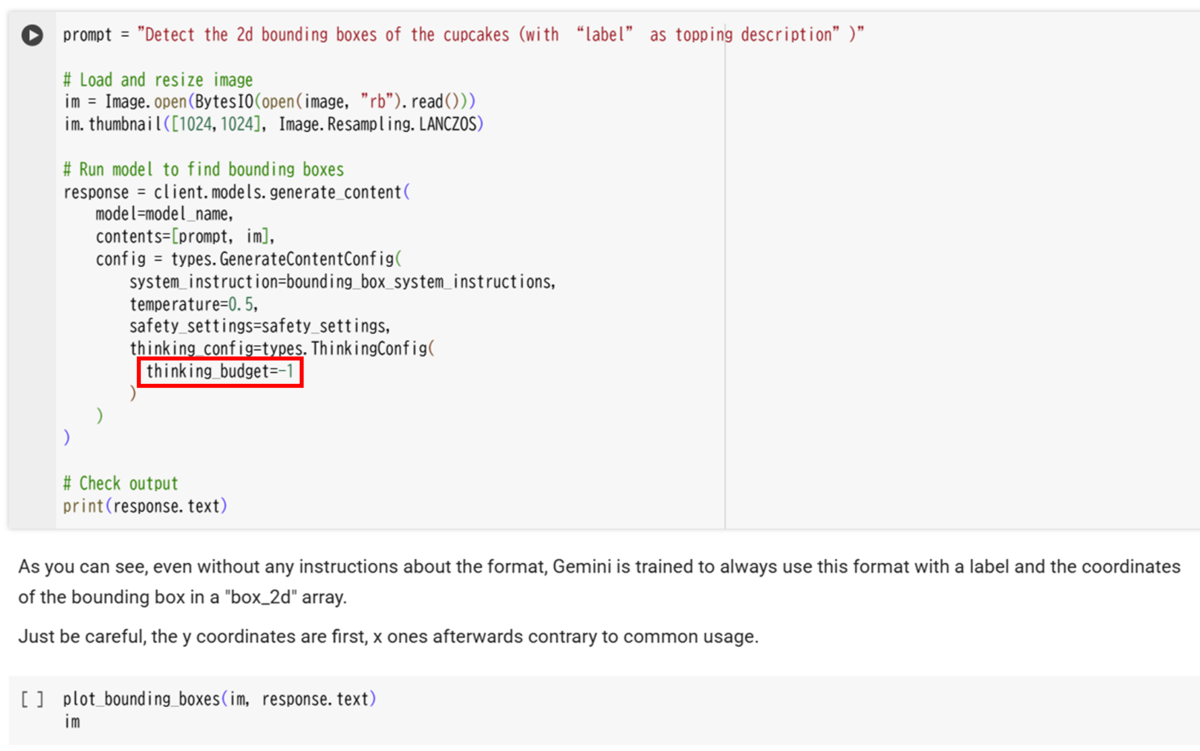
上記の画像にある最後のコードブロックを実行することで、画像上にバウンディングボックスが描画されます。
結果
以下の画像は、Gemini 2.5 Proモデルを使用して物体検出を行った結果です。
画像に写っている13個のカップケーキをすべて正確に検出できていることがわかります。バウンディングボックスの位置やラベルもかなり精度が高いです。


ちなみに、GPT-5モデルではどのような結果が得られるのかも気になるところです。
以下は、GPT-5モデルを用いて物体検出を行った結果です。

Gemini 2.5 Proモデルの結果と比較すると、バウンディングボックスの位置が物体からずれていることがわかります。
それだけでなく、カップケーキだけを検出しているGeminiモデルとは異なり、GPT-5モデルでは背景の物体まで検出されてしまうことがあります。
3Dマルチビュー
次に、2つ目のColabノートブックを使って、3Dマルチビュー機能を試してみたいと思います。
ここでは、Geminiに3Dシーンを提示し、特定のポイントにラベルを付けるように指示します。
そして、そのシーンを別の視点から見せたときに、Geminiが同じポイントを正しく認識し、同じラベルを適用できるかを確認します。
Gemini 2.5 Proモデルを使用するため、 先ほどと同様に事前にモデルを切り替え、使用するサンプル画像を読み込んでください。
3Dマルチビューでは、2種類の画像を使用します。
1つ目は、カメラの角度だけを変えた画像です。


2つ目はカメラの角度だけでなく、シーン内の物体構成にも変化があります。
たとえば、最初の画像にあった「引き出し」は、2枚目の画像には存在しません。


画像の準備が整ったら、以下のコードブロックを実行して結果を確認します。
結果
1つ目の画像の実行結果を見ると、カメラの角度が異なっていても、靴やカバンといった物体に対して正確にラベルが付けられていることが分かります。


2つ目の画像の場合、Gemini 2.5 Proモデルは存在しない物体である「引き出し(c)」はラベリングせず、他の物体については正確にラベルを維持しています。


本記事では、2種類のColabノートブックを使ってGemini 2.5 Proモデルを試してみました。
プロンプトだけでここまでの精度で画像認識が可能になるとは驚きです。
テキストだけで高度な画像理解が実現できる時代になっていることを改めて実感しました。
こちらに興味のある方は、ぜひ様々な画像で試してみてください!
{kind=link}