


こんにちは。 弁護士ドットコム株式会社でクラウドサインという電子契約サービスのバックエンドを担当しているブイ・ザイン・トゥンと申します。
SRE という仕事にとても惹かれており、現在は勉強の一環として「Designing Data-Intensive Applications」を読んでいます。その中で「信頼性」という概念が、エンジニアにとっていかに重要かをあらためて実感しました。このブログでは、本から学んだことや、自分で調べて理解した内容を整理してブログとしてまとめていきたいと思います。
ソフトウェアの信頼性について考えてみる
「信頼性」って、一言で説明するのは難しいですよね。人によってその定義はさまざまですが、「信頼性の高いソフトウェア」 は一般的に次の 4 つの期待に応えるものだと考えられます。
- ユーザーが期待した機能を果たすこと
- ユーザーのミスや予期せぬ使い方にも耐えられること
- 期待される負荷とデータ量の下で、要求されるユースケースに対して十分なパフォーマンスがあること
- 不正なアクセスや悪用を防止できること
これらすべてが「まさしく動作する」ことを意味するのであれば、信頼性とは「問題が発生しても、正しく動作し続けること」と捉えることができます。
フォールトとフェイラー:エンジニアなら知っておきたい2つの違い
では、この「問題」とは具体的に何を指すのでしょうか? これが、これから説明する「フォールト」です。ここで注意すべきは、フェイラーと同じではないということです。フォールトは、通常、システムの一部のコンポーネントが仕様から逸脱することと定義されます。 それに対し、フェイラーは、システム全体がユーザーに要求されるサービスを提供できなくなること、つまりシステムが完全に停止することを意味します。
例えば、アプリがリクエストを送った先のデータベースが一時的に応答しなくなった場合でも、別のデータベースが代わりに応答するような設計にすることで、ユーザーには影響が出ません。これは、フォールトは発生しているものの、システム全体としては正常に動作しており、フェイラーには至っていない例です。
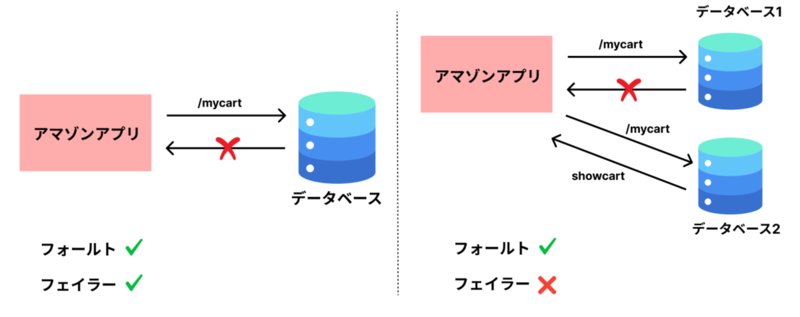
フォールトが起きても「へっちゃら」なシステム
フォールトを事前に予測し、それに対処できるシステムは、「耐障害性がある」 、あるいは 「回復力がある」 と呼ばれます。
残念ながら、フォールトが起きる確率をゼロにすることは不可能です。だからこそ、私たちは「絶対に壊れないものを作る」のではなく「フォールトが起きても、それが大きなフェイラーに繋がるのを防ぐ」仕組みを設計することが、もっとも賢いやり方なのです。
これはまるで、車を運転する際に事故を完璧に防ぐことはできなくても、エアバッグやシートベルトを準備しておくようなものです。
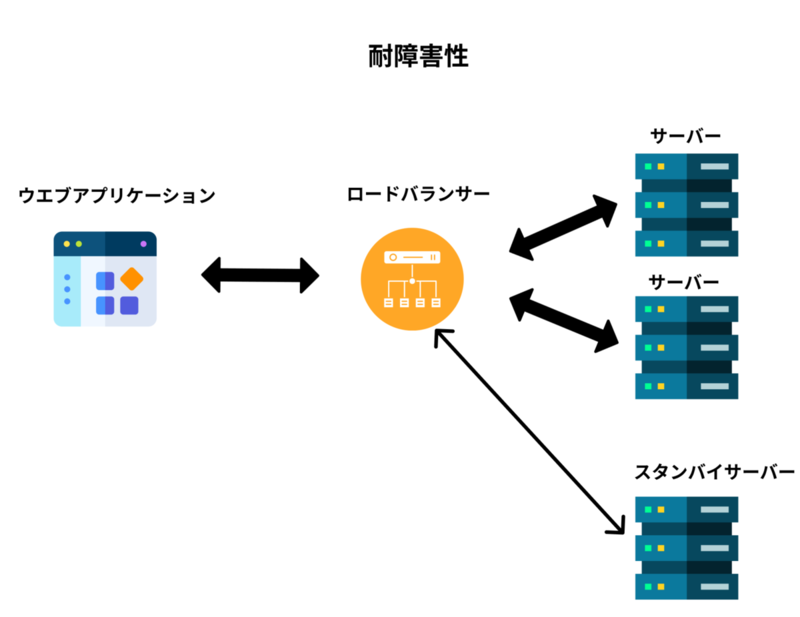
さて、ここからは修復可能なフォールトについて議論していきましょう。
ハードウェアフォールト
ハードウェアフォールトとは何か?
ハードウェアフォールト、つまり物理的な部品の故障や劣化は、システムの信頼性を脅かすもっとも身近な問題の 1 つです。メモリ、ハードディスク、USB デバイスなど、どんな機械もいつかは壊れます。特に、大規模なデータセンターで働いたことがある方なら、何千台ものマシンがあれば、こうした故障が日常的に起こることをご存じのはずです。
「Designing Data-Intensive Applications」を現在読んでいる中で、著者が次のように述べているのが印象的でした:「ハードディスクの平均故障間隔(MTTF)はおよそ 10 年から 50 年と報告されています。したがって、1 万台のディスクを備えたストレージクラスターでは、平均して 1 日に 1 台のディスクが故障すると予想されます」
実際、Backblazeが2025年第1四半期に発表した統計によれば、ハードディスク全体の年間故障率(AFR)は 約1.42% でした。これは、どんなに信頼性の高い部品でも、一定の割合で必ず故障が発生するという現実を明確に示しています。

幸いなことに、ほとんどのハードウェアフォールトはランダムかつ独立して発生する傾向があります。つまり、あるマシンのディスクが故障したとしても、それが直ちに別のマシンのディスク故障に直結するわけではありません。ただし、同一の製造ロットや環境要因(温度、湿度、電力障害など)により、弱い相関関係はあるかもしれませんが、それ以外では、多数のハードウェアコンポーネントが同時に故障する可能性は低いと言えます。
ハードウェアの冗長化による信頼性向上
こうしたフォールトを防ぐためのアプローチの 1 つとして、システム全体の故障率を低減するために、各ハードウェアコンポーネントに冗長性を持たせることが挙げられます。
例えば、ディスクは RAID(Redundant Array of Independent Disks)構成で冗長化されます。RAID とは複数のディスクにデータを分散して保存する技術です。これにより、1 台のディスクが故障しても、他のディスクからデータを復元できるため、システム全体の信頼性が向上します。
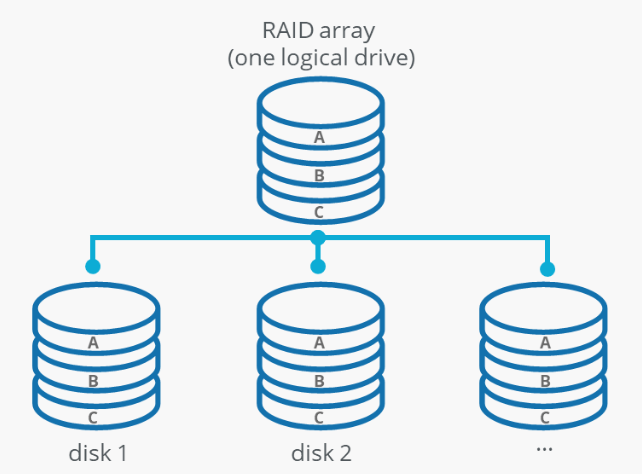
このハードウェアの冗長性というアプローチは、つい最近まで、ほとんどのアプリケーションにとって十分でした。故障した場合でも、新しいマシンにバックアップを比較的迅速に復元できる限り、ほとんどのアプリケーションではダウンタイムは壊滅的なものではありません。
ハードウェア冗長性からフォールトトレランスへ
データ量や計算需要が爆発的に増えるにつれて、現代のアプリケーションはもはや一台の大きなマシンでは動きません。何百、何千ものマシンが連携して動くようになりました。当然、マシンの数が増えれば、ハードウェアフォールトの発生頻度も比例して高くなります。
現在、クラウド環境では、仮想マシン(VM)が予告なく停止・削除されることがよくあります。これは、個々のマシンの可用性を保証するのではなく、システム全体としての柔軟性と耐障害性を重視するという、クラウドの設計思想によるものです。
その結果として、クラウド上のインスタンスは一時的かつ交換可能なリソースとみなされており、いつ停止しても業務に影響を与えないようなアーキテクチャの設計が求められています。つまり、インフラの信頼性をハードウェアや特定の VM に依存せず、システム全体で吸収するという考え方が、クラウド時代の基本となっています。
したがって、ハードウェアの冗長性に代わる、あるいはそれに加えて、ソフトウェアのフォールトトレランス技術を用いることで、マシン全体の損失に耐えられるシステムを構築するアプローチは、運用面でも大きな利点があります。例えば、セキュリティパッチを適用するためにマシンを再起動する場合、単一サーバーのシステムではサービスを停止せざるを得ません。しかし、耐障害性のあるシステムなら、サービスを中断することなく、マシンを 1 台ずつアップデートできるため、他のマシンは稼働し続けることができます。
ソフトウェアエラー
システムの信頼性を脅かすソフトウェアエラー
システムの信頼性を脅かすもう 1 つの大きな問題は、システム内の 「ソフトウェアエラー」 、つまり系統的なフォールトです。これらはハードウェアフォールトとは異なり、予測がより困難で、ノード間で相関して発生するため、より多くのシステムフェイラーを引き起こす傾向があります。
なぜなら、同じコードを実行しているすべてのサーバーに同じバグが存在するからです。特定の入力やまれな状況が重なったときに、すべてのインスタンスが同時にクラッシュしてしまう…そんな悪夢のようなシナリオも実際に起こり得ます。
過去には、こうしたソフトウェアフォールトが、私たちの想像を超える壊滅的な被害をもたらしてきました。その中でも特に有名な事例をいくつか見てみましょう。
– 2012 年のうるう秒: Linux カーネルのバグにより、多くのアプリケーションが同時にフリーズしました
– 2000 年問題(Y2K 問題): 年を 2 桁で表すバグが、広範囲のシステムに誤作動を引き起こす恐れがありました
– パトリオットミサイルシステムの悲劇: 1991 年の湾岸戦争中、ソフトウェアによる計算の誤差でミサイルが迎撃に失敗し、28 人が死亡するという悲劇的な結果を招きました

壊滅的なバグを防ぐための日常習慣
これらの例が示すように、ソフトウェアの系統的なバグには、手っ取り早い解決策はありません。たった 1 つのミスが、システム全体を停止させる可能性があるからです。だからこそ、日々の小さな努力の積み重ねが不可欠になります。例えば、以下のような対策が挙げられます。
- 厳格なコードレビュー
- システム内の前提条件や相互作用を注意深く検討すること
- 自動的に徹底的なテスト(ユニットテスト、統合テスト、手動テストなど)を行うこと
- プロセスを分離し、1 つのプロセスが落ちても全体に影響しない設計にすること
- 本番環境でのシステムの挙動を測定、監視、分析すること
- 段階的なデプロイ: 全体を一度にデプロイするのではなく、カナリアリリースやブルー/グリーンデプロイメントといった手法を用いること
人為的ミス
システム障害の原因と聞くと、多くの人は「ハードの故障」や「ソフトの不具合」を思い浮かべるかもしれません。ところが実際には、意外なほど多くのトラブルが「人間のちょっとしたミス」から始まっているのです。
サーバーやネットワーク機器の設定を一行間違えた、手順を勘違いした、確認を怠った……。現場ではよくある些細なミスが、時に何百万人ものユーザーに影響を与える大規模障害に発展します。技術が進歩して自動化や冗長化が進んだ今でも「人為的ミス」がシステムの信頼性を大きく左右していることに変わりはありません。
とはいえ、人が関わる以上、ヒューマンエラーを完全になくすことはできません。重要なのは「ミスが起きても深刻な障害に直結しないような仕組み」を事前に整えておくことです。日々の小さな工夫や改善の積み重ねこそが、システム全体の信頼性を大きく高めるカギとなります。
その具体的なアプローチとして、以下のような対策が考えられます。
- 複数人によるダブルチェックを行います。一人では見落としてしまう単純なミスも、複数人で確認することで早期に発見でき、重大な障害へ発展するリスクを大幅に減らすことができます。
- 聞き間違いなどを防ぐために文書化して伝達します。口頭での指示や伝達は、思い違いや聞き間違いが生じやすく、トラブルの温床となります。文書として残すことで、情報の解釈が統一され、後から振り返って確認することも可能になり、ヒューマンエラーの発生を大幅に抑えられます。
- エラーの発生機会を最小限に抑えるようにシステムを設計します。たとえば、適切に設計された抽象化、API、管理インタフェースなど。
- 人がミスをしやすい作業を、システム全体に直結させない工夫が大切です。そのために役立つのが「サンドボックス環境」です。これは、本番環境とは切り離された“練習用の場所”のようなもので、実際のデータを使いながらも安全に試行や実験ができます。たとえ操作を間違えても、本番サービスに影響が出ることはないため、安心して作業できるのです。
- ユニットテストからシステム全体の結合テスト、手動テストまで、あらゆるレベルで徹底的にテストを行います。
- ミスが起きてもすぐに元に戻せる仕組みを用意します。例えば、設定変更を素早く元に戻したり(ロールバック)、新しいコードを徐々に展開したり(段階的リリース)、データを再計算するためのツールを提供したりします。
- パフォーマンスメトリクスやエラー率など、詳細かつ明確なモニタリングを設定します。他のエンジニアリング分野では、これはテレメトリと呼ばれています。
信頼性の重要性
信頼性は、単なる技術的な要件ではなく、あらゆるビジネスの成功に不可欠な要素です。突然、普段使っているアプリが動かなくなったとき、人はどんな気持ちになるでしょうか。
仕事が止まり、顧客対応が滞り、場合によっては取引そのものに影響が及ぶかもしれません。わずか数分の障害であっても、ユーザーの信頼は簡単には戻りません。私はこの現実を何度も目にしてきました。
信頼性は、単なる技術的な指標ではなく、「安心して使える」という信頼を生み出すための基盤です。社会のさまざまな分野でシステム障害が発生し、利用者が長時間サービスを利用できなくなる事例も少なくありません。こうした出来事は、信頼性の欠如がどれほど大きな影響を及ぼすかを改めて示しています。ひとたび信頼が失われれば、企業は多大な損失を被り、ブランド価値を取り戻すには長い時間がかかります。
また、たとえ規模の小さなアプリケーションであっても、ユーザーが不便や不安を感じれば「このサービスは大丈夫だろうか」という疑念が生まれます。信頼は積み上げるのに時間がかかりますが、失うのは一瞬です。だからこそ、コスト削減やスピードを優先する場面でも、「信頼性をどこまで確保すべきか」を常に意識することが欠かせません。
私にとって信頼性とは、「止まらない仕組み」をつくること以上に、「誰かが安心して使い続けられる体験」を守ることです。技術の進歩や市場の変化がどれほど速くても、最終的に選ばれるのは“信頼できるサービス”です。信頼性を追求する姿勢こそが、ビジネスを長く、強く支える力になるのだと信じています。
まとめ
信頼性について学べば学ぶほど、それは単なるシステム設計の一要素ではなく、「人との信頼関係」と本質的に同じだと感じます。どんなに優れた技術や仕組みがあっても、使う人が「このサービスなら安心できる」と思えなければ、それは本当の意味で信頼されているとは言えません。
フォールトやエラー、人為的なミス――それらは避けられない現実です。しかし、それらを前提に「どうすれば影響を最小限にできるか」「どうすればすぐに立ち直れるか」を考え続けることこそが、信頼性の本質だと思います。つまり、「壊れない」ことよりも、「壊れても止まらない」ことが大切なのです。
クラウドサインのような日常的に使われるサービスでは、ちょっとした遅延や不具合でもユーザー体験に直結します。だからこそ、一つひとつの改善や検証の積み重ねが、目には見えなくても確実に「安心して使える」体験を支えています。私はその積み重ねの中に、エンジニアとしての責任とやりがいを強く感じています。
{kind=link}