


こちらはABEJAアドベントカレンダー2025の7日目の記事です。
こんにちは、プラットフォーム共通基盤Gの内田です。現在、大量のフィジカルデータからAI向けのデータ基盤を構築するプロジェクトに関わっています。そこで利用するツールの候補として挙がっているのが、本記事で紹介する Kedro です。
自分自身は、データ分析やデータパイプライン基盤づくりの経験はまだ多くありません。そこで今回、Kedroを調査しながら「どんな場面で使えそうか」「実際にどうやって触り始めればよいか」を整理し、ブログとしてまとめることにしました。
このブログを読めば、Kedroがどんな用途に向いているか(利用ポイント)、手元の分析処理を、とりあえずKedroのパイプラインとして形にするまでの流れ をイメージできる状態になることを目指しています。
データ分析やPoCを続けていると、だいたいこんな悩みが出てくるそうです。
- 最初は
analysis.ipynbひとつだったのに、いつの間にかanalysis_v2.ipynb/analysis_final.ipynb/analysis_final2.ipynb…が増殖する - 「このレポート、先月と同じ条件で出し直して」と言われても、どのNotebook・どのセルをどの順番で実行したか覚えていない
- ローカルのパスをベタ書きしていて、同僚に渡したら動かない
- コードレビューしようとしても、「前処理」「特徴量」「学習」「評価」が1つのNotebookに混ざっていて追いづらい
つまり、処理の流れ(パイプライン)が暗黙知になっているのが問題です。Kedroはデータパイプラインを明示的に作成・管理することでこの課題を解決することができます。Kedroを使うことで以下のような効果が期待できます。
- どのデータがどこから来て、どんな前処理を通って、最終的な成果物にたどり着いているかわかる
- 同じ処理を、別データ・別日・別環境でも再現できる
- 新しいメンバーが入ったときに、「どこから読めばいいか」が分かる
基本的な情報ソース
Kedroは、Linux Foundation(LF AI & Data)傘下のOSSとして開発されている、Python製のデータパイプラインフレームワークです。(Kedro)
チェックしておくべき公式リソースはこの3つです。
- 公式サイト(概要・特徴・ブログ)(Kedro)
- 公式ドキュメント(Getting Started, Concepts, チュートリアル)(docs.kedro.org)
- YouTubeチャンネル(Coffee Chatや入門動画)(YouTube)
3つの基本要素:Node / Pipeline / Data Catalog
Kedroを理解するうえで、まずは次の3つだけ押さえておけば十分です。
- Node
- 「1つの仕事をする Python 関数」を、パイプラインの部品として登録したもの
- 例:
load_machine_log,clean_data,train_model,generate_report
- Pipeline
- Node同士をつないだ「処理の流れ(DAG)」
- 例:生データ → 前処理 → 結合 → 指標計算 → レポート出力
- Data Catalog
- 「どの名前のデータが、どのファイル/DB/クラウドにあるのか」をYAMLで管理する仕組み
- 例:
machine_logはdata/01_raw/machine_log.csv、qa_resultはdata/05_model_input/qa_result.parquetなど
重要なのは、Node の引数・戻り値の名前と、Data Catalog のキーが一致するという点です。
これにより、コードは「Pandas DataFrameが来て、DataFrameを返す」ことだけに集中し、どこに保存するか・どのフォーマットかはCatalogに追い出せます。
パイプライン作成のワークフロー
典型的なパイプラインの作り方はこんな流れです。(docs.kedro.org)
- Notebookやスクリプトで書いていた処理を関数に切り出す
- その関数を Node として登録する
- Nodeを順番に並べて Pipeline を定義する
- 入出力の名前を Data Catalog(YAML)に記述する
kedro runでパイプライン全体を実行する
慣れてきたら、「パイプラインを複数に分けて名前空間で管理する」「MLflowやSageMakerに接続する」といった発展パターンにも進めます。(Amazon Web Services, Inc.)
運用までの流れ
Kedro単体は「処理の中身と構造」をきれいにするためのツールです。
- ローカル開発:Kedro + Jupyter / VSCode
- チーム共有:KedroプロジェクトをGitで管理、CIで
kedro runを実行 - 本番バッチ:Airflow / Argo / GitHub Actions などから Kedro のパイプラインを呼び出す
という分担をイメージしておくと、「MLOpsフレームワークの一部」として位置づけやすくなります。
ここでは、uv を使ってKedroのミニプロジェクトを作り、簡単なパイプラインを実行するところまでをざっと見てみます。
4.1 uvxでプロジェクトを作る
作業に使用するuvとpythonのバージョンは以下の通りです。
uvx 0.9.10 (Homebrew 2025-11-17) Python 3.9.6
まずは適当な作業フォルダに移動し、以下のコマンドでKedroのプロジェクトをテンプレートから生成します。
uvx kedro new
対話形式でいくつか質問されるので、たとえば以下のように回答します:
Project Name ============ Please enter a name for your new project. Spaces, hyphens, and underscores are allowed. To skip this step in future use --name [New Kedro Project]: <span style="color: #d32f2f">kedro-demo</span> Project Tools ============= These optional tools can help you apply software engineering best practices. To skip this step in future use --tools To find out more: https://docs.kedro.org/en/stable/starters/new_project_tools.html Tools 1) Lint: Basic linting with Ruff 2) Test: Basic testing with pytest 3) Log: Additional, environment-specific logging options 4) Docs: A Sphinx documentation setup 5) Data Folder: A folder structure for data management 6) PySpark: Configuration for working with PySpark Which tools would you like to include in your project? [1-6/1,3/all/none]: [none]: <span style="color: #ff0000">5</span> Example Pipeline ================ Select whether you would like an example spaceflights pipeline included in your project. To skip this step in the future use --example=y/n To find out more: https://docs.kedro.org/en/stable/starters/new_project_tools.html Would you like to include an example pipeline? [y/N]: [no]: Congratulations!
作成が終わったら、生成されたプロジェクトディレクトリに入ります。あとの作業で必要なモジュールも追加しておきます。
cd kedro-demo uv add kedro pandas lxml kedro-datasets[pandas]
この時点で、プロジェクトのファイル構成は以下のようになっています。
.
├── conf
│ ├── base
│ │ ├── catalog.yml
│ │ └── parameters.yml
│ ├── local
│ │ └── credentials.yml
│ └── README.md
├── data
│ ├── 01_raw
│ ├── 02_intermediate
│ ├── 03_primary
│ ├── 04_feature
│ ├── 05_model_input
│ ├── 06_models
│ ├── 07_model_output
│ └── 08_reporting
├── notebooks
├── pyproject.toml
├── README.md
├── requirements.txt
└── src
└── kedro_demo
├── __init__.py
├── __main__.py
├── pipeline_registry.py
├── pipelines
│ └── __init__.py
└── settings.py
4.2 exampleパイプラインの作成
公式の「Minimal Kedro Project」の手順にならって、exampleという名前の単純なパイプラインを1つ作ってみます。(docs.kedro.org) 例として、「数値のリストを読み込み、平均値を計算して出力する」だけのパイプラインにします。
Node関数の作成
kedro_demo/pipelines/example/nodes.py を作成します。
import pandas as pd def load_numbers() -> pd.DataFrame: return pd.DataFrame({"value": [1, 2, 3, 4, 5]}) def calc_mean(df: pd.DataFrame) -> float: return df["value"].mean()
Pipeline定義
src/kedro_demo/pipelines/example/pipeline.py でNodeをつなぎます。
from kedro.pipeline import Pipeline, node from .nodes import load_numbers, calc_mean def create_pipeline(**kwargs) -> Pipeline: return Pipeline( [ node( func=load_numbers, inputs=None, outputs="numbers", name="load_numbers_node", ), node( func=calc_mean, inputs="numbers", outputs="mean_value", name="calc_mean_node", ), ] )
Kedroでexampleパイプラインを検出できるように、src/kedro_demo/pipelines/example/__init__.pyにcreate_pipelineを登録します。
from .pipeline import create_pipeline
Data Catalog設定
conf/base/catalog.yml に出力データセットを追加します。
numbers: type: pandas.CSVDataset filepath: data/01_raw/numbers.csv save_args: index: False mean_value: type: pandas.CSVDataset filepath: data/08_reporting/mean_value.csv save_args: index: False
それぞれの行の意味は以下の通りです。
numbers:(データセット名):
– 名前(キー): この numbers は Catalog 内での識別子です。pipeline.py の outputs="numbers" に対応します。
type: pandas.CSVDataset:
– 実装クラスを指す文字列で、kedro-datasets[pandas] パッケージが提供する CSV 用データセットです。これにより Kedro は読み込み時に pd.read_csv、保存時に DataFrame.to_csv を内部で呼び出します。
filepath: data/01_raw/numbers.csv:
– CSV の読み書きに使うファイルパスです。通常はプロジェクトルート(Kedro 実行時のカレント)からの相対パスになります。
注意: 親ディレクトリが存在しないと保存時にエラーになることがあるため、ディレクトリを事前に作るか、環境側で作成する仕組みを用意してください(Kedro の Dataset 実装により自動作成されることもあるが、確実にしたい場合は明示的に作成するのが安全です)。
save_args 以下は DataFrame.to_csv(…) に渡されるキーワード引数です。ここに書いた設定で CSV 保存時の挙動を制御できます。
例(現在): index: False は行インデックスを CSV に書き出さない設定です(多くの場合、DataFrame の index をファイルに出したくないので False にします)。
4.3 パイプラインを実行してみる
準備ができたら、いよいよパイプラインを実行します。
uv run kedro run
正常に動けば、以下のデータがCSVファイルに出力されているはずです。
data/01_raw/numbers.csvに[1,2,3,4,5]のデータdata/08_reporting/mean_value.csvに平均値3.0
ここまでで、Kedroプロジェクトの作成 -> Node / Pipeline / Data Catalog のひと通りの流れ -> uv run での実行 という最小セットを体験できました。
Kedroのもう一つの魅力が、パイプラインをDAGとして可視化できる Kedro-Viz です。(docs.kedro.org)
5.1 インストールと起動
まずはパッケージを追加します。
uv add kedro-viz
その上で、プロジェクトルートで次を実行します。
uv run kedro viz
ブラウザが開き、パイプラインのグラフが表示されます。
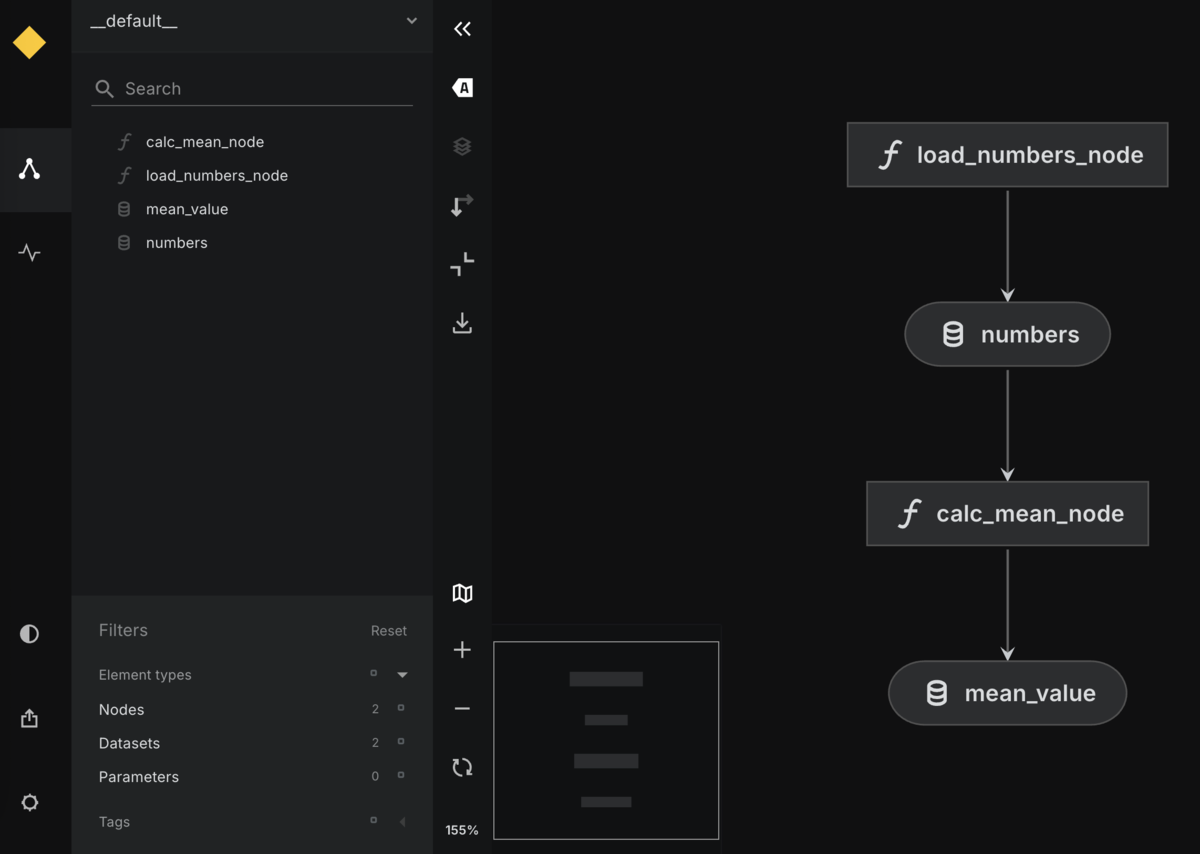
四角は、Node(処理)を表しており、丸は、Dataset(Data Catalogで定義した入出力)を表しています。
先ほどの例だと、load_numbers_node → numbers → calc_mean_node → mean_value という流れが矢印付きで表示されます。
5.2 Kedro-Vizでできること
Kedro-Vizでは、単なる「お絵かき」以上のことができます。(docs.kedro.org)
- ノードをクリックして、どのモジュールのどの関数かを確認
- データセットをクリックして、ファイルパス・種類(CSV/Parquetなど)を確認
- 部分的なサブグラフをハイライトして、担当者ごとに責務を分ける
- (プロジェクトによっては)簡単なデータプレビューを表示
開発者目線では、パイプライン処理についてチーム内で説明するときや、新しく追加したNodeの位置が意図通りかチェックするときに便利です。
Kedroについて調べてみて、AIや機械学習以外のデータ分析業務にも使えそうだと感じました。そこで、ここからは「MLエンジニアではない人が Kedro をどう使うか?」という観点で、いくつかユースケースを考えてみます。
MLエンジニア以外でも使えそうなところ
Kedro活用のポイントは、「毎回やっている手作業の流れを、Nodeに分解してPipeline化する」ことです。その場合、以下のユースケースでも活用できそうです。
- データ分析チームでの定例レポート作成
- BI向けの集計前処理(データウェアハウス手前のPython加工)
- IoT/FA分野でのログ解析、装置ヘルスチェック
放射線治療におけるDaily QAデータ分析
ユースケースを少し具体化し、私の経験がある放射線治療の現場を例に考えてみます。
- 入力データ
- 加速器のマシンロギング(エネルギー、ビーム電流、ガントリ角度、モニタ線量など)
- QA装置(電離箱アレイ、ファントム)の測定線量・プロファイル
- 課題
- ベンダーごとにフォーマットが異なる
- 検証項目(プロファイル一致度、線量偏差など)が複数あり、Excelでの手計算だとつらい
- 日々の結果をトレンドとして追いたい
Kedroで組み立てると、例えばこんなパイプラインが組めそうです。
load_machine_log:マシンロギングファイルを読み込んで標準化load_qa_measurement:QAデバイスの出力を読み込んで標準化join_by_delivery_id:照射IDやタイムスタンプでマージcalc_qa_metrics:線量偏差[%]、位置ずれ[mm]、ガントリ角ごとの統計量を計算generate_daily_report:PDF/HTMLなどでレポートを出力
Data Catalogで「マシンログ」「QA測定」「結合結果」「レポート用テーブル」などを整理しておけば、
kedro run --pipeline=daily_qa だけで毎日のQA解析が再現可能になります。
大学研究室での実験データパイプライン
学生時代を思い返すと、研究室の小規模な物理実験でも、似たような構造で分析パイプラインが組めそうです。
- 装置ログ(電圧・電流・温度・ビームパラメータ)
- 計測器の出力(CSV, バイナリ)
- 実験条件(試料ID・位置・日付・オペレータ)
これらをKedroでパイプライン化すると:
- 毎回同じ解析フローを、別条件・別試料に対して適用できる
- 学生や共同研究者に解析手順を共有しやすい
- 実験ノート+解析コードの「再現性」が上がる
Apache Airflowと組み合わせるパターン
本番運用で「毎朝9時に前日のQA解析を回す」みたいな要件が出てくると、Airflow や他のスケジューラと組み合わせるのが現実的です。
- Kedro:Python側のパイプライン定義(Node / Pipeline / Data Catalog)
- Airflow:いつ・どの環境で・どのパイプラインを実行するか(スケジューリング)
という役割分担にしておくと、
- ロジック変更 → Kedro側のNode・Pipeline修正
- 実行タイミング変更 → Airflow側のDAG修正
と整理でき、メンテナンス性の向上に繋がります。
Airflowについては、最近のABEJA Tech Blogもぜひ参照してください!
最後に、この記事から一歩進むための公式リソースをまとめておきます。
Kedro HP / ドキュメント
- Kedro公式サイト(概要、Why Kedro?, Features, 事例など)(Kedro)
- Getting Started / First steps / Minimal project などの公式ドキュメント(docs.kedro.org)
最初は「First steps」「Create a Minimal Kedro Project」あたりを読むのがおすすめです。
Kedro YouTube Channel
- 公式YouTubeチャンネル(Coffee Chatや入門シリーズ)(YouTube)
- 「New to Kedro? Start Here!」系の動画は、この記事の内容とかなり重なるので復習にちょうど良いです。(YouTube)
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
careers.abejainc.com
特に下記ポジションの募集を強化しています!ぜひ御覧ください!
{kind=link}