

サービスが成長するにつれてデータベースは肥大化する。
肥大化したデータベースは最初は良かった設計も、パフォーマンスの低下やメンテナンスが難しくなる。
もちろん、そうならないように最初から設計を工夫することもできるが、サービスの成長に伴い要件が変化することも多い。
そうなると全ての変更を予見することは難しいため、データベースのリファクタリングは必要不可欠だ。
実際にAIを利用したソフトウェア開発が主流になっていきつつある昨今はよりデータベースの成長速度は加速している。
だからこそ、データベースリファクタリングは重要であり、AIが台頭して来た時代でも変わらず必要なスキルである。
そこで今回は実際にサービスの成長と共にデータベースをリファクタリングする際の戦略と実践的な手法について解説する。
なお、AI時代でもデータベースの技術が重要であることは変わらない話はこちらを参照されたい。
今は絶版になった名著『データベースリファクタリング』があるが、20年近く前の本であり、現在のサービス開発におけるデータベースのリファクタリングには必ずしも適していない。
実際にはツールの変化やアーキテクチャの変化もあり、データベースリファクタリングの事情も変わってきている。
そこで、ここでは現在のサービス開発におけるデータベースリファクタリングの戦略と実践的な手法を紹介する。
書籍『データベースリファクタリング』に書かれている戦略についてはこちらを参照されたい。
基本的な戦略は昔からベースは変わっていない。
この4つのステップである。
リファクタリングの目的を明確にし、そのリファクタリングによって、どんな効果を得たいのかを最初に整理することは重要である。
そしてゴールの形から逆算して、ステップを決めていく。
例えば削除フラグを廃止する場合にどんなメリットを求めていて、そのためにどんな形にしたいのかを明確にする。
そうすることで、リファクタリングのステップを決めやすくなる。
またサービスがそれなりに成長している場合、データベースには負債が蓄積していることが多い。
しかし全てを同時にリファクタリングすることはリスクが大きいため、システムリプレースのようなビッグバンリリースは避けるべきである。
小さく優先順位を絞ってリファクタリングを進めることは名著データベースリファクタリングにも同様のことが書いてあり、腐った牛乳とチーズの例が紹介されている。
チーズは確かに負債ではあるが、ビジネスにも生産性にも寄与しており、早急に対応するべきものではない。
反面、腐った牛乳を放置しておくと、ビジネスに悪影響を与える可能性があるため、まずは腐った牛乳を取り除くことからやろう、という話である。
そうやって改善したいテーブルに優先順位をつけて、そのテーブルがどんな形になればよいかを決めていくのである。
対象を決めたら、その対象をどのようにリファクタリングしていくかを決める。
データベースリファクタリングはアプリケーションよりもリスクが高く、複数のアプリケーションが一つのデータベースを参照しているような場合は一足飛びにリファクタリングすることは難しい。
そこで、段階的にリファクタリングを進めるためのステップを決める。

段階的に進める方針の例としては、後述のダブルライトを用いて新旧構造の双方に書き込み、viewを利用して旧構造へのアクセスをなくしていく方法がある。具体的な例として、ユーザのテーブル設計を正規化しながら削除フラグを廃止する場合は、下記のようなステップになる
なお、ユーザのテーブル設計の正規化についてはこちらを参照してほしい。
- deleted_userテーブルとactive_userテーブルを作成する(図1)
- userテーブルにINSERTする際に、active_userテーブルにも書き込む(図1)
- delete_flag=trueに更新する際に、deleted_userテーブルに書き込み、active_userから対象を削除する(図1)
- userテーブルから、delete_flag = falseのデータをactive_userテーブルにコピーする(図2)
- userテーブルから、delete_flag = trueのデータをdeleted_userテーブルにコピーする(図2)
- SELECTの結果をまとめたビューとしてactive_userテーブルとdeleted_userテーブルをUNIONし、既存のuserテーブルと同様のview_userテーブルを作成する(図3)
- userテーブルへの参照をview_userテーブルに切り替える(図3)
- userテーブルの追加・更新処理をなくす(図4)
- userテーブルを利用する処理はなくなるのでDROPする(図4)
図1
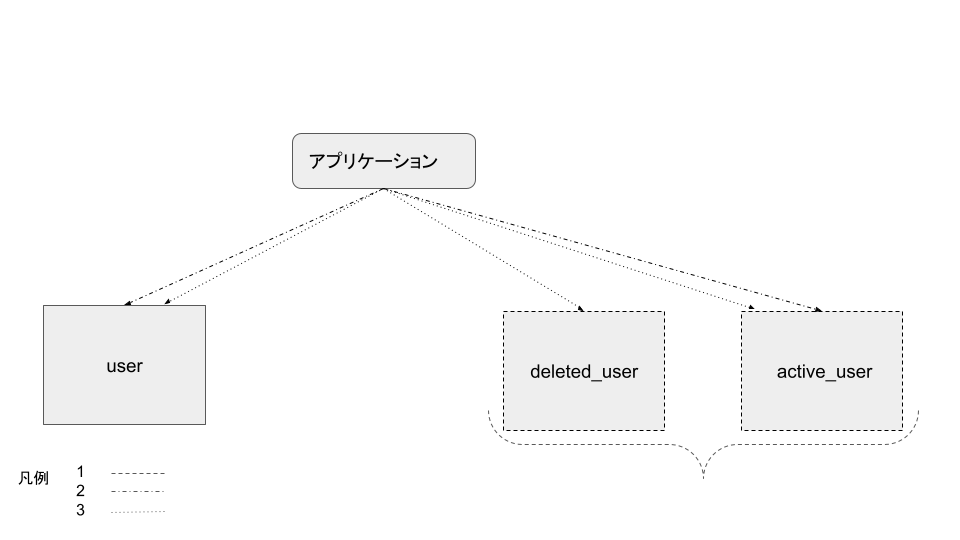
図2

図3

図4

これはあくまで一例であり、子テーブルに分ける場合などもあり、そこはあるべき姿に応じて変わる。
ステップがある程度明確になったら、次のステップに進むための達成条件やロールバックする場合の条件を決める。
データベースリファクタリングは失敗すると大きな影響が出るため、失敗した場合にどのようにロールバックするかを決めておくことも重要だ。
そしてステップを進めるための条件がある程度揃ったら、それを元に大まかなスケジュールを決める。
マルチアプリケーションの場合などは、このスケジュールが各チームのプロジェクトの期限にもなるため、たたき台のスケジュールを作成した後は各チームに根回しを行い、リソースをアサインしてもらう目処を立てよう。
ここを疎かにすると、プロジェクトを開始しても特定のステップで止まってしまい、プロジェクトが悲惨な結果に終わることになる。
方針の決め方については下記の記事を参照されたい。
リファクタリングの方針が決まったら、次は安全にリファクタリングをするための仕組みを準備する。
この準備が不十分だと、リファクタリングの途中で問題が発生したことに気付かず大障害を引き起こしたり、テスト不十分でリファクタリングを進めた結果、データの不整合が発生したりする。
特にデータ不整合などは、リファクタリングの途中で発生しても気付きにくく、後から気付いた場合に修正が困難になることが多い。
特に以下の3つの仕組みは重要である。
- 自動テスト
- オブザーバビリティの強化
- データの整合性チェックの自動化
これらの仕組みの準備はデータベースリファクタリングに限らず、重要だ。
事前に準備することも可能なので、普段からこれらの仕組みを整備しておくことをお勧めする。
逆にこれらの仕組みが整っていない状態でデータベースリファクタリングを行うことはかなりリスクが高いためオススメしない。
自動テスト
データベースに限らず、リファクタリングはサービスの振る舞いを変えないことが前提である。
そのため、リファクタリングの前後でサービスの振る舞いが変わっていないことを確認するためにもE2Eテストや単体テストは必要だ。
しかも、データベースリファクタリングは影響範囲も広く、時間もかかるため予期せぬデグレードが発生する可能性も高い。
そのため、リグレッションテストの意味も含めて、広範囲のテストケースを用意する必要がある。
そうなると毎回QAを手動で行うことはコストが高く、事業メリットが薄れるため、それらのテストを自動化することが重要になる。
とくに単体テストやE2Eテストは自動化し、CI/CDで自動的に実行されることで意図しない振る舞いやバグを早期に発見することができる。
昨今では、AIの発達でテストコードの自動生成も可能になってきているため、これを機にテストケースを充実させることを検討するのもよい。
まだ単体テストがなく、テストケースを揃えることが難しい場合は、主要な機能のE2Eテストを作ることから始めるとよい。
こちらも昨今はplaywright-mcpなど生成AIを活用してテストコードを生成することが可能になってきている。
最初から汎用的なテストコードを作ることは難しいし、E2Eテストは特に陳腐化しやすいのでまずは60点を目指し、動くテストを作ることを目標にしよう。
主要な機能の正常系の主なE2Eテストがあるだけでも、かなりの効果がある。
オブザーバビリティの強化
ここは20年前から遥かに進化しており、モニタリングツールやログ収集ツール、APMツールなどが充実している。
これらのツールを活用して、リファクタリングの影響をモニタリングできるようにしよう。
また、リファクタリングの途中で問題が発生した場合に迅速に対応できるように、アラート設定やダッシュボードの整備も行っておくと良い。
OpenTelemetryなどの分散トレーシングの仕組みは、リファクタリングの対象のテーブルがどのように利用されているかを把握するのに役立つ。
商用のツールを使ってもよいし、オープンソースのツールを組み合わせて使ってもよいが、APMを活用したトレースの部分はアプリケーション側がある程度対応する必要があるので、データベースリファクタリングとは関係なく、APMの導入・活用を普段から進めておくとよい。
逆に、データベースリファクタリングをきっかけにAPMを導入するのもよいチャンスだ。
実際に過去の現場でも同僚がテーブルの状態をメトリックにして監視することで問題に早期に気付ける仕組みを活用した。
データの整合性チェックの自動化
オブザーバビリティとは別に、リファクタリングの途中でデータの整合性が保たれているかをチェックする仕組みも必要である。
例えば削除フラグを廃止する場合は、active_userテーブルとdeleted_userテーブルのデータが重複していないか、既存のuserテーブルとview_userテーブルのデータが一致しているかなどをチェックする仕組みが必要になる。
これらのデータ整合性のチェックはリリース時に実行することも重要だが、10分に一回batchで実行するなど、定期的に実行する仕組みを作っておく。
なぜなら、データの不整合はエッジケースで発生することが多く、リリース時にしかチェックしないと見逃す可能性があるからだ。
その上、放っておくと不整合がどんどん広がっていくこともあるため、定期的にチェックする仕組みを作っておくことで、早期に発見し、対応することができる。
準備が整ったら、いよいよリファクタリングだ。
今回のリファクタリングの方針はそれぞれのテーブルに同様のデータを書き込むことになる。
このように複数のテーブルに同様のデータを書き込むことをダブルライト(double write)と呼ぶ。
ダブルライトは色んな実装のアプローチがあるので、ここでは代表的なアプローチを紹介する。
- データベースを利用した実装
- アプリケーションでの実装
- ミドルウェアを活用した実装
この3つのアプローチについてそれぞれ説明する。
今回の削除フラグの廃止の例ではRDBMSのビューを活用して、既存のuserテーブルと同様のview_userテーブルを作成する。
ビューはSELECT文を定義することで、仮想的なテーブルを作成することができる機能だ。
このようにRDBMSの機能を活用することで、アプリケーション側の変更を最小限に抑えることができる。
そこで、まずはRDBMSの機能を活用したアプローチを紹介する。
トリガーを利用する
名著データベースリファクタリングにも紹介されている方法がトリガーを利用する方法だ。
トリガーはデータベースの機能であり、INSERTやUPDATE、DELETEなどの操作が行われた際に自動的に実行される。
そのため、アプリケーション側の変更が不要であり、リファクタリングの影響範囲を最小限に抑えることができる。
ただし、デメリットも当然あり、トリガーはデータベース側で処理が実行されるため、ネットワークの負荷が発生しない代わりにCPUやメモリの負荷が増加する。
またアプリケーションコードと分離してロジックを管理することになるため、保守性は下がるし、トリガー自体のテストが難しい。
アプリケーションの改修コストが下がる以上に、運用コストが上がるケースの方が多いのでオススメはしないが、マルチアプリケーションの場合などアプリケーション側のダブルライトが実装されるまでのつなぎとして期間を決めて利用するのは有効な方法だ。
実際に私も過去の職場でトリガーを利用してダブルライトを実装したことがある。

詳細は参照元のスライドを見てほしい。
生成列で計算後の列を作る
トリガーと同様にデータベースの機能を利用する方法として生成列を利用する方法もある。
今回はテーブルの分割がテーマなので、あまり適用例はないが、例えば下記のようなケースで利用できる。
- userテーブルにfull_name列を追加し、first_nameとlast_nameを連結した値を自動的に設定する
- orderテーブルにtotal_price列を追加し、order_itemテーブルのpriceの合計値を自動的に設定する
- eventテーブルにstart_dateとend_dateを追加し、duration列を自動的に設定する
| id | first_name | last_name | full_name (生成列) |
|---|---|---|---|
| 1 | John | Doe | John Doe |
| 2 | Jane | Smith | Jane Smith |
| 3 | Alice | Johnson | Alice Johnson |
| id | start_date | end_date | duration (生成列) |
|---|---|---|---|
| 1 | 2023-10-01 | 2023-10-05 | 4 |
| 2 | 2023-11-10 | 2023-11-12 | 2 |
| 3 | 2023-12-20 | 2023-12-25 | 5 |
今回のビューと同様に一時的な参照用の列の追加として使うパターンもあるが、CASE式で処理をしていたような場合に、生成列を利用して処理を簡潔にすることもできる。
ユースケース次第ではあるが、生成列の追加だけで問題が解決するパターンも少なくないのでここで合わせて紹介する。
複数のテーブルを参照するような生成列では難しいような計算パターンの際はストアドファンクションやトリガーを組み合わせることで対応できる場合もある。
ただしこの場合の注意点はトリガーと同様のため、多用は禁物である。
次にアプリケーション側でダブルライトを実装する方法を紹介する。
RDBMSの機能を利用せず、アプリケーション側の対応でダブルライトを実装できる場合は、アプリケーション側で実装することをお勧めする。
先程も述べたが、RDBMSの機能を利用するとテストが難しいなどのデメリットが多く、また変更コストも高い。
その点、アプリケーション側はロールバックも容易であり、テストもしやすいため、運用コストも低い。
このようにアプリケーションはデータベースよりも変化に強いため、データベースリファクタリングのロジックはできるだけアプリケーションで担保するようにしよう。
データベースのリファクタリングの勘所とアプリケーションの優位についてはこちらの記事を参考にされたい。
関数でラップする
データベースリファクタリングのスタンダードな方法としては、データベースにアクセスする関数をラップして、ダブルライトのロジックを実装する方法がある。
例えば以下のようなPHPのコードであれば、SaveUser関数をラップして、userテーブルとactive_userテーブルに同時にINSERTするようにする。
function SaveUser($user) {
$db->beginTransaction();
$db->insert('user', $user);
$db->insert('active_user', $user);
$db->commit();
}
参照側は以下のようにuserテーブルを参照している場合は、view_userテーブルを参照するように変更する。
function GetUser($id) {
return $db->select('view_user', ['id' => $id]);
}
この方法はシンプルでわかりやすく、テストもしやすい。
さらに一手間加えることでより安全に実装することもできる。
function SaveUser($user) {
$db->beginTransaction();
try {
$db->insert('user', $user);
$db->savePoint('after_user_insert');
$db->insert('active_user', $user);
$db->commit();
} catch (Exception $e) {
$db->rollbackToSavePoint('after_user_insert');
$db->commit();
Log::error('Failed to insert active_user', ['error' => $e->getMessage()]);
}
}
これはわかりやすくした例だが、このようにuserテーブルに書き込みが成功した後に、active_userテーブルへの書き込みが失敗してもサービスを継続できるようにするとより安全になる。
同様に参照側も次のように工夫できる。
function GetUser($id) {
$user = $db->select('user', ['id' => $id]);
$viewUser = $db->select('view_user', ['id' => $id]);
if ($user != $viewUser) {
Log::warn('Data inconsistency detected', ['user' => $user, 'view_user' => $viewUser]);
}
return $user;
}
このコードは今まで通り、userテーブルのデータを返すが、view_userテーブルのデータと比較し、不整合があればログに残すようにしている。
これによって安全にデータが参照できているか確認することができ、もし不整合が発生していれば、早期に検知することができる。
このようなアプローチはシャドウページング(shadow paging)と呼ばれ、データベースリファクタリング以外の場面でも活用されている。
この方法はかなり安全なので最もオススメの方法だ。
ただし、UPDATE、DELETEも含め、全ての操作をラップする必要があるため、アプリケーションのコードが肥大化するデメリットもある。
ORMなどのフレームワークを利用している場合は、フレームワークの機能を利用してダブルライトを実装することもできる。
イベントリスナーやミドルウェアと呼ばれるような機能を利用して、RDBMSのトリガーと同様のことをアプリケーション側で実装することもできる。
例えばLaravelの場合はTraitで対象のモデルを上書きすることで任意の処理を実行できる。
これも全体のアプリケーションのコードを変更することなく、一気にダブルライトを実装できる反面、トリガーと同様に暗黙的な振る舞いになり、アプリケーションの単体テストが難しくなるなどのデメリットもある。
そのため、基本的には関数でラップするようなシンプルな方法をオススメするが、シングルアプリケーションで短期決戦でリファクタリングを行う場合などは有効な方法だ。
最後にCDC(Change Data Capture)やメッセージキューを利用した非同期の方法を紹介する。
これらの方法を活用するとリファクタリング前のDBとリファクタリング後のDBを分離できるため、インフラ費は増えるものの、データの安全性を確保したままリファクタリングを進めることができる。
大規模なリファクタリングが最初から必要とわかっている場合や参照と更新を分けてリファクタリングを進めたい場合などに有効な方法だ。
CDCはデータベースの変更を検知して、その変更を別のシステムに伝搬する仕組みだ。
例えばAWS DMSやDebeziumなどのツールを利用して、RDBMSの変更を検知し、別のRDBMSに伝搬することができる。
類似の例で論理レプリケーションを利用する方法もあり、同一データベースであれば、PostgreSQLやMySQLは論理レプリケーションでも同様のことができる。
実際に私も異種データベース間でCDCを利用してデータを移行しながら、リファクタリングを進めたことがある。
詳細については下記の記事が詳しい。
CDCは強力な選択肢だが、コンポーネントが増える分、監視の対象も増えるし、運用コストも増える。
またCDC自体が単一障害点になることも多く、厳しいSLAを求められる場合は注意が必要だ。
またある程度リファクタリングが進むと、データベースの負債の優先度が下がってしまうため、残りのデータベースリファクタリングが進まず、CDCだけが残ってしまうこともある。
そうなるとCDCが新たな技術的負債になってしまうため、CDCを利用する場合は、リファクタリングのスケジュールを厳守し、予定通りにリファクタリングを完遂させたあとは、CDCを必ず廃止しよう。
そのため、小さなリファクタリングを積み重ねていくことができる場合は、CDCは避けた方がよい。
非同期で書き込む
CDCと似た方法として、メッセージキューを利用して、非同期でダブルライトを実装する方法もある。
例えば以下のようなPHPのコードであれば、SaveUser関数をラップして、userテーブルにINSERTした後に、メッセージキューに書き、別のワーカーでactive_userテーブルにINSERTするようにする。
SaveUser($user);
function SaveUser($user) {
$db->beginTransaction();
$db->insert('user', $user);
$db->commit();
$mq->publish('insert_active_user', $user);
}
参照側は関数ラッパーと同様である。
このようなアプローチはログ先行書き込み(log-structured write)と同様の考え方であり、データベースの書き込みを高速化することができる。
ワーカー側はキューにメッセージの重複登録に注意する必要があるが、CDCと違い、単一障害点になりにくく、データの前加工なども柔軟に実装できる。
CQRS(Command Query Responsibility Segregation)のパターンを採用している場合などは、こちらの方法が適している場合も多く、参照整合性が緩い場合などは有効な方法だ。
ただし、非同期であるため、データの整合性のチェックは必須であり、書き込みが遅延したり失敗した場合の対応も検討しておく必要がある。
このようにデータベースリファクタリングは戦略的に準備すれば、安全に実施することができる。
今回紹介した方法を組み合わせて、継続的にデータベースリファクタリングを進めることで効果的にデータベースの負債を解消することができる。
昨今はクラウドネイティブなアーキテクチャやAIの発達で、データベースの肥大化が加速しているからこそ、継続的なデータベースリファクタリングが事業成長の鍵になる。
そして最後に一番重要なこととして、データベースリファクタリングは影響範囲も広く、時間がかかる。
だからこそ一番必要なのはやり切るぞ!という覚悟である。
ぜひ、今回紹介した方法を参考に、データベースリファクタリングを進めてほしい。
AI時代のデータベースのスキル
DBリファクタリング
ユーザのテーブル設計
リファクタリング戦略
DBの寿命はアプリより長い! 長生きするDBに必要な設計とリファクタリングを実践から学ぶ|ハイクラス転職・求人情報サイト アンビ(AMBI)
{kind=link}