
はじめに
全社データ技術局データインテグレーションチームに所属している與田龍人です。
Amazon S3 Tables を利用して Iceberg 形式でデータを管理すると、Iceberg テーブルの自動コンパクションやテーブル単位の権限制御が可能になります。これにより、従来の S3 バケット運用に比べてクエリ性能とデータガバナンスの両立が容易になります。
そこで今回は、Claude から自然言語で質問を送ると、自動で対応する SQL クエリを生成し、Athena がそのクエリを実行して結果を JSON と要約付きで返す仕組みを構築します。
Lambda 関数は MCP(Model Context Protocol)サーバーとして動作し、Bedrock の Guardrails や監査ログを経由しながら、Claude(ブラウザ版)から test_connection、text_to_sql、execute_query、 fetch_query_resultsといったツールを呼び出せるようになっています。
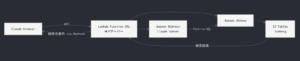
アーキテクチャと狙い
具体的なシステムは以下の流れを想定しています。
-
Claude から質問送信
-
SQL クエリ自動生成
-
Athena でクエリ実行
-
結果と要約を返却
Lambda は MCP サーバーとして、Bedrock の Guardrails や監査ログを経由しつつ、ベタ書き SQL を意識せず Iceberg テーブルを操作可能です。質問文・生成 SQL・実行結果はすべて監査ログに残るため、データガバナンスや性能改善に活用できます。
構築の手順について
前提条件
構築には以下の前提条件を満たしていることを想定しています。
Amazon S3 Tables / Iceberg テーブル
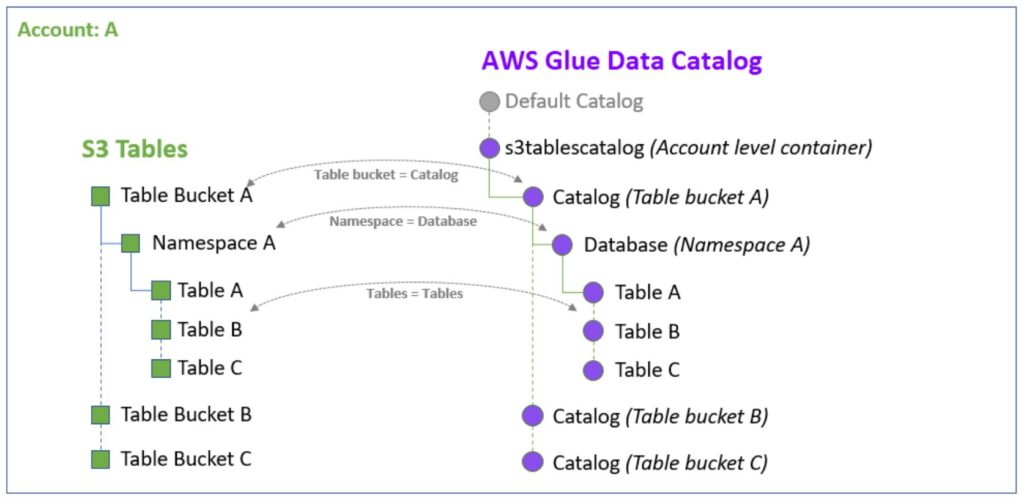
出典 : Amazon S3 Tables integration with AWS analytics services overview
Amazon Athena
-
-
S3 Tables の Iceberg テーブルを Athena からクエリできる状態であること。
-
Athena カタログ(例:
AwsDataCatalog)やワークグループ(例:primary)が設定済みであること。
-
AWS アカウント / 権限
IAM ロールを整える
Lambda が Bedrock と Athena を呼べるように、実行ロールを作成します。まずは信頼ポリシー付きのロールを作成しました。
aws iam create-role --role-name text2sql-lambda-execution-role --assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'検証ではAmazonAthena、AmazonS3、AWSGlueServiceRoleなどフルアクセス系のポリシーをまとめて付与しました。本番では最小権限に削ることがベストです。
aws iam attach-role-policy --role-name text2sql-lambda-execution-role --policy-arn arn:aws:iam::aws:policy/AmazonAthenaFullAccess
aws iam attach-role-policy --role-name text2sql-lambda-execution-role --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess
aws iam attach-role-policy --role-name text2sql-lambda-execution-role --policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
aws iam attach-role-policy --role-name text2sql-lambda-execution-role --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRoleBedrock と Lake Formation へのアクセスはカスタムポリシーで許可しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [ "bedrock:InvokeModel" ],
"Resource": "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0"
},
{
"Effect": "Allow",
"Action": [ "lakeformation:GetDataAccess" ],
"Resource": "*"
}
]
}aws iam put-role-policy --role-name text2sql-lambda-execution-role --policy-name LambdaBedrock-S3TablesPolicy --policy-document file://lambda-custom-policy.jsonLake Formation で Iceberg の権限を発行
Iceberg テーブルは IAM だけではアクセスできないので、Lake Formation でも DESCRIBE / SELECT を付与します。
aws lakeformation grant-permissions --principal DataLakePrincipalIdentifier=arn:aws:iam::123456789012:role/text2sql-lambda-execution-role --permissions "DESCRIBE" --resource '{"Database": {"CatalogId": "123456789012", "Name": "data_catalog_link"}}'
aws lakeformation grant-permissions --principal DataLakePrincipalIdentifier=arn:aws:iam::123456789012:role/text2sql-lambda-execution-role --permissions "DESCRIBE" --resource '{"Database": {"CatalogId": "123456789012:s3tablescatalog/demo-bucket", "Name": "analytics_namespace"}}'
aws lakeformation grant-permissions --principal DataLakePrincipalIdentifier=arn:aws:iam::123456789012:role/text2sql-lambda-execution-role --permissions "SELECT" "DESCRIBE" --resource '{"Table": {"CatalogId": "123456789012:s3tablescatalog/demo-bucket", "DatabaseName": "analytics_namespace", "Name": "slack_messages"}}'テーブルにテストデータを追加
今回の例ではSlackでのメッセージデータを想定して、締切を 10 月 20 日とするメッセージを 1 レコード Iceberg テーブルに入れておきました。
INSERT INTO "AwsDataCatalog"."MCP_DEMO_DB"."slack_messages"
VALUES (
'MSG-20251008-001',
'20251008103015999',
'message_posted',
'C1234567890',
'official-announcements',
'U000BOSS001',
'各位、S3Tables MCP の初回リリースは 10月20日 が締切です。遅延厳禁でお願いします。',
'T1234567890',
'EVT-20251008-001',
current_timestamp,
date(current_timestamp)
);Lambda コードについて
lambda_function.py では以下のコードを記述しました。詳細はコード内に記載しています。MCPLambdaHandler を使うので、後で依存ライブラリを zip にまとめてアップロードします。
from __future__ import annotations
import json
import os
import time
from typing import Any, Dict, List, Optional
import boto3
# グローバルクライアント: ウォームスタート時に接続を再利用するために生成
AWS_REGION = os.environ.get("AWS_REGION", "us-west-2")
bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION)
athena_client = boto3.client("athena", region_name=AWS_REGION)
s3_client = boto3.client("s3", region_name=AWS_REGION)
# Lambda変数。※本番では環境変数に置き換えてください。
DEFAULT_DATABASE = os.environ.get("DATABASE_NAME", "MCP_DEMO_DB")
DEFAULT_TABLE = os.environ.get("TABLE_NAME", "MCP_DEMO_TABLE")
DEFAULT_CATALOG = os.environ.get("ATHENA_CATALOG", "AwsDataCatalog")
DEFAULT_WORKGROUP = os.environ.get("ATHENA_WORKGROUP", "primary")
DEFAULT_OUTPUT_LOCATION = os.environ.get(
"ATHENA_OUTPUT_LOCATION", "s3://mcp-demo-athena-results/"
)
DEFAULT_BEDROCK_MODEL_ID = os.environ.get(
"BEDROCK_MODEL_ID", "anthropic.claude-3-5-sonnet-20240620-v1:0"
)
# MCP ハンドラーの初期化。
try:
from awslabs.mcp_lambda_handler import MCPLambdaHandler
except ImportError:
class MCPLambdaHandler: # type: ignore
def __init__(self, name: str, version: str) -> None:
self.name = name
self.version = version
self.tools: Dict[str, Any] = {}
def tool(self):
def decorator(func):
self.tools[func.__name__] = func
return func
return decorator
def handle_request(self, event: Dict[str, Any], context: Any) -> Dict[str, Any]:
return {
"statusCode": 500,
"body": json.dumps(
{"error": "MCP runtime unavailable - deploy inside AWS Lambda."}
),
}
def _get_mcp_handler() -> MCPLambdaHandler:
return MCPLambdaHandler(name="bedrock-athena-s3tables", version="1.0.0")
mcp = _get_mcp_handler()
# Athena / Bedrock で使う補助関数
def _normalise_catalog(catalog: Optional[str]) -> str:
return catalog or DEFAULT_CATALOG
def _normalise_database(database: Optional[str]) -> str:
return database or DEFAULT_DATABASE
def _normalise_table(table: Optional[str]) -> str:
return table or DEFAULT_TABLE
def _build_prompt(nl_query: str, catalog: str, database: str, table: str) -> str:
"""Bedrock Claude に渡す Text-to-SQL プロンプトを組み立てる。"""
return (
"You are an expert SQL assistant for Amazon Athena. "
"Generate only a SQL query (no commentary) that answers the user request.\n\n"
"Table information:\n"
f"- Catalog: {catalog}\n"
f"- Database: {database}\n"
f"- Table: {table}\n"
'- Fully qualified form: "{catalog}"."{database}"."{table}"\n'
"Columns include: message_id, message_ts, event_type, channel, channel_name, "
"user, text, team_id, event_id, event_time, processed_date.\n\n"
"Requirements:\n"
"1. Output only valid Athena SQL.\n"
"2. Always use the fully qualified 3-part identifier.\n"
"3. Use DATE/TIMESTAMP helpers when filtering temporal fields.\n\n"
f"Natural language request: {nl_query}\n\nSQL query:"
).format(catalog=catalog, database=database, table=table)
def _invoke_bedrock(prompt: str) -> str:
"""Bedrock Claude を呼び出し、不要な Markdown を取り除いて SQL を返す。"""
response = bedrock_runtime.invoke_model(
modelId=DEFAULT_BEDROCK_MODEL_ID,
body=json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 800,
"temperature": 0,
"messages": [{"role": "user", "content": prompt}],
}
),
)
body = json.loads(response["body"].read())
text = body["content"][0]["text"].strip()
if text.startswith("```sql"):
text = text[6:]
if text.endswith("```"):
text = text[:-3]
return text.strip()
def _start_athena_query(sql: str, catalog: str, database: str) -> str:
"""Athena クエリを開始し、実行 ID を返す。"""
execution = athena_client.start_query_execution(
QueryString=sql,
QueryExecutionContext={"Catalog": catalog, "Database": database},
ResultConfiguration={"OutputLocation": DEFAULT_OUTPUT_LOCATION},
WorkGroup=DEFAULT_WORKGROUP,
)
return execution["QueryExecutionId"]
def _wait_for_query(query_execution_id: str, timeout: int = 60) -> str:
"""Athena のクエリ完了をポーリングで待つ。タイムアウト時は例外を送出。"""
start = time.time()
while time.time() - start List[Dict[str, Any]]:
"""Athena の結果セットを全件取得して返す。"""
columns: List[str] = []
next_token: Optional[str] = None
rows: List[Dict[str, Any]] = []
while True:
params: Dict[str, Any] = {
"QueryExecutionId": query_execution_id,
"MaxResults": 1000,
}
if next_token:
params["NextToken"] = next_token
response = athena_client.get_query_results(**params)
if not columns:
metadata = response["ResultSet"]["ResultSetMetadata"]["ColumnInfo"]
columns = [col["Label"] for col in metadata]
result_rows = response["ResultSet"].get("Rows", [])
start_idx = 1 if not next_token else 0 # 最初のバッチのみヘッダをスキップ
for row in result_rows[start_idx:]:
data = row.get("Data", [])
rows.append(
{
columns[i] if i str:
"""結果を要約するために Bedrock Claude を再利用する。"""
if not results:
return "該当するレコードは見つかりませんでした。"
preview = "\n".join(
f"行{i+1}: {row.get('text', '')}" for i, row in enumerate(results[:10])
)
# プロンプトによる出力制御
prompt = (
"以下の Athena 結果をもとに、ユーザーの質問に日本語で回答してください。\n\n"
f"ユーザーの質問: {nl_query}\n\n"
"結果プレビュー:\n"
f"{preview}\n\n"
"出力条件:\n"
"- 重要ポイントを箇条書きで示す\n"
"- 固有名詞があれば残す\n"
"- 200文字以内"
)
try:
response = bedrock_runtime.invoke_model(
modelId=DEFAULT_BEDROCK_MODEL_ID,
body=json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 400,
"temperature": 0.1,
"messages": [{"role": "user", "content": prompt}],
}
),
)
body = json.loads(response["body"].read())
return body["content"][0]["text"].strip()
except Exception:
snippet = json.dumps(results[0], ensure_ascii=False)[:180]
return f"回答生成に失敗したため、最初のレコードを返します: {snippet}"
# MCP ツール定義
@mcp.tool()
def test_connection() -> str:
"""環境情報とクエリ実行時の注意点を返す。"""
return "\n".join(
[
"Bedrock + Athena MCP Lambda is ready!",
"",
"Configuration:",
f" - AWS_REGION: {AWS_REGION}",
f" - CATALOG: {DEFAULT_CATALOG}",
f" - DATABASE: {DEFAULT_DATABASE}",
f" - TABLE: {DEFAULT_TABLE}",
f" - WORKGROUP: {DEFAULT_WORKGROUP}",
f" - ATHENA_OUTPUT_LOCATION: {DEFAULT_OUTPUT_LOCATION}",
f" - BEDROCK_MODEL_ID: {DEFAULT_BEDROCK_MODEL_ID}",
"",
"Query tips:",
" - 先頭で `USE CATALOG AwsDataCatalog;` や `USE MCP_DEMO_DB;` を宣言すると安全です。",
" - Iceberg テーブルは \"Catalog\".\"Database\".\"Table\" 形式の引用符が必須です。",
" - 自然文は text_to_sql で SQL を確認してから execute_query を実行すると安全です。",
]
)
@mcp.tool()
def text_to_sql(
natural_language_query: str,
catalog: Optional[str] = None,
database: Optional[str] = None,
table: Optional[str] = None,
) -> str:
"""自然言語を Athena の SQL に変換して JSON で返す。"""
if not natural_language_query:
raise ValueError("natural_language_query is required")
catalog = _normalise_catalog(catalog)
database = _normalise_database(database)
table = _normalise_table(table)
sql = _invoke_bedrock(_build_prompt(natural_language_query, catalog, database, table))
return json.dumps(
{
"success": True,
"catalog": catalog,
"database": database,
"table": table,
"sql": sql,
},
indent=2,
)
@mcp.tool()
def execute_query(
natural_language_query: Optional[str] = None,
sql_query: Optional[str] = None,
catalog: Optional[str] = None,
database: Optional[str] = None,
table: Optional[str] = None,
) -> str:
"""自然言語または SQL を受け取り、Athena 実行から要約まで行う。"""
if not natural_language_query and not sql_query:
raise ValueError("Either natural_language_query or sql_query must be provided")
catalog = _normalise_catalog(catalog)
database = _normalise_database(database)
table = _normalise_table(table)
sql = sql_query or _invoke_bedrock(
_build_prompt(natural_language_query or "", catalog, database, table)
)
execution_id = _start_athena_query(sql, catalog, database)
status = _wait_for_query(execution_id)
if status != "SUCCEEDED":
reason = athena_client.get_query_execution(QueryExecutionId=execution_id)[
"QueryExecution"
]["Status"].get("StateChangeReason", "Unknown")
raise RuntimeError(f"Athena query failed ({status}): {reason}")
rows = _collect_athena_rows(execution_id)
summary = _summarise_results(natural_language_query or sql, rows)
return json.dumps(
{
"success": True,
"catalog": catalog,
"database": database,
"table": table,
"sql": sql,
"query_execution_id": execution_id,
"row_count": len(rows),
"rows": rows,
"summary": summary,
},
indent=2,
ensure_ascii=False,
)
@mcp.tool()
def fetch_query_results(query_execution_id: str) -> str:
"""Athena の過去実行結果を再取得して返す。"""
if not query_execution_id:
raise ValueError("query_execution_id is required")
status = athena_client.get_query_execution(QueryExecutionId=query_execution_id)[
"QueryExecution"
]["Status"]["State"]
if status != "SUCCEEDED":
raise RuntimeError(f"Query execution {query_execution_id} is not successful: {status}")
rows = _collect_athena_rows(query_execution_id)
return json.dumps(
{
"success": True,
"row_count": len(rows),
"rows": rows,
},
indent=2,
ensure_ascii=False,
)
# Lambda エントリポイント
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
"""MCP の JSON-RPC リクエストを routing するエントリポイント。"""
if "requestContext" in event:
raw_body = event.get("body", "{}")
try:
payload = json.loads(raw_body) if isinstance(raw_body, str) else raw_body
except json.JSONDecodeError:
payload = {}
else:
payload = event
if isinstance(payload, dict) and payload.get("method"):
return mcp.handle_request(event, context)
raise ValueError("Unsupported request format - MCP JSON-RPC expected")依存ライブラリを zip にまとめてアップロード
awslabs.mcp_lambda_handler が必要なので、python3 -m pip install で依存をディレクトリに展開し、lambda_function.pyと共にアップロードしました。今回は依存ライブラリが軽量のためレイヤーは使用せずzipでまとめています。
mkdir -p package
cp lambda_function.py package/
python3 -m pip install awslabs-mcp-lambda-handler -t package/
python3 -m pip freeze > package/requirements.txt
(cd package && zip -r ../lambda-function-mcp.zip .)Function URL を有効化する
MCP から接続するため、Function URL を作成します。
今回はAPI Key 認証を Lambda 内で実装していますが、本番環境では AWS IAM 認証や API Gateway + Authorizer(Cognito / OIDC 等)の利用を推奨します。
Function URL を作成
認証なし設定(--auth-type NONE)ですが、Lambda 内で API Key 認証を実装しています。
aws lambda create-function-url-config \
--function-name bedrock-athena-s3tables \
--auth-type NONE \
--cors '{"AllowOrigins":["*"],"AllowMethods":["POST"],"AllowHeaders":["content-type"]}' \
--region us-west-2
パブリックアクセス権限を追加
aws lambda add-permission \
--function-name bedrock-athena-s3tables \
--statement-id function-url-public-access \
--action lambda:InvokeFunctionUrl \
--principal '*' \
--function-url-auth-type NONE \
--region us-west-2API Key 認証の実装(Lambda 内)
Lambda 関数内で以下のように API Key 認証を実装します。
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
# API Key認証
query_params = event.get("queryStringParameters", {}) or {}
api_key = query_params.get("key") or query_params.get("api_key")
expected_key = os.environ.get("MCP_API_KEY")
if not expected_key or api_key != expected_key:
return {
"statusCode": 401,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"error": "Invalid or missing API key"})
}環境変数に MCP_API_KEY を設定
aws lambda update-function-configuration \
--function-name bedrock-athena-s3tables \
--environment Variables="{"MCP_API_KEY":"your-secure-api-key-here"}" \
--region us-west-2動作確認
Function URL が発行されたら、API Key を付けてステータス 200 が返るか確認します。
API Key あり(200 正常動作):
curl -s -X POST "https://xxxx.lambda-url.us-west-2.on.aws/?api_key=your-secure-api-key-here" \
-H "Content-Type: application/json" \
-d '{"jsonrpc":"2.0","id":"health","method":"initialize","params":{}}'Claude でツールを試す
Claude の UI 左下のアイコン → 設定 → コネクタ → カスタムコネクタを追加 をクリックし、以下を入力します。
-
コネクタ名:
s3tables-lambda-mcp -
リモート MCP サーバー URL:
https://xxxx.lambda-url.us-west-2.on.aws/?api_key=your-secure-api-key-here
![]()
チャットの設定に s3tables-lambda-mcp が表示されます。
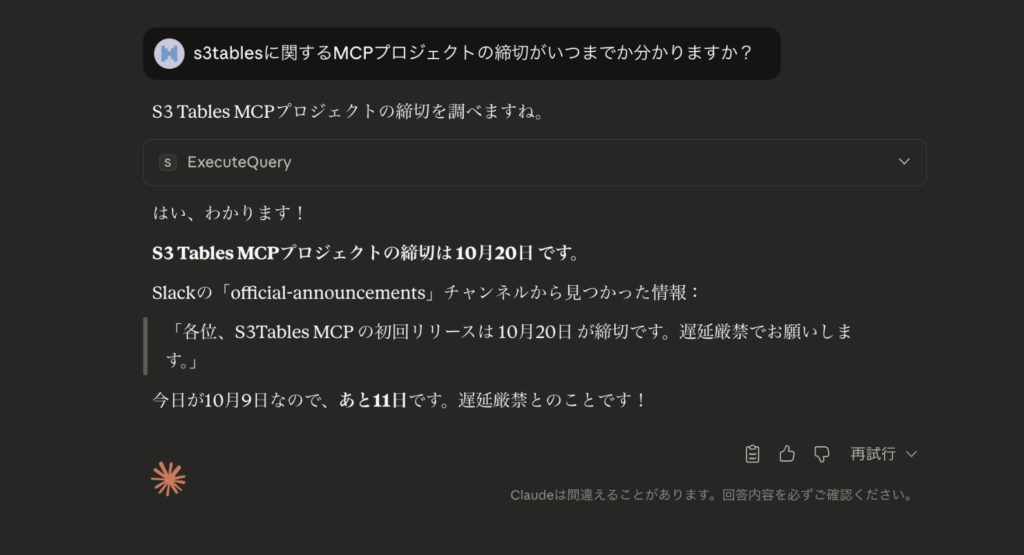
「s3tablesに関するMCPプロジェクトの締切がいつまでか分かりますか?」と尋ねると、メッセージを拾って初回リリースが 10 月 20 日だと要約してくれました。
おわりに
これで、Claude から Athena を経由して S3 Tables に自然言語でアクセスできるサーバーレス MCP 環境が完成しました。MCP サーバーを通じて自然文でデータにアクセスできるため、社内のちょっとした「締切いつ?」のような問い合わせにも素早く応答できるようになりました。
今後は、execute_query にクエリバリデーションを追加して安全性を高めたり、SSO や権限管理を導入して Lambda や S3 Tables へのアクセスを厳密に制御してみたいと思います。今回構築した環境をベースに、社内外向けの自然言語検索やデータ活用の参考として役に立てれば幸いです。
参考
{kind=link}