


記事 [1, 2, 3] では、マルチインデックスをもつエクセルファイルの表を体系的に取り扱う考え方とそのツール群を紹介しました。
本記事では結合セルのインデックスが根付き木の構造 (以下、 ツリーインデックス と省略) をもつエクセルファイルに対して、同様なツール群を紹介します。
- マルチインデックスはインデックスがハイパーキューブで解釈した場合にはある程度規則性があります。
- 業務上、ハイパーキューブよりも複雑な構造を持つ結合セルのインデックスを含むエクセルファイルを取り扱うことがあります。
- 例えば『LANSCOPE エンドポイントマネージャー オンプレミス版』の「デバイス制限設定」は階層構造になっていて、これをエクセルファイルのインデックスで表現しようとすると、Windows と Mac で異なる階層構造を取り扱います。 (図 1 を参照。)
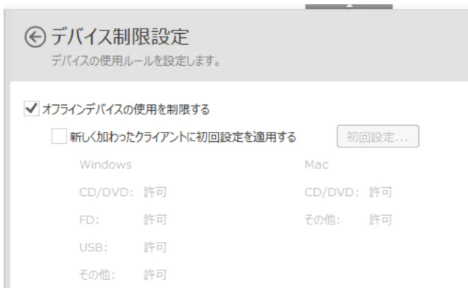
図 1. 『LANSCOPE エンドポイントマネージャー オンプレミス版』の「デバイス制限設定」。
課題1. 一般的にセル結合のインデックスを表現するための適切な構造が存在しないこと。
業務で頻繁に使用される一般的な結合セルのインデックスを表現するためには、ハイパーキューブ以外の「規則性のない」構造が必要です。しかし、表のインデックスに対してこの構造を体系的に取り扱う方法は、私の知る限り存在していません。
課題2. 上記の構造を取り扱うツール群が存在しないこと。
ツリーインデックスを取り扱うツール群に対してもマルチインデックスを取り扱うツール群の対応物が存在しないです。
解決1. 根付き木を使用。
図 2 のような、行はグループとユーザに関する階層構造、列は上述した「デバイス制限設定」を表現する表があります。

図 2. 『LANSCOPE エンドポイントマネージャー オンプレミス版』の「デバイス制限設定」の表。
ここで、ルートをもったツリーを根付き木とよびます。行インデックスと列インデックスをともに、根付き木で表現します。上記の表を根付き木で表現すると 図 3 になります。
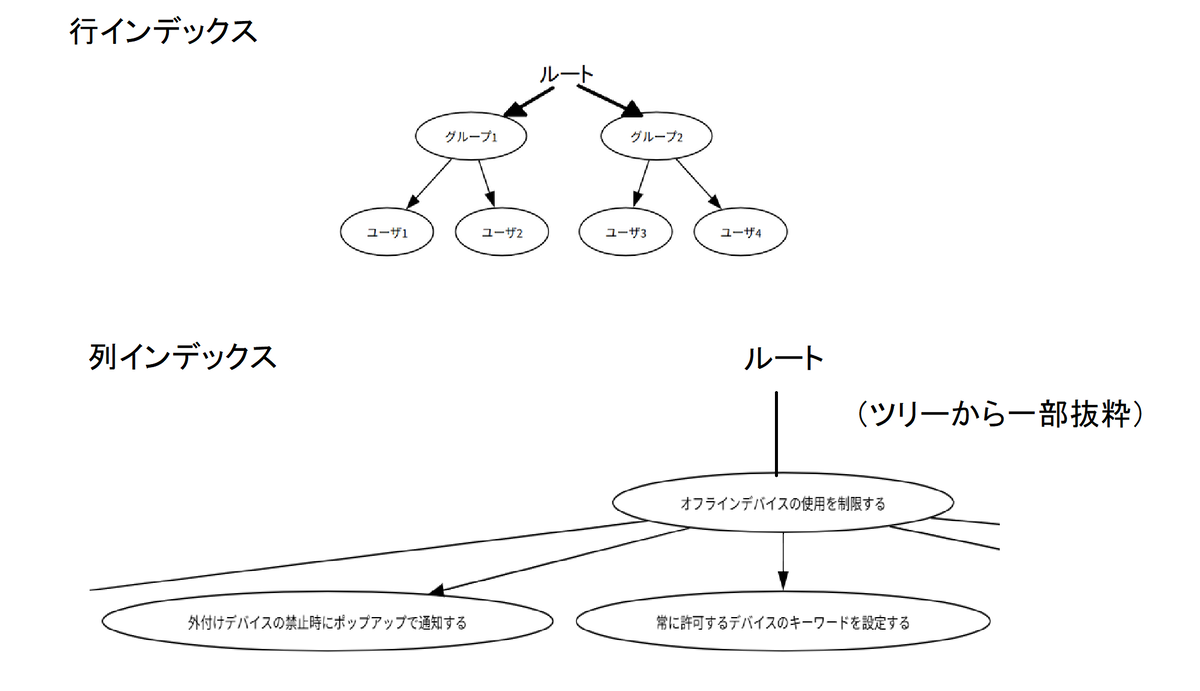
図 3. 根付き木。
根付き木をノード間の隣接関係を表すリスト (以下、隣接リスト と省略) で表現します。ルート自体はエクセルファイルのセルとしては表示しません。
■ 行インデックス
r: [グループ1, グループ2] グループ1: [ユーザ1,ユーザ2] グループ2: [ユーザ3,ユーザ4]
■ 列インデックス
r: [オフラインデバイスの使用を制限する] オフラインデバイスの使用を制限する: [新しく加わったクライアントに初回設定を適用する, 外付けデバイスの禁止時にポップアップで通知する, 常に許可するデバイスのキーワードを設定する, 許可または読取専用にする USB のベンダーID/プロダクトID を設定する, 許可または読取専用にする管理デバイスを設定する] 新しく加わったクライアントに初回設定を適用する: [Windows, Mac] Windows: [CD/DVD_win, FD, USB, その他_win] Mac: [CD/DVD_mac, その他_mac]
解決2. ツール群を作成。
マルチインデックスをもつエクセルファイルの表を体系的に取り扱う考え方とそのツール群に対するツリーインデックスの対応物を作成しました。
行インデックス: 5 階層の 2 分木のグループと、最小のグループに 10 ユーザの根付き木を考えると、リーフのインデックスは 25 * 10 = 320 行。
列インデックス: 「デバイス制限設定」のリーフのインデックス数は 10 列
合計 10 * 320 = 3200 個のセルをもつエクセルファイル (図4 を参照) は、結合セルの階層構造が複雑であればあるほど、作成は 1 週間以上、差分の抽出、根付き木の兄弟ノードの交換、及びインデックスをツリーとシングルで相互変換はそれぞれ 2 週関以上かかると見込まれます。
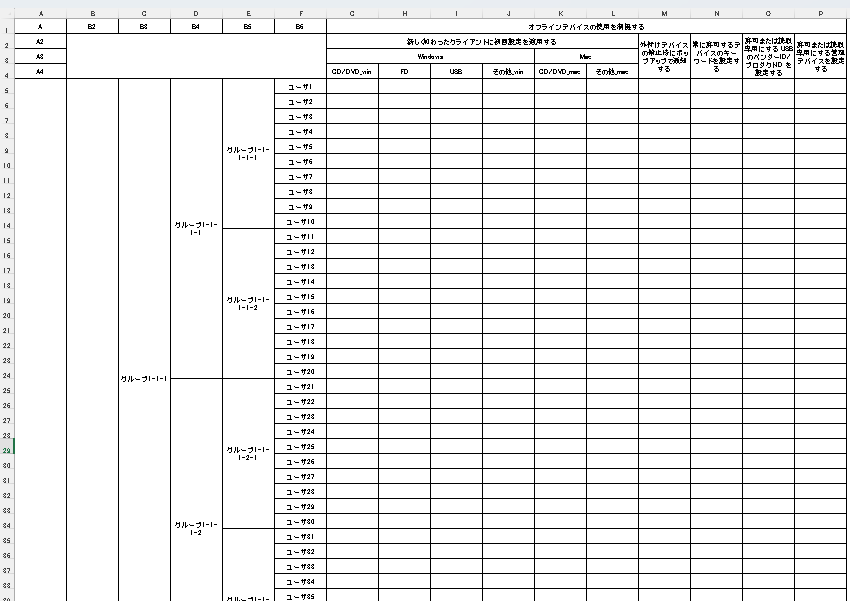
図 4. 合計 10 * 320 = 3200 個のセルをもつエクセルファイル。
これを次に記載の 4 ツールで解決します。エムオーテックス社内 AI ツールと相談して作成しました。
-
ツール 1: ツリーインデックスをもつエクセルファイルを作成するツール
-
ツール 2: ツリーインデックスをもつエクセルファイルの差分をセル単位で抽出するツール
-
ツール 3: ツリーインデックスをもつエクセルファイルにおいて根付き木の兄弟ノード交換で整合性を保つツール(備考: 兄弟
ノードというのは親ノードを共有する複数のノードのことです。上記の例だと「グループ1」と「グループ2」のことです。) -
ツール 4: エクセルファイルのインデックスをツリーとシングルで相互変換するツール
フォルダの構成
├─ __init__.py ├─ common/ │ ├─ __init__.py │ ├─ tree_utils.py # ツリー構造関連の共通関数 │ └─ excel_utils.py # Excel 操作の共通処理 ├─ tree_index.py ├─ excel_validation.py ├─ tree_index_rotation.py └─ tree_index_single_index_conversion.py
ツール 1: ツリーインデックスをもつエクセルファイルを作成するツール
処理の概要
Step 1. ユーザ: UI のテキストエリアに、行と列それぞれのツリーを表す隣接リスト形式の文字列を入力。 Step 2. 入力された文字列から、行と列それぞれのツリー構造が構築され、全体の深さやリーフ数を計算。 Step 3. ツリー構造の情報を元に、Excelシート内のインデックス領域(左上の交差部、行ヘッダー、列ヘッダー)のサイズおよび配置が決定。 Step 4. 罫線やセル書式を設定するフォーマットを用いて、Excelファイル用のシートを作成。 Step 5. 左上交差部には既定の名称(例:"A1/B1" や "B2" など)を出力し、各列の見出しと各行の見出しをそれぞれ書き込み。 Step 6. ツリー構造に基づいて算出された結合セルが、列や行のヘッダー部分に反映される。 Step 7. ヘッダ以外のデータの領域は、必要なセルに対して空文字などを出力して表形式となるように描画。 Step 8. 元の行・列のツリー情報テキストはそれぞれ、専用のシート("row_index" と "col_index")に書き込み。 Step 9. ユーザ: エクセルファイルをダウンロード。
tree_index.py
import streamlit as st import io import xlsxwriter from common.tree_utils import ( TreeNode, parse_adj_list, build_directed_tree, assign_positions, collect_col_header_ranges, collect_row_header_ranges, tree_to_dot_format ) st.title("ツリーインデックスをもつエクセルファイルの作成ツール") st.markdown(""" 【使い方】 ・【隣接リスト形式】で有向木(親 → 子)の構造を入力してください。 【行インデックスの例】(左側に表示) r: [グループ1, グループ2] グループ1: [ユーザ1,ユーザ2] グループ2: [ユーザ3,ユーザ4] 【列インデックスの例】(上側に表示) r: [オフラインデバイスの使用を制限する] オフラインデバイスの使用を制限する: [新しく加わったクライアントに初回設定を適用する, 外付けデバイスの禁止時にポップアップで通知する, 常に許可するデバイスのキーワードを設定する, 許可または読取専用にする USB のベンダーID/プロダクトID を設定する, 許可または読取専用にする管理デバイスを設定する] 新しく加わったクライアントに初回設定を適用する: [Windows, Mac] Windows: [CD/DVD_win, FD, USB, その他_win] Mac: [CD/DVD_mac, その他_mac] ※出力されるExcelの左上交差部には「A1,B1 などのインデックス名称」が付与されます。 """) default_row_tree = ("r: [グループ1, グループ2]\n" "グループ1: [ユーザ1,ユーザ2]\n" "グループ2: [ユーザ3,ユーザ4]") row_tree_input = st.text_area("行インデックス(左側に表示)", value=default_row_tree, height=150) default_col_tree = ("r: [オフラインデバイスの使用を制限する]\n" "オフラインデバイスの使用を制限する: [新しく加わったクライアントに初回設定を適用する, 外付けデバイスの禁止時にポップアップで通知する, 常に許可するデバイスのキーワードを設定する, 許可または読取専用にする USB のベンダーID/プロダクトID を設定する, 許可または読取専用にする管理デバイスを設定する]\n" "新しく加わったクライアントに初回設定を適用する: [Windows, Mac]\n" "Windows: [CD/DVD_win, FD, USB, その他_win]\n" "Mac: [CD/DVD_mac, その他_mac]") col_tree_input = st.text_area("列インデックス(上側に表示)", value=default_col_tree, height=150) if st.button("Excel 作成"): try: row_adj = parse_adj_list(row_tree_input) if "r" in row_adj: row_tree_raw = build_directed_tree(row_adj, "r") dummy_row = TreeNode("") dummy_row.children = row_tree_raw.children counter_row = [0] max_level_row_holder = [-1] assign_positions(dummy_row, -1, counter_row, max_level_row_holder) row_max_depth = max_level_row_holder[0] + 1 n_row_leaves = counter_row[0] row_tree_display = dummy_row row_global = True else: row_root_key = row_tree_input.splitlines()[0].split(":", 1)[0].strip() row_tree_raw = build_directed_tree(row_adj, row_root_key) counter_row = [0] max_level_row_holder = [0] assign_positions(row_tree_raw, 0, counter_row, max_level_row_holder) row_max_depth = max_level_row_holder[0] + 1 n_row_leaves = counter_row[0] row_tree_display = row_tree_raw row_global = False col_adj = parse_adj_list(col_tree_input) if "r" in col_adj: col_tree_raw = build_directed_tree(col_adj, "r") dummy_col = TreeNode("") dummy_col.children = col_tree_raw.children counter_col = [0] max_level_col_holder = [-1] assign_positions(dummy_col, -1, counter_col, max_level_col_holder) col_max_depth = max_level_col_holder[0] + 1 n_col_leaves = counter_col[0] col_tree_display = dummy_col col_global = True else: st.error("列インデックスはグローバルルート 'r' を含む形式で入力してください。") st.stop() row_header_width = row_max_depth col_header_height = col_max_depth data_rows = n_row_leaves data_cols = n_col_leaves total_rows = col_header_height + data_rows total_cols = row_header_width + data_cols output = io.BytesIO() workbook = xlsxwriter.Workbook(output, {'in_memory': True}) worksheet = workbook.add_worksheet("TreeStructure") header_format = workbook.add_format({ 'align': 'center', 'valign': 'vcenter', 'border': 1, 'text_wrap': True }) for c in range(total_cols): worksheet.set_column(c, c, 15) for r in range(total_rows): worksheet.set_row(r, 25) if row_header_width > 0 and col_header_height > 0: for c in range(row_header_width): worksheet.write(0, c, "A1/B1" if c == 0 else f"B{c+1}", header_format) for r in range(1, col_header_height): worksheet.write(r, 0, f"A{r+1}", header_format) col_ranges = ( [r for child in col_tree_display.children for r in collect_col_header_ranges(child, col_max_depth)] if col_global else collect_col_header_ranges(col_tree_display, col_max_depth) ) for top, left, bottom, right, label in col_ranges: abs_top = top abs_bottom = bottom abs_left = left + row_header_width abs_right = right + row_header_width if abs_top == abs_bottom and abs_left == abs_right: worksheet.write(abs_top, abs_left, label, header_format) else: worksheet.merge_range(abs_top, abs_left, abs_bottom, abs_right, label, header_format) row_ranges = ( [r for child in row_tree_display.children for r in collect_row_header_ranges(child, row_header_width)] if row_global else collect_row_header_ranges(row_tree_display, row_header_width) ) for top, left, bottom, right, label in row_ranges: abs_top = top + col_header_height abs_bottom = bottom + col_header_height abs_left = left abs_right = right if abs_top == abs_bottom and abs_left == abs_right: worksheet.write(abs_top, abs_left, label, header_format) else: worksheet.merge_range(abs_top, abs_left, abs_bottom, abs_right, label, header_format) for r in range(col_header_height, total_rows): for c in range(row_header_width, total_cols): worksheet.write(r, c, "", header_format) sheet_row = workbook.add_worksheet("row_index") sheet_col = workbook.add_worksheet("col_index") sheet_row.write(0, 0, row_tree_input, header_format) sheet_col.write(0, 0, col_tree_input, header_format) workbook.close() output.seek(0) st.success("Excelファイルが生成されました。") st.download_button( label="Excel ファイルをダウンロード", data=output, file_name="tree_structure.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" ) row_dot = tree_to_dot_format(row_tree_display, hide_dummy=True) col_dot = tree_to_dot_format(col_tree_display, hide_dummy=True) st.subheader("行インデックスツリー (Graphviz)") st.graphviz_chart(row_dot) st.subheader("列インデックスツリー (Graphviz)") st.graphviz_chart(col_dot) except Exception as e: st.error(f"エラーが発生しました: {e}")
ツール 2: ツリーインデックスをもつエクセルファイルの差分をセル単位で抽出するツール

図 5. 差分の Slack への通知。
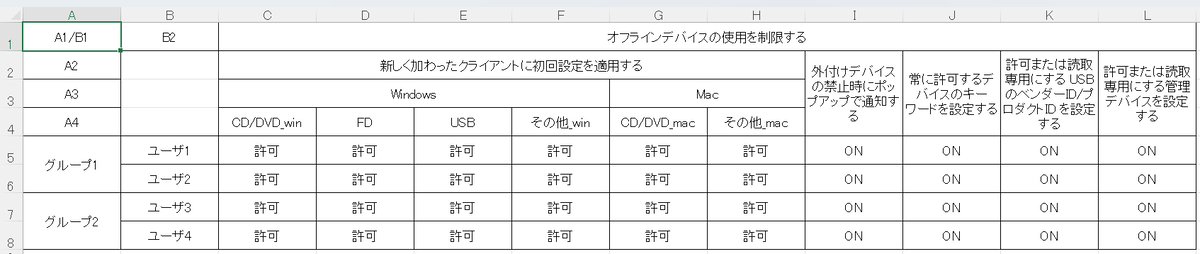
図 6. 変更前の表。
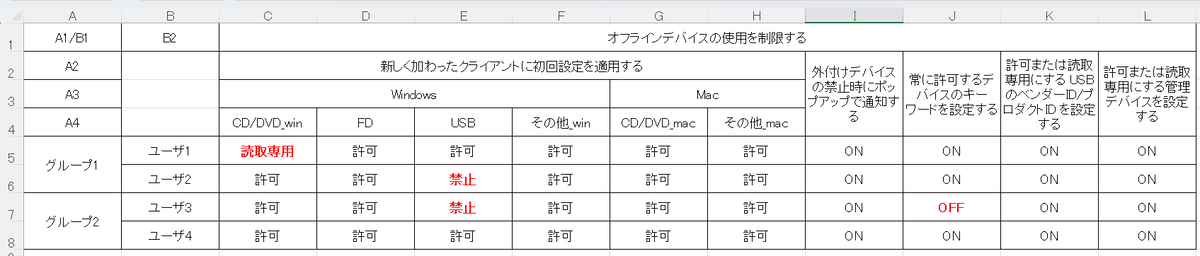
図 7. 変更後の表(赤い文字が差分)。
使い方
pytest excel_validation.py
処理の概要
Step 1. Excelファイルからデータフレームを構築。 Step 2. 読み込んだ2つのExcelファイルのシート内容(行数・列数)が一致するかを確認し、各セルについて、インデックスの不要な部分を除去した上で値が一致しているかを個別に検証。 Step 3. 各セルの比較結果に基づいて、期待される値と実際の値が一致しているかどうかのテストを実施し、不一致があれば詳細なエラーメッセージを出力してテストを失敗とする。 Step 4. Slack に通知。
excel_validation.py
import pandas as pd import pytest import requests import re def auto_detect_levels(uploaded_file, max_levels=5, row_prefix=None, col_prefix=None): """ アップロードされた Excel ファイルのシート "TreeStructure" から左上ブロックを読み込み、 行・列のインデックスレベルを検出して DataFrame を返す。 戻り値: (index_levels, header_levels, df) """ uploaded_file.seek(0) df_raw = pd.read_excel(uploaded_file, sheet_name="TreeStructure", header=None, engine="openpyxl", dtype=str) n_rows, n_cols = df_raw.shape col_pattern = re.compile(r"^(B\d+|A1/B1)$") index_levels = 0 for c in range(n_cols): cell_value = df_raw.iloc[0, c] if isinstance(cell_value, str) and col_pattern.match(cell_value.strip()): index_levels += 1 else: break row_pattern = re.compile(r"^(A\d+|A1/B1)$") header_levels = 0 for r in range(n_rows): cell_value = df_raw.iloc[r, 0] if isinstance(cell_value, str) and row_pattern.match(cell_value.strip()): header_levels += 1 else: break if index_levels == 0 or header_levels == 0: raise ValueError("Excelファイルの左上交差部からインデックスレベルを検出できませんでした。") uploaded_file.seek(0) try: df = pd.read_excel( uploaded_file, sheet_name="TreeStructure", header=list(range(header_levels)), index_col=list(range(index_levels)), engine="openpyxl" ) except Exception as e: raise ValueError(f"Excelファイルの読み込みに失敗しました: {e}") idx_names = df.index.names col_names = df.columns.names if row_prefix is not None: if not all(isinstance(name, str) and name.startswith(row_prefix) for name in idx_names if name): raise ValueError("行インデックスの名称に期待する接頭辞が見つかりませんでした。") if col_prefix is not None: if not all(isinstance(name, str) and name.startswith(col_prefix) for name in col_names if name): raise ValueError("列インデックスの名称に期待する接頭辞が見つかりませんでした。") return index_levels, header_levels, df def format_index(idx): """ MultiIndex(または単層インデックス)の各要素を文字列に変換します。 タプルの場合、各要素のうち "Unnamed:" で始まるものは除外し、 残りの要素で (A2,A5) 形式の文字列を生成します。 """ if isinstance(idx, tuple): filtered = [str(item).strip() for item in idx if not (isinstance(item, str) and item.startswith("Unnamed:"))] return "(" + ",".join(filtered) + ")" else: return f"({idx})" def read_excel(filename, row_prefix=None, col_prefix=None): """ Excel ファイルを読み込み、ツリー構造に基づく MultiIndex 付き DataFrame として返します。 シート "row_index" および "col_index" に記載されたツリー情報からマルチインデックスレベル数を 自動検出し、シート "TreeStructure" のデータ領域に対して MultiIndex を構築します。 """ with open(filename, 'rb') as f: _, _, df = auto_detect_levels(f, row_prefix=row_prefix, col_prefix=col_prefix) return df EXCEL1_FILENAME = 'excel1.xlsx' EXCEL2_FILENAME = 'excel2.xlsx' df1 = read_excel(EXCEL1_FILENAME) df2 = read_excel(EXCEL2_FILENAME) assert df1.shape == df2.shape, ( f"Excel ファイルの形状が一致していません。 ファイル1: {df1.shape}, ファイル2: {df2.shape}" ) @pytest.mark.parametrize("row, col", [ (row, col) for row in df1.index for col in df1.columns ]) def test_excel_cell(row, col): """ Excel ファイル1 と Excel ファイル2 の各セルの値が一致するかを検証するテストです。 インデックス(MultiIndex)の要素は format_index を用いて文字列に変換し出力します。 """ cell1 = df1.loc[row, col] cell2 = df2.loc[row, col] row_str = format_index(row) col_str = format_index(col) assert cell1 == cell2, ( f"セルの不一致発生: 行 {row_str} 列 {col_str} で、" f"Excel ファイル1 の値は '{cell1}'、Excel ファイル2 の値は '{cell2}' です。" ) if __name__ == "__main__": pytest.main()
conftest.py
import requests def slack_notify(text): """ 指定したテキストを Slack の Webhook 経由で通知する関数です。 ※ Webhook URL は実際の環境に合わせて適宜変更してください。 """ url = "https://hooks.slack.com/services/xxx" payload = {"text": text} headers = {"Content-type": "application/json"} try: response = requests.post(url, json=payload, headers=headers) if response.status_code != 200: print("Slack 通知に失敗しました。ステータスコード:", response.status_code) print("Response:", response.text) except Exception as e: print("Slack 通知中に例外発生:", e) def _extract_error_line(report): """ テストレポートから、"E" で始まるエラーメッセージの行を抽出します。 該当行がない場合は、最初のエラー行を返します。 """ detailed_error = getattr(report, "longreprtext", str(report.longrepr)).splitlines() error_line = next((line for line in detailed_error if line.startswith("E")), detailed_error[0]) return error_line.replace("E AssertionError: ", "") def pytest_terminal_summary(terminalreporter, exitstatus, config): """ テスト結果の概要をまとめ、不一致のセルに関するエラー内容を Slack へ通知します。 ・総テスト数、合格件数、不一致件数を集計 ・エラーがあれば、各エラーレポートから "E" で始まる行を抽出し一覧化 ・生成された結果メッセージを slack_notify() 経由で送信します。 """ stats = terminalreporter.stats passed = len(stats.get('passed', [])) failed = len(stats.get('failed', [])) total = passed + failed result_lines = [ "セルの差分の抽出結果:", f"総数: {total}", f" 一致: {passed} 件", f" 不一致: {failed} 件", "" ] if failed: result_lines.append("【不一致だったセルの詳細】") for status in ('failed', 'error'): for report in stats.get(status, []): result_lines.append(_extract_error_line(report)) message_text = "\n".join(result_lines) slack_notify(message_text)
ツール 3: ツリーインデックスをもつエクセルファイルにおいて根付き木の兄弟ノードの交換で整合性を保つツール
ユーザ1とユーザ2,Windows と Mac でそれぞれ順番を交換し、「インデックス内容確認」を押下すると順番が交換します (図 8, 9, 10を参照)。
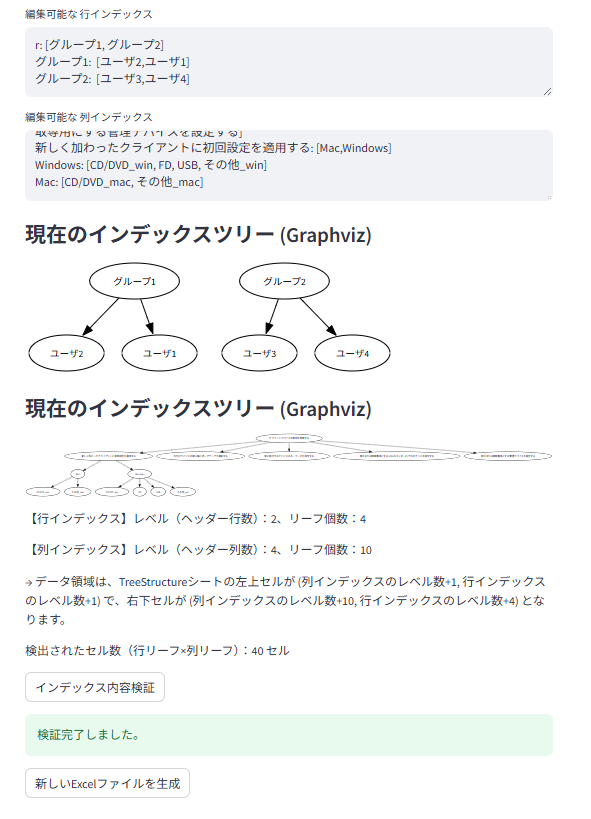
図 8. インデックスを交換。(本画像はツールの画面キャプチャのため、ご利用はできかねます。)
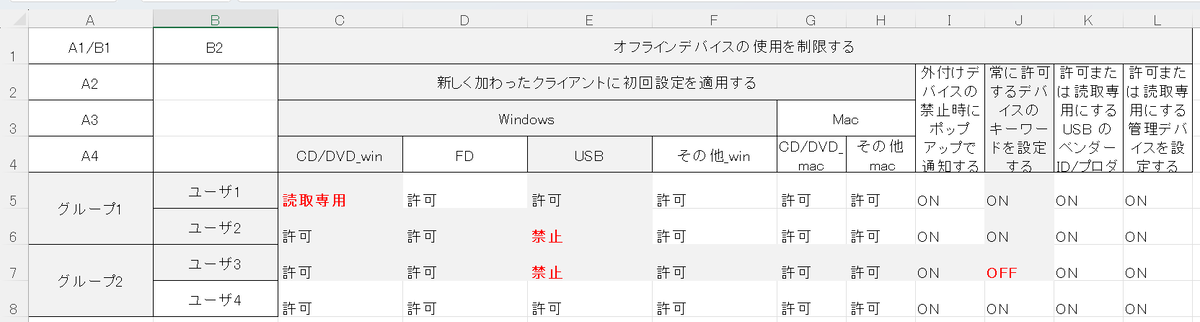
図 9. インデックスの交換前。
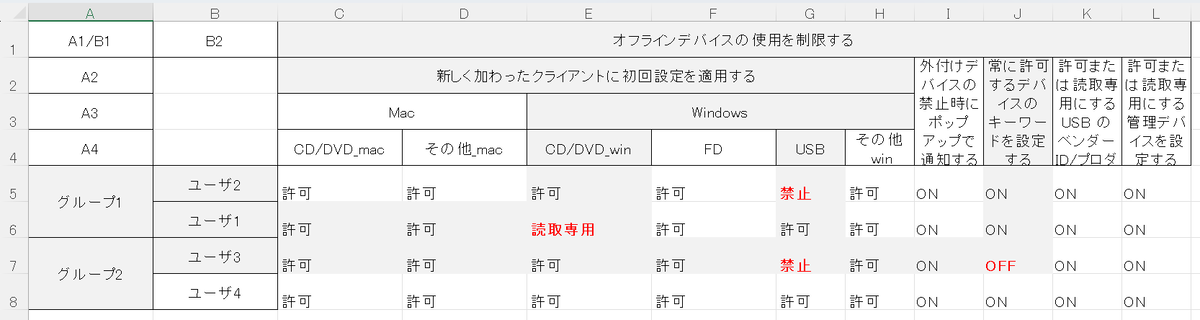
図 10. インデックスの交換後。
処理の概要
Step 1. ユーザ: UI からエクセルファイルを読み込み。 Step 2. エクセルファイルの「row_index」および「col_index」シートから、ツリー構造を示す隣接リスト形式のテキストを読み込み、そのテキストを初期値として編集可能なテキストエリアに表示。 Step 3. ユーザ: ツリー構造の修正。 Step 4. ユーザ: 構築されたツリー構造を画面に表示され、ユーザーは視覚的にインデックスの内容を確認可能。 Step 5. 入力されたツリー情報が期待されるリーフのラベルと合致しているか検証が行われ、不一致があれば元のツリー情報にリセットする等の処理を実施。 Step 6. 元のデータ部分から各行・各列のラベルを抽出し、ツリー構造のリーフの順序と照合して、新しい表のセル配置を決定。 Step 7. 決定された新しいインデックス情報に基づいて、セルの値やマージすべき範囲などの情報を反映させた新しい Excel ファイルを、行ヘッダー・列ヘッダー・データ領域すべてに統一された格子状の罫線を適用して再生成します。 Step 8. ユーザ: エクセルファイルをダウンロード
tree_index_rotation.py
import streamlit as st import pandas as pd import io import xlsxwriter import math import re from collections import Counter, defaultdict, deque from common.tree_utils import ( TreeNode, parse_adj_list, build_directed_tree, assign_positions, collect_col_header_ranges, collect_row_header_ranges, tree_to_dot_format, get_leaf_paths ) from common.excel_utils import safe_cell_value def get_expected_leaves(text): """ 隣接リスト形式テキストから、ツリー構造の各葉のラベルのリストを抽出する関数 """ adj = parse_adj_list(text) if "r" in adj: tree_r = build_directed_tree(adj, "r") dummy = TreeNode("") dummy.children = tree_r.children counter = [0] max_level_holder = [-1] assign_positions(dummy, -1, counter, max_level_holder) paths = get_leaf_paths(dummy) leaves = [path[-1] for path in paths] else: first_line = next((line for line in text.splitlines() if line.strip()), None) if first_line is None: leaves = [] else: root_key = first_line.split(":", 1)[0].strip() tree = build_directed_tree(adj, root_key) counter = [0] max_level_holder = [0] assign_positions(tree, 0, counter, max_level_holder) paths = get_leaf_paths(tree) leaves = [path[-1] for path in paths] return leaves def get_bottom_label(index_val): """ MultiIndex の各要素(タプルまたは単一値)から、下位(葉)のラベルを抽出する関数 """ if isinstance(index_val, tuple): for val in reversed(index_val): if pd.notna(val) and str(val).strip() != "": return str(val).strip() return "" else: return str(index_val).strip() st.title("ツリー構造エクセルの軸交換でセル整合性維持ツール") st.markdown(""" 【前提】 本ツールは、ツリー構造Excel生成ツールで作成されたファイル(シート "TreeStructure")を対象とします。 作成時に行/列インデックスのツリー情報はシート "row_index" と "col_index" に保存されています。 これらのシートからインデックス用テキストを読み込み、編集可能なテキストエリアに反映します。 その後、TreeStructure シート内のデータ領域( 左上セル = (列インデックスのレベル数+1, 行インデックスのレベル数+1) 右下セル = (列インデックスのレベル数+n_col_leaves, 行インデックスのレベル数+n_row_leaves) )から正確に値を読み出します。 """) uploaded_file = st.file_uploader("エクセルファイルをアップロードしてください", type=["xlsx"]) if uploaded_file is not None: try: df_loaded = pd.read_excel(uploaded_file, sheet_name="TreeStructure", header=None, engine="openpyxl") n_rows, n_cols = df_loaded.shape col_pattern = re.compile(r"^(B\d+|A1/B1)$") index_levels = 0 for c in range(n_cols): cell_value = df_loaded.iloc[0, c] if isinstance(cell_value, str) and col_pattern.match(cell_value.strip()): index_levels += 1 else: break row_pattern = re.compile(r"^(A\d+|A1/B1)$") header_levels = 0 for r in range(n_rows): cell_value = df_loaded.iloc[r, 0] if isinstance(cell_value, str) and row_pattern.match(cell_value.strip()): header_levels += 1 else: break except Exception as e: st.error(f"自動検出に失敗しました: {e}") st.stop() try: row_index_df = pd.read_excel(uploaded_file, sheet_name="row_index", header=None, engine="openpyxl", dtype=str) col_index_df = pd.read_excel(uploaded_file, sheet_name="col_index", header=None, engine="openpyxl", dtype=str) if row_index_df.empty or col_index_df.empty: st.error("シート row_index または col_index の内容が空です。") st.stop() row_tree_text_default = row_index_df.iloc[0, 0] col_tree_text_default = col_index_df.iloc[0, 0] except Exception as e: st.error(f"row_index または col_index シートの読み込みに失敗しました: {e}") st.stop() st.write(f"検出された index_levels (TreeStructure 上部セル数): {index_levels}") st.write(f"検出された header_levels (TreeStructure 左部セル数): {header_levels}") st.markdown("### インデックス編集(根付き木情報の記載)") st.markdown(""" 各項目は「ノード: [子ノード, …]」形式で記載してください。 例: r: [オフラインデバイスの使用を制限する] オフラインデバイスの使用を制限する: [新しく加わったクライアントに初回設定を適用する, …] 新しく加わったクライアントに初回設定を適用する: [Windows, Mac] ※ 列インデックスも同様。 """) new_row_text = st.text_area("編集可能な 行インデックス", value=row_tree_text_default, key="row_text") new_col_text = st.text_area("編集可能な 列インデックス", value=col_tree_text_default, key="col_text") new_row_adj = parse_adj_list(new_row_text) new_col_adj = parse_adj_list(new_col_text) if "r" in new_row_adj: row_tree_raw = build_directed_tree(new_row_adj, "r") dummy_row = TreeNode("") dummy_row.children = row_tree_raw.children counter_row = [0] max_level_holder_row = [-1] assign_positions(dummy_row, -1, counter_row, max_level_holder_row) new_row_tree = dummy_row row_global = True else: new_row_root_key = new_row_text.splitlines()[0].split(":", 1)[0].strip() new_row_tree = build_directed_tree(new_row_adj, new_row_root_key) counter_row = [0] max_level_holder_row = [0] assign_positions(new_row_tree, 0, counter_row, max_level_holder_row) row_global = False if "r" in new_col_adj: col_tree_raw = build_directed_tree(new_col_adj, "r") dummy_col = TreeNode("") dummy_col.children = col_tree_raw.children counter_col = [0] max_level_holder_col = [-1] assign_positions(dummy_col, -1, counter_col, max_level_holder_col) new_col_tree = dummy_col col_global = True else: new_col_root_key = new_col_text.splitlines()[0].split(":", 1)[0].strip() new_col_tree = build_directed_tree(new_col_adj, new_col_root_key) counter_col = [0] max_level_holder_col = [0] assign_positions(new_col_tree, 0, counter_col, max_level_holder_col) col_global = False st.subheader("現在のインデックスツリー (Graphviz)") row_dot_before = tree_to_dot_format(new_row_tree, hide_dummy=True) st.graphviz_chart(row_dot_before) st.subheader("現在のインデックスツリー (Graphviz)") col_dot_before = tree_to_dot_format(new_col_tree, hide_dummy=True) st.graphviz_chart(col_dot_before) st.markdown(f"【行インデックス】レベル(ヘッダー行数):{max_level_holder_row[0] + 1}、リーフ数:{counter_row[0]}") st.markdown(f"【列インデックス】レベル(ヘッダー列数):{max_level_holder_col[0] + 1}、リーフ数:{counter_col[0]}") new_row_leaf_paths = get_leaf_paths(new_row_tree) new_col_leaf_paths = get_leaf_paths(new_col_tree) orig_total_cells = len(new_row_leaf_paths) * len(new_col_leaf_paths) st.markdown(f"検出されたセル数(行リーフ×列リーフ):{orig_total_cells} セル") if st.button("インデックス内容検証", key="validate_button"): new_row_leaves = [path[-1] for path in new_row_leaf_paths] new_col_leaves = [path[-1] for path in new_col_leaf_paths] if Counter(new_row_leaves) != Counter(get_expected_leaves(new_row_text)): st.error("行インデックスの葉のラベルが不一致です。元の状態にリセットします。") st.session_state.validated = False st.session_state.row_text = row_tree_text_default st.session_state.col_text = col_tree_text_default new_row_adj = parse_adj_list(row_tree_text_default) new_col_adj = parse_adj_list(col_tree_text_default) if "r" in new_row_adj: row_tree_raw = build_directed_tree(new_row_adj, "r") dummy_row = TreeNode("") dummy_row.children = row_tree_raw.children counter_row = [0] max_level_holder_row = [-1] assign_positions(dummy_row, -1, counter_row, max_level_holder_row) new_row_tree = dummy_row row_global = True else: new_row_root_key = row_tree_text_default.splitlines()[0].split(":", 1)[0].strip() new_row_tree = build_directed_tree(new_row_adj, new_row_root_key) counter_row = [0] max_level_holder_row = [0] assign_positions(new_row_tree, 0, counter_row, max_level_holder_row) row_global = False if "r" in new_col_adj: col_tree_raw = build_directed_tree(new_col_adj, "r") dummy_col = TreeNode("") dummy_col.children = col_tree_raw.children counter_col = [0] max_level_holder_col = [-1] assign_positions(dummy_col, -1, counter_col, max_level_holder_col) new_col_tree = dummy_col col_global = True else: new_col_root_key = col_tree_text_default.splitlines()[0].split(":", 1)[0].strip() new_col_tree = build_directed_tree(new_col_adj, new_col_root_key) counter_col = [0] max_level_holder_col = [0] assign_positions(new_col_tree, 0, counter_col, max_level_holder_col) col_global = False st.subheader("現在のインデックスツリー (Graphviz) [リセット]") row_dot_reset = tree_to_dot_format(new_row_tree, hide_dummy=True) st.graphviz_chart(row_dot_reset) st.subheader("現在のインデックスツリー (Graphviz) [リセット]") col_dot_reset = tree_to_dot_format(new_col_tree, hide_dummy=True) st.graphviz_chart(col_dot_reset) elif Counter(new_col_leaves) != Counter(get_expected_leaves(new_col_text)): st.error("列インデックスの葉のラベルが不一致です。元の状態にリセットします。") st.session_state.validated = False st.session_state.row_text = row_tree_text_default st.session_state.col_text = col_tree_text_default new_row_adj = parse_adj_list(row_tree_text_default) new_col_adj = parse_adj_list(col_tree_text_default) if "r" in new_row_adj: row_tree_raw = build_directed_tree(new_row_adj, "r") dummy_row = TreeNode("") dummy_row.children = row_tree_raw.children counter_row = [0] max_level_holder_row = [-1] assign_positions(dummy_row, -1, counter_row, max_level_holder_row) new_row_tree = dummy_row row_global = True else: new_row_root_key = row_tree_text_default.splitlines()[0].split(":", 1)[0].strip() new_row_tree = build_directed_tree(new_row_adj, new_row_root_key) counter_row = [0] max_level_holder_row = [0] assign_positions(new_row_tree, 0, counter_row, max_level_holder_row) row_global = False if "r" in new_col_adj: col_tree_raw = build_directed_tree(new_col_adj, "r") dummy_col = TreeNode("") dummy_col.children = col_tree_raw.children counter_col = [0] max_level_holder_col = [-1] assign_positions(dummy_col, -1, counter_col, max_level_holder_col) new_col_tree = dummy_col col_global = True else: new_col_root_key = col_tree_text_default.splitlines()[0].split(":", 1)[0].strip() new_col_tree = build_directed_tree(new_col_adj, new_col_root_key) counter_col = [0] max_level_holder_col = [0] assign_positions(new_col_tree, 0, counter_col, max_level_holder_col) col_global = False st.subheader("現在のインデックスツリー (Graphviz) [リセット]") row_dot_reset = tree_to_dot_format(new_row_tree, hide_dummy=True) st.graphviz_chart(row_dot_reset) st.subheader("現在のインデックスツリー (Graphviz) [リセット]") col_dot_reset = tree_to_dot_format(new_col_tree, hide_dummy=True) st.graphviz_chart(col_dot_reset) else: st.success("検証完了しました。") st.session_state.validated = True st.session_state.new_row_tree = new_row_tree st.session_state.new_col_tree = new_col_tree st.session_state.new_row_leaf_paths = new_row_leaf_paths st.session_state.new_col_leaf_paths = new_col_leaf_paths if st.button("新しいExcelファイルを生成", key="create_excel"): if not st.session_state.get("validated", False): st.error("まずインデックス内容の検証を行ってください。") st.stop() new_total_cells = len(st.session_state.new_row_leaf_paths) * len(st.session_state.new_col_leaf_paths) if orig_total_cells != new_total_cells: st.error(f"再構築されたセル数 ({new_total_cells}) と元のセル数 ({orig_total_cells}) が一致しません。") st.stop() old_row_labels = [] for i in range(header_levels, df_loaded.shape[0]): row_header_tuple = tuple(df_loaded.iloc[i, 0:index_levels]) old_row_labels.append(get_bottom_label(row_header_tuple)) old_col_labels = [] for j in range(index_levels, df_loaded.shape[1]): col_header_tuple = tuple(df_loaded.iloc[0:header_levels, j]) old_col_labels.append(get_bottom_label(col_header_tuple)) row_positions = defaultdict(deque) for i, lab in enumerate(old_row_labels): row_positions[lab].append(i) col_positions = defaultdict(deque) for j, lab in enumerate(old_col_labels): col_positions[lab].append(j) new_row_labels = [path[-1] for path in st.session_state.new_row_leaf_paths] new_col_labels = [path[-1] for path in st.session_state.new_col_leaf_paths] new_row_mapping = [] for lab in new_row_labels: if row_positions[lab]: new_row_mapping.append(row_positions[lab].popleft()) else: new_row_mapping.append(None) new_col_mapping = [] for lab in new_col_labels: if col_positions[lab]: new_col_mapping.append(col_positions[lab].popleft()) else: new_col_mapping.append(None) new_data = [] for i in range(len(new_row_mapping)): row_vals = [] for j in range(len(new_col_mapping)): r_idx = new_row_mapping[i] c_idx = new_col_mapping[j] if r_idx is not None and c_idx is not None: row_vals.append(safe_cell_value(df_loaded.iloc[r_idx + header_levels, c_idx + index_levels])) else: row_vals.append("") new_data.append(row_vals) top_left_width = max_level_holder_row[0] + 1 top_left_height = max_level_holder_col[0] + 1 output = io.BytesIO() workbook = xlsxwriter.Workbook(output, {'nan_inf_to_errors': True}) ws = workbook.add_worksheet("TreeStructure") header_format = workbook.add_format({ 'align': 'center', 'valign': 'vcenter', 'border': 1, 'text_wrap': True }) total_cols = top_left_width + len(new_row_mapping) total_rows = top_left_height + len(new_col_mapping) for col in range(total_cols): ws.set_column(col, col, 15) for r in range(total_rows): ws.set_row(r, 25) if top_left_width > 0 and top_left_height > 0: for c in range(top_left_width): ws.write(0, c, "A1/B1" if c == 0 else f"B{c+1}", header_format) for r in range(1, top_left_height): ws.write(r, 0, f"A{r+1}", header_format) if st.session_state.new_col_tree is not None: if col_global: col_ranges = [] for child in st.session_state.new_col_tree.children: col_ranges.extend(collect_col_header_ranges(child, top_left_height)) else: col_ranges = collect_col_header_ranges(st.session_state.new_col_tree, top_left_height) for (top, left, bottom, right, label) in col_ranges: abs_top = top abs_bottom = bottom abs_left = left + top_left_width abs_right = right + top_left_width if abs_top == abs_bottom and abs_left == abs_right: ws.write(abs_top, abs_left, label, header_format) else: ws.merge_range(abs_top, abs_left, abs_bottom, abs_right, label, header_format) if st.session_state.new_row_tree is not None: if row_global: row_ranges = [] for child in st.session_state.new_row_tree.children: row_ranges.extend(collect_row_header_ranges(child, top_left_width)) else: row_ranges = collect_row_header_ranges(st.session_state.new_row_tree, top_left_width) for (top, left, bottom, right, label) in row_ranges: abs_top = top + top_left_height abs_bottom = bottom + top_left_height abs_left = left abs_right = right if abs_top == abs_bottom and abs_left == abs_right: ws.write(abs_top, abs_left, label, header_format) else: ws.merge_range(abs_top, abs_left, abs_bottom, abs_right, label, header_format) for i, row_vals in enumerate(new_data): for j, cell in enumerate(row_vals): ws.write(top_left_height + i, top_left_width + j, cell, header_format) ws_row = workbook.add_worksheet("row_index") ws_col = workbook.add_worksheet("col_index") ws_row.write(0, 0, new_row_text, header_format) ws_col.write(0, 0, new_col_text, header_format) workbook.close() output.seek(0) st.download_button( label="更新されたExcelファイルをダウンロード", data=output, file_name="reconfigured_tree_structure.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" )
ツール 4: エクセルファイルのインデックスをツリーとシングルで相互変換するツール
インデックスをシングルとツリーに相互に変換します (図 11 と 12)。
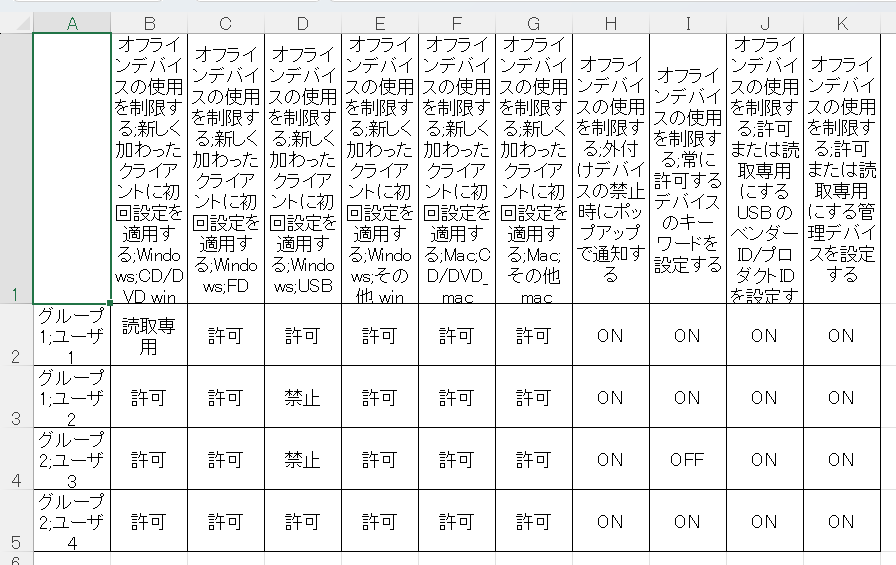
図 11. インデックスをツリーからシングルに変換。
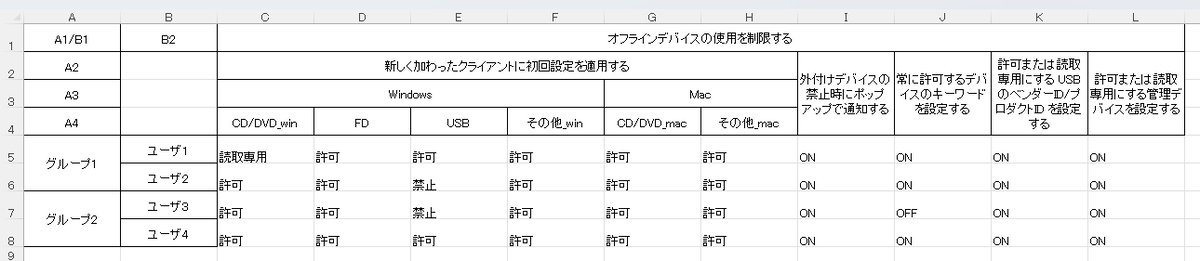
図 12. インデックスをシングルからツリーに再変換。
図 13. インデックス変換の UI。(本画像はツールの画面キャプチャのため、ご利用はできかねます。)
処理の概要
Step 1. ユーザ: UI からエクセルファイルを読み込み。
Step 2. ユーザ: 「TreeIndex → SingleIndex」と「SingleIndex → TreeIndex」のどちらかを選択 (図 13 を参照)。
Step 2-1. 変換モードが「TreeIndex → SingleIndex」の場合
Step 2-1-1. アップロードされたファイルから「TreeStructure」シートを読み出し、左上ブロックに記載されたインデックスレベルを自動検出。
Step 2-1-2. シングルインデックスのエクセルファイルに変換。
Step 2-2. 変換モードが「SingleIndex → TreeIndex」の場合
Step 2-2-1. アップロードされたExcelファイルからシングルインデックス形式でデータが読み込まれるとともに、保存されたツリー情報テキストを取得
Step 2-2-2. 再構築された行と列のツリー構造のリーフ数の積と、元のデータ部のセル数を照合し、不一致があればユーザーにエラーを表示して元の状態にリセットする処理が実行。
Step 2-2-3. 問題なければ、ツリーインデックスのエクセルファイルに変換。
Step 3. ユーザ: エクセルファイルをダウンロード。
treeindex_singleindex_conversion.py
import streamlit as st import pandas as pd import io import xlsxwriter import re from collections import Counter, defaultdict, deque from common.tree_utils import ( TreeNode, parse_adj_list, build_directed_tree, assign_positions, collect_col_header_ranges, collect_row_header_ranges ) from common.excel_utils import auto_detect_levels, write_left_top_block conversion_mode = st.radio("変換モードを選択してください", ["TreeIndex → SingleIndex", "SingleIndex → TreeIndex"]) if conversion_mode == "TreeIndex → SingleIndex": st.header("TreeIndex → SingleIndex 変換") st.markdown(""" ※ アップロードする Excel ファイルは、 シート "TreeStructure" にツリー構造(MultiIndex)が記載され、 シート "row_index" と "col_index" にツリー情報テキストが保存されています。 """) uploaded_file = st.file_uploader("TreeIndex の Excel ファイルをアップロードしてください", type=["xlsx"], key="tree_to_single") if uploaded_file is not None: try: row_levels, col_levels, df = auto_detect_levels(uploaded_file, max_levels=5, row_prefix="A", col_prefix="B") st.success(f"ツリーインデックスのレベル検出に成功! 行側: {row_levels} 層、列側: {col_levels} 層") except Exception as e: st.error(f"ツリーインデックスのレベル検出に失敗しました: {e}") st.stop() if isinstance(df.index, pd.MultiIndex): df.index = df.index.map(lambda x: ";".join([str(item).strip() for item in x if not str(item).strip().startswith("Unnamed")])) else: df.index = df.index.astype(str) if isinstance(df.columns, pd.MultiIndex): df.columns = df.columns.map(lambda x: ";".join([str(item).strip() for item in x if not str(item).strip().startswith("Unnamed")])) else: df.columns = df.columns.astype(str) output = io.BytesIO() with pd.ExcelWriter(output, engine="xlsxwriter") as writer: df.to_excel(writer, index=True, sheet_name="TreeStructure") try: row_index_df = pd.read_excel(uploaded_file, sheet_name="row_index", header=None, engine="openpyxl", dtype=str) col_index_df = pd.read_excel(uploaded_file, sheet_name="col_index", header=None, engine="openpyxl", dtype=str) row_index_text = row_index_df.iloc[0, 0] if not row_index_df.empty else "" col_index_text = col_index_df.iloc[0, 0] if not col_index_df.empty else "" except Exception as e: row_index_text = "" col_index_text = "" fmt = writer.book.add_format({'text_wrap': True, 'align': 'left', 'valign': 'top', 'border': 1}) ws_row = writer.book.add_worksheet("row_index") ws_col = writer.book.add_worksheet("col_index") ws_row.write(0, 0, row_index_text, fmt) ws_col.write(0, 0, col_index_text, fmt) output.seek(0) st.download_button( label="変換後の Excel ファイルをダウンロード", data=output, file_name="converted_single_index.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" ) elif conversion_mode == "SingleIndex → TreeIndex": st.header("SingleIndex → TreeIndex 変換") st.markdown(""" ※ アップロードされる Excel ファイルは、行・列ともにシングル・インデックス(セミコロン (;) 区切り) であり、さらにシート "row_index" と "col_index" に元のツリー構造テキストが保存されています。 これらインデックス情報を用いて、結合セルを使ったツリーインデックス仕様に再構成します。 """) uploaded_file = st.file_uploader("SingleIndex の Excel ファイルをアップロードしてください", type=["xlsx"], key="single_to_tree") if uploaded_file is not None: try: df = pd.read_excel(uploaded_file, index_col=0, engine="openpyxl") except Exception as e: st.error(f"Excel ファイルの読み込みに失敗しました: {e}") st.stop() try: row_idx_df = pd.read_excel(uploaded_file, sheet_name="row_index", header=None, engine="openpyxl", dtype=str) col_idx_df = pd.read_excel(uploaded_file, sheet_name="col_index", header=None, engine="openpyxl", dtype=str) row_tree_text = row_idx_df.iloc[0, 0] if not row_idx_df.empty else "" col_tree_text = col_idx_df.iloc[0, 0] if not col_idx_df.empty else "" except Exception as e: st.error(f"インデックス用シートの読み込みに失敗しました: {e}") st.stop() new_row_adj = parse_adj_list(row_tree_text) if "r" in new_row_adj: row_tree_raw = build_directed_tree(new_row_adj, "r") dummy_row = TreeNode("") dummy_row.children = row_tree_raw.children counter_row = [0] max_level_holder_row = [-1] assign_positions(dummy_row, -1, counter_row, max_level_holder_row) new_row_tree = dummy_row row_global = True else: new_row_root_key = row_tree_text.splitlines()[0].split(":",1)[0].strip() new_row_tree = build_directed_tree(new_row_adj, new_row_root_key) counter_row = [0] max_level_holder_row = [0] assign_positions(new_row_tree, 0, counter_row, max_level_holder_row) row_global = False row_header_size = max_level_holder_row[0] + 1 n_row_leaves = counter_row[0] new_col_adj = parse_adj_list(col_tree_text) if "r" in new_col_adj: col_tree_raw = build_directed_tree(new_col_adj, "r") dummy_col = TreeNode("") dummy_col.children = col_tree_raw.children counter_col = [0] max_level_holder_col = [-1] assign_positions(dummy_col, -1, counter_col, max_level_holder_col) new_col_tree = dummy_col col_global = True else: new_col_root_key = col_tree_text.splitlines()[0].split(":",1)[0].strip() new_col_tree = build_directed_tree(new_col_adj, new_col_root_key) counter_col = [0] max_level_holder_col = [0] assign_positions(new_col_tree, 0, counter_col, max_level_holder_col) col_global = False col_header_size = max_level_holder_col[0] + 1 n_col_leaves = counter_col[0] if df.shape[0] != n_row_leaves: st.error(f"行数の不一致: データ部行数 ({df.shape[0]}) ≠ ツリー行リーフ数 ({n_row_leaves})") st.stop() if df.shape[1] != n_col_leaves: st.error(f"列数の不一致: データ部列数 ({df.shape[1]}) ≠ ツリー列リーフ数 ({n_col_leaves})") st.stop() top_left_width = row_header_size top_left_height = col_header_size data_rows = df.shape[0] data_cols = df.shape[1] total_rows = top_left_height + data_rows total_cols = top_left_width + data_cols output = io.BytesIO() workbook = xlsxwriter.Workbook(output, {'nan_inf_to_errors': True}) ws = workbook.add_worksheet("TreeStructure") header_format = workbook.add_format({ 'align': 'center', 'valign': 'vcenter', 'border': 1, 'text_wrap': True }) for col in range(total_cols): ws.set_column(col, col, 15) for r in range(total_rows): ws.set_row(r, 25) if top_left_width > 0 and top_left_height > 0: write_left_top_block(ws, top_left_width, top_left_height, header_format) if col_global: col_ranges = [] for child in new_col_tree.children: col_ranges.extend(collect_col_header_ranges(child, col_header_size)) else: col_ranges = collect_col_header_ranges(new_col_tree, col_header_size) for (top, left, bottom, right, label) in col_ranges: abs_top = top abs_bottom = bottom abs_left = left + top_left_width abs_right = right + top_left_width if abs_top == abs_bottom and abs_left == abs_right: ws.write(abs_top, abs_left, label, header_format) else: ws.merge_range(abs_top, abs_left, abs_bottom, abs_right, label, header_format) if row_global: row_ranges = [] for child in new_row_tree.children: row_ranges.extend(collect_row_header_ranges(child, top_left_width)) else: row_ranges = collect_row_header_ranges(new_row_tree, top_left_width) for (top, left, bottom, right, label) in row_ranges: abs_top = top + top_left_height abs_bottom = bottom + top_left_height abs_left = left abs_right = right if abs_top == abs_bottom and abs_left == abs_right: ws.write(abs_top, abs_left, label, header_format) else: ws.merge_range(abs_top, abs_left, abs_bottom, abs_right, label, header_format) for i in range(data_rows): for j in range(data_cols): ws.write(top_left_height + i, top_left_width + j, df.iat[i, j]) ws_row = workbook.add_worksheet("row_index") ws_col = workbook.add_worksheet("col_index") ws_row.write(0, 0, row_tree_text, header_format) ws_col.write(0, 0, col_tree_text, header_format) workbook.close() output.seek(0) st.download_button( label="変換後の Excel ファイルをダウンロード", data=output, file_name="converted_tree_index.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" )
common
__init__.py
from .tree_utils import * from .excel_utils import *
excel_utils.py
import math import pandas as pd import re import streamlit as st def detect_excel_structure(uploaded_file): """ アップロードされた Excel ファイルから、シート "TreeStructure"、"row_index"、"col_index" を読み込み、以下の情報を返します。 ・df_loaded: シート "TreeStructure" の DataFrame(header=None) ・index_levels: シート "TreeStructure" の先頭行から算出した列インデックスのレベル数(例:"B1","B2"等) ・header_levels: シート "TreeStructure" の先頭列から算出した行インデックスのレベル数(例:"A1","A2"等) ・row_tree_text_default: シート "row_index" の A1 セルのテキスト ・col_tree_text_default: シート "col_index" の A1 セルのテキスト ※ 読み込みエラーや該当シートが空の場合は、Streamlit の st.error() と st.stop() により処理を終了します。 """ try: df_loaded = pd.read_excel(uploaded_file, sheet_name="TreeStructure", header=None, engine="openpyxl") n_rows, n_cols = df_loaded.shape col_pattern = re.compile(r"^(B\d+|A1/B1)$") index_levels = 0 for c in range(n_cols): cell_value = df_loaded.iloc[0, c] if isinstance(cell_value, str) and col_pattern.match(cell_value.strip()): index_levels += 1 else: break row_pattern = re.compile(r"^(A\d+|A1/B1)$") header_levels = 0 for r in range(n_rows): cell_value = df_loaded.iloc[r, 0] if isinstance(cell_value, str) and row_pattern.match(cell_value.strip()): header_levels += 1 else: break except Exception as e: print("Error") st.error(f"自動検出に失敗しました: {e}") st.stop() try: row_index_df = pd.read_excel(uploaded_file, sheet_name="row_index", header=None, engine="openpyxl", dtype=str) col_index_df = pd.read_excel(uploaded_file, sheet_name="col_index", header=None, engine="openpyxl", dtype=str) if row_index_df.empty or col_index_df.empty: st.error("シート row_index または col_index の内容が空です。") st.stop() row_tree_text_default = row_index_df.iloc[0, 0] col_tree_text_default = col_index_df.iloc[0, 0] except Exception as e: st.error(f"row_index または col_index シートの読み込みに失敗しました: {e}") st.stop() print("index_levels: {0}".format(index_levels)) print("header_levels: {0}".format(header_levels)) return df_loaded, index_levels, header_levels, row_tree_text_default, col_tree_text_default def write_left_top_block(ws, top_left_width, top_left_height, cell_format): """ Excel の左上交差部にインデックス名称(例:"A1/B1", "B2" など)を出力する """ if top_left_width > 0 and top_left_height > 0: for c in range(top_left_width): if c == 0: ws.write(0, c, "A1/B1", cell_format) else: ws.write(0, c, f"B{c+1}", cell_format) for r in range(1, top_left_height): ws.write(r, 0, f"A{r+1}", cell_format) def auto_detect_levels(uploaded_file, max_levels=5, row_prefix=None, col_prefix=None): """ アップロードされた Excel ファイルのシート "TreeStructure" から左上ブロックを読み込み、 行・列のインデックスレベルを検出して DataFrame を返す。 戻り値: (index_levels, header_levels, df) """ uploaded_file.seek(0) df_raw = pd.read_excel(uploaded_file, sheet_name="TreeStructure", header=None, engine="openpyxl", dtype=str) n_rows, n_cols = df_raw.shape col_pattern = re.compile(r"^(B\d+|A1/B1)$") index_levels = 0 for c in range(n_cols): cell_value = df_raw.iloc[0, c] if isinstance(cell_value, str) and col_pattern.match(cell_value.strip()): index_levels += 1 else: break row_pattern = re.compile(r"^(A\d+|A1/B1)$") header_levels = 0 for r in range(n_rows): cell_value = df_raw.iloc[r, 0] if isinstance(cell_value, str) and row_pattern.match(cell_value.strip()): header_levels += 1 else: break if index_levels == 0 or header_levels == 0: raise ValueError("Excelファイルの左上交差部からインデックスレベルを検出できませんでした。") uploaded_file.seek(0) try: df = pd.read_excel( uploaded_file, sheet_name="TreeStructure", header=list(range(header_levels)), index_col=list(range(index_levels)), engine="openpyxl" ) except Exception as e: raise ValueError(f"Excelファイルの読み込みに失敗しました: {e}") idx_names = df.index.names col_names = df.columns.names if row_prefix is not None: if not all(isinstance(name, str) and name.startswith(row_prefix) for name in idx_names if name): raise ValueError("行インデックスの名称に期待する接頭辞が見つかりませんでした。") if col_prefix is not None: if not all(isinstance(name, str) and name.startswith(col_prefix) for name in col_names if name): raise ValueError("列インデックスの名称に期待する接頭辞が見つかりませんでした。") return index_levels, header_levels, df def safe_cell_value(val): """ セルの値が NaN や INF の場合に空文字に変換する """ try: if isinstance(val, float) and (math.isnan(val) or math.isinf(val)): return "" if pd.isna(val): return "" return val except Exception: return ""
tree_utils.py
import re class TreeNode: def __init__(self, label): self.label = label self.children = [] self.level = 0 self.start = 0 self.end = 0 def parse_adj_list(text): """テキストから 'ノード: [子1, 子2, …]' 形式の隣接リストを生成""" adj = {} for line in text.splitlines(): line = line.strip() if not line or ':' not in line: continue key_part, value_part = line.split(":", 1) key = key_part.strip() value_part = value_part.strip() if value_part.startswith('[') and value_part.endswith(']'): inner = value_part[1:-1] if inner.strip() == "": children = [] else: children = [token.strip() for token in inner.split(",") if token.strip()] else: children = [] adj[key] = children return adj def build_directed_tree(adj, current): """隣接リストから再帰的に有向木を生成""" node = TreeNode(current) for child in adj.get(current, []): node.children.append(build_directed_tree(adj, child)) return node def assign_positions(node, level, counter, max_level_holder): """ DFS で各ノードに階層 level と表示順 (start, end) を割り当てる counter: リスト形式で[初期位置](参照渡し) max_level_holder: [現在の最大レベル] """ node.level = level if level > max_level_holder[0]: max_level_holder[0] = level if not node.children: node.start = counter[0] node.end = counter[0] counter[0] += 1 else: for child in node.children: assign_positions(child, level + 1, counter, max_level_holder) node.start = node.children[0].start node.end = node.children[-1].end def collect_col_header_ranges(node, header_rows): """ 列ヘッダー領域のセル結合範囲を収集する · 非葉ノード:node.level 行、左=最初の子の start、右=最後の子の end · 葉ノード:node.level~(header_rows-1) 行、列は node.start 固定 """ ranges = [] if node.children: for child in node.children: ranges.extend(collect_col_header_ranges(child, header_rows)) top = node.level bottom = node.level left = node.children[0].start right = node.children[-1].end ranges.append((top, left, bottom, right, node.label)) else: top = node.level bottom = header_rows - 1 left = node.start right = node.start ranges.append((top, left, bottom, right, node.label)) return ranges def collect_row_header_ranges(node, header_cols): """ 行ヘッダー領域のセル結合範囲を収集する · 非葉ノード:node.level 列、上=最初の子の start、下=最後の子の end · 葉ノード:node.level~(header_cols-1) 列、行は node.start 固定 """ ranges = [] if node.children: for child in node.children: ranges.extend(collect_row_header_ranges(child, header_cols)) left = node.level right = node.level top = node.children[0].start bottom = node.children[-1].end ranges.append((top, left, bottom, right, node.label)) else: top = node.start bottom = node.start left = node.level right = header_cols - 1 ranges.append((top, left, bottom, right, node.label)) return ranges def rec_graph(node, counter): """Graphviz用:再帰的に DOT 記述用の行を生成""" current_id = counter[0] counter[0] += 1 safe_label = node.label.replace('"', '\\"') lines = [f' {current_id} [label="{safe_label}"];'] for child in node.children: child_id, child_lines = rec_graph(child, counter) lines.append(f' {current_id} -> {child_id};') lines.extend(child_lines) return current_id, lines def tree_to_dot_format(tree, hide_dummy=False): """ ツリーを Graphviz 用 DOT 形式に変換する。 ダミーノード(ラベルが空文字)の場合、hide_dummy=True なら子のみ出力する。 """ counter = [0] lines = [] if hide_dummy and tree.label == "" and tree.children: for child in tree.children: child_id, child_lines = rec_graph(child, counter) lines.extend(child_lines) else: root_id, root_lines = rec_graph(tree, counter) lines.extend(root_lines) dot_code = "digraph Tree {\n" + "\n".join(lines) + "\n}" return dot_code def collect_leaf_paths(node, path, collected): """ 再帰的に各葉ノードまでのパスを収集する。 path に親ノードのラベルを順に追加していき、葉に達したら collected に追加する。 """ new_path = path + [node.label] if not node.children: collected.append(new_path) else: for child in node.children: collect_leaf_paths(child, new_path, collected) def pad_path(path, desired_length): """葉パスが desired_length に満たない場合、末尾を空文字でパディングしてタプルにする""" return tuple(path + [""] * (desired_length - len(path))) def get_leaf_paths(node): """ ツリーから葉ノードまでのパスを取得する(タプルのリスト)。 ※子がリーフの場合は、親のラベルを付与せず直接子のラベルのみ返す形にする。 """ if not node.children: return [(node.label,)] paths = [] for child in node.children: if not child.children: paths.append((child.label,)) else: for sub in get_leaf_paths(child): paths.append((node.label,) + sub) return paths def multiindex_to_nested_dict(mi): """MultiIndex の各要素からネストした辞書構造を生成する""" nested = {} for tup in mi: cur = nested for label in tup: if label not in cur: cur[label] = {} cur = cur[label] return nested def nested_to_lines(nd): """ネストした辞書構造から 'ノード: [子1, 子2,...]' 形式のテキスト行リストを生成する""" lines = [] for key, sub in nd.items(): if sub: children = list(sub.keys()) lines.append(f"{key}: [" + ", ".join(map(str, children)) + "]") lines.extend(nested_to_lines(sub)) return lines def multiindex_to_tree_text(mi): """MultiIndex からツリー構造テキストに変換する""" nd = multiindex_to_nested_dict(mi) lines = [] if len(nd) > 1: top_keys = list(nd.keys()) lines.append("r: [" + ", ".join(map(str, top_keys)) + "]") lines.extend(nested_to_lines(nd)) else: lines.extend(nested_to_lines(nd)) return "\n".join(lines)
本記事ではツリーインデックスをもつエクセルファイルを効率的に取り扱うツール群を紹介しました。様々な業務において、エクセルファイルの結合セルのインデックスをツリーとみなすことで見通しが良くなり、プログラム的に取り扱いやすくなりました。
また、このように複雑な結合セルのインデックスを体系的に取り扱うような考え方は、私の知る限り存在せず、知見としては新しいと考えております。
今後の展開としては、テスト自動化における仕様書や期待値の台紙の作成、差分抽出、及び変換等に使用予定です。
お読みいただきありがとうございました。
[1] マルチインデックスをもつエクセルファイルの作成ツール
{kind=link}