


中国の大手テクノロジー企業であるHuaweiが、大規模言語モデル(LLM)をコンシューマーグレードのハードウェアで品質を損なうことなく実行できるようにするための量子化手法「Sinkhorn-Normalized Quantization(SINQ)」を発表しました。
[2509.22944] SINQ: Sinkhorn-Normalized Quantization for Calibration-Free Low-Precision LLM Weights
https://www.arxiv.org/abs/2509.22944
Huawei’s SINQ: The Open-Source Shortcut to Shrinking LLMs Without Sacrificing Power – AI Consultant | Machine Learning Solutions | Expert Developers
https://aisengtech.com/2025/10/04/Huawei-s-SINQ-The-Open-Source-Shortcut-to-Shrinking-LLMs-Without-Sacrificing-Power/
Huawei’s new open source technique shrinks LLMs to make them run on less powerful, less expensive hardware | VentureBeat
https://venturebeat.com/ai/huaweis-new-open-source-technique-shrinks-llms-to-make-them-run-on-less
Huaweiは年間220億ドル(約3兆3000億円)を超える研究開発投資を行っています。そんなHuaweiのイノベーションを主導する研究施設のひとつが、スイス・チューリッヒにある研究開発センターのHuawei Research Center Zurich(ZRC)です。そのZRCが、LLMの出力品質を損なうことなくメモリフットプリントを削減するよう設計されたオープンソースの量子化手法の「SINQ」を発表しました。SINQの最大の利点は高速でキャリブレーション不要でありながら、既存のモデルワークフローへの統合が容易であるという点にあります。
従来の量子化手法は、メモリを節約するためにAIモデルの重みづけの精度を下げますが、メモリ使用量とパフォーマンスのトレードオフが生じるという問題を抱えていました。しかし、SINQは以下の2つの重要な革新を導入することで、パフォーマンスの低下を抑えることに成功しています。
・二軸スケーリング
SINQは行列を量子化する際に、単一のスケール係数を使用する代わりに、行と列に別々のスケーリングベクトルを使用します。このアプローチにより、外れ値の影響を軽減し、量子化による誤差を行列全体にわたってより柔軟に分散させることが可能です。
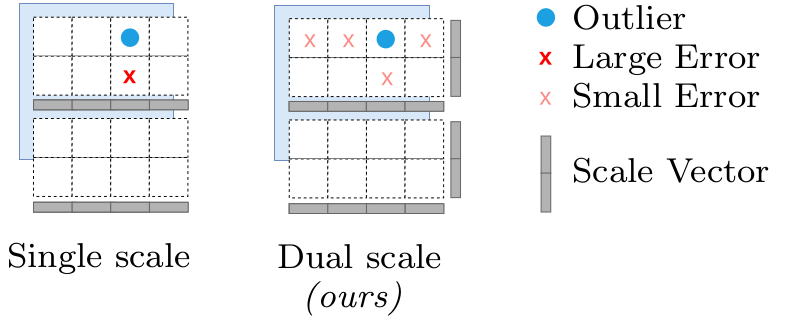
・シンクホーン・クノップ型正規化
シンクホーン・クノップ型正規化は、シンクホーン反復と呼ばれるアルゴリズムに着想を得た高速アルゴリズムです。行列の行と列の標準偏差を正規化することで、「行列の不均衡」を最小化するというもの。尖度などの代替指標よりも、効果的に量子化性能を向上させることができると示されています。

これによりSINQはキャリブレーション不要な量子化手法と比べて、複数のベンチマークにおいて優れたパフォーマンスを発揮しました。具体的には、確率モデルがサンプルをどれだけ正確に予測できるかを示す指標であるパープレキシティや、モデルの堅牢性の指標であるフリップ率が一貫して改善されたそうです。
SINQを用いることでアーキテクチャとビット幅に応じてさまざまなサイズのAIモデルがメモリ使用料を60~70%も削減することに成功しています。つまり、これまで60GB以上のメモリを必要としていたAIモデルが、20GB程度で動作可能となるわけです。なお、SINQはQwen3シリーズやLlama、DeepSeekのLLMなど、幅広いAIモデルで利用することに成功しています。
これはハイエンドのエンタープライズ向けGPUを必要としていたAIモデルが、より安価な一般消費者向けのGPUで動作できるようになることを意味するとAIコンサルタントのシェン・ガオ氏は言及しています。なお、これはNVIDIAのAI向けGPUであるA100 80G(1万9000ドル:約290万円)やH100(3万ドル:約450万円)でなければ動作しなかったAIモデルを、GeForce RTX 4090で動作させるようなものです。
また、A100ベースのインスタンスは1時間あたり3~4.5ドル(約450~680円)かかることが多いのに対して、GeForce RTX 4090のような24GB GPUならば1時間あたり1~1.5ドル(約150~230円)程度で利用可能です。特に、拡張推論ワークロードの場合、この差は時間の経過とともに数千ドル(数十万円)のコスト削減につながる可能性があります。
そのため、メモリの制約を受けていた小規模クラスターやローカルワークステーション、コンシューマーグレードのセットアップ上でもLLMを動作させることが可能となります。
なお、SINQはGitHubやHugging FaceといったプラットフォームでApache 2.0ライセンスの下で利用可能。無料で使用・改変・商用展開が可能です。
Paper page – SINQ: Sinkhorn-Normalized Quantization for Calibration-Free Low-Precision LLM Weights
https://huggingface.co/papers/2509.22944
GitHub – huawei-csl/SINQ: Welcome to the official repository of SINQ! A novel, fast and high-quality quantization method designed to make any Large Language Model smaller while preserving accuracy.
https://github.com/huawei-csl/SINQ
この記事のタイトルとURLをコピーする
元の記事を確認する
{kind=link}