
はじめに
こんにちは、山本です。
今回は、AWS Glue を使って Amazon S3 にあるデータを Amazon Redshift に取り込むと、ジョブを再実行するたびに同じレコードが重複して登録される現象の解決方法について当記事で紹介します。
AWS Glue は Amazon S3 などに保存されているデータを分析用の Amazon Redshift などに適宜データを加工して保存する便利なサービスです。
しかし、ジョブ( Amazon S3 データ抽出から Amazon Redshift へのデータ出力までの処理)の内容によってはAWS Glue ジョブの特性上、加工したデータが重複してしまい想定外の処理結果になってしまうことがしばしばあるようです。
当記事では、この AWS Glue ジョブでの Amazon S3 内データから Amazon Redshift への取り込みで重複を防ぐために、ステージングテーブルと SQL を組み合わせたシンプルな解決策を紹介します。
現象の再現
たとえば、次のようなCSVファイルを Amazon S3 に置いて AWS Glue で Amazon Redshift にデータをロードするケースを考えます。
id,name 1,Alice 2,Bob
Amazon Redshift に users テーブルを用意して直接 AWS Glue ジョブを通して処理すると、1回目の実行後は以下のようになります。
select * from users; 1 | Alice 2 | Bob
ここで同じジョブをもう一度実行すると……
select * from users; 1 | Alice 2 | Bob 1 | Alice 2 | Bob
上記のように Amazon Redshift の users テーブル内のデータに重複が発生してしまいます。
つまり、何らかの原因で AWS Glue ジョブが二度実行されると想定していないデータ重複が発生してしまうというわけです。
この現象は、AWS Glue のジョブでは読み込んだデータ自体が「同じファイルかどうか」、「すでに登録済みかどうか」を判定せずに Amazon Redshift に直接データを追加してしまうという仕様が起因しています。
したがって、ジョブが複数回繰り返して再実行された場合にもデータの重複を許さないように対策する必要があります。
解決策:ステージングテーブル+SQL
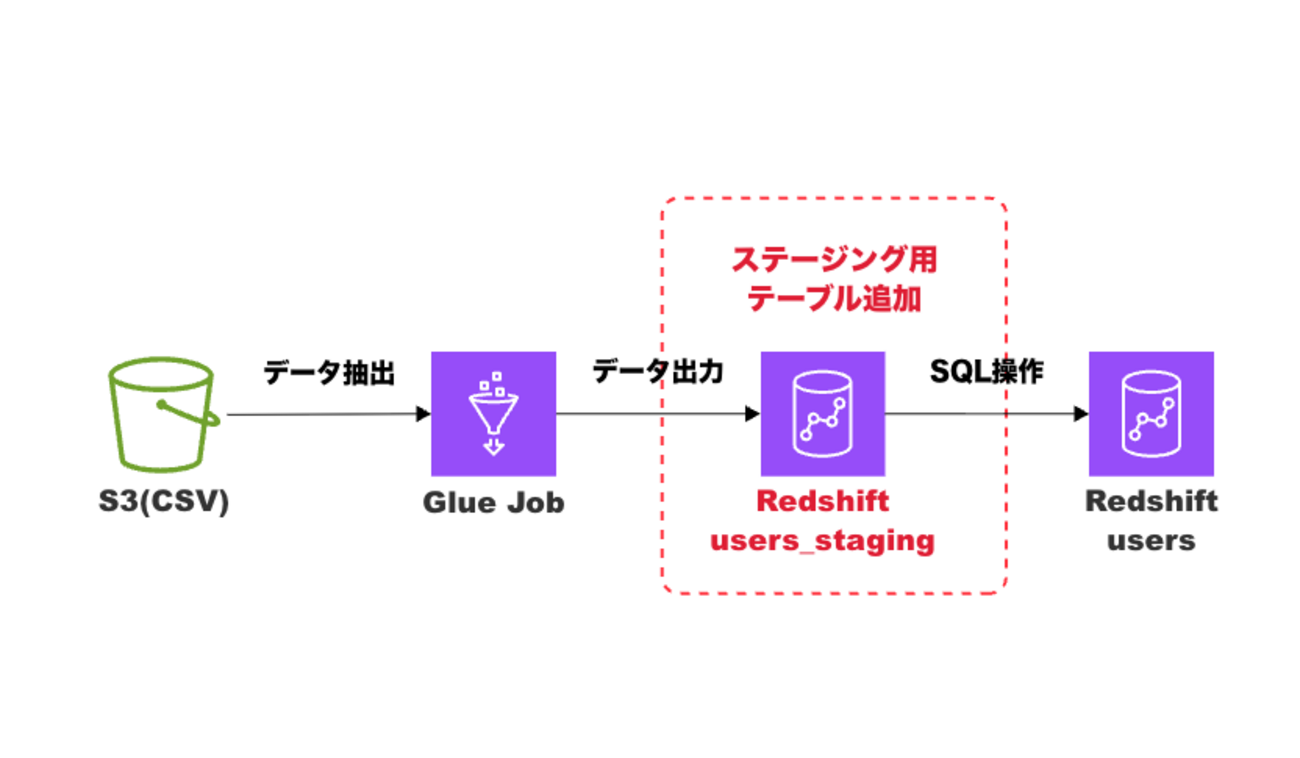
そこで登場するのが ステージングテーブル方式 です。
概念的な流れは以下の通りです。

上図のようにステージング用のテーブルを挟むメリットとして以下が挙げられます。
- ステージング用のテーブルでは重複を許容するので、 AWS Glue 側は「ただのデータロード処理」構成のままにすることが可能
※「データロード処理」はデータの投入のみを行うという意味です。 - 重複排除や更新ロジックは Amazon Redshift 側の SQL 処理に任せられる
- データロード処理時における重複を防げるので、データの整合性をデータベースの責任範囲のみに収められる
実装例
まずはステージングテーブルを用意します。
create table users_staging ( id int, name varchar(50) );
AWS Glue の出力先を users ではなく users_staging に変更します。
AWS Glue ジョブが終わったら、Amazon Redshift 側で以下の SQL を実行して本番テーブル(usersテーブル)に反映します。
update users set name = s.name from users_staging s where users.id = s.id; insert into users (id, name) select s.id, s.name from users_staging s left join users u on u.id = s.id where u.id is null; truncate table users_staging;
※補足
RedshiftのTRUNCATE TABLEはDDL扱いで、処理が実行されると同時に即時コミットされます。
そのため、UPDATEやINSERTでエラーが発生した場合、TRUNCATEの実行によってステージングテーブルのデータが消えてしまい、ロールバックできなくなる点に注意してください。
運用上、トランザクション管理やエラー時のリカバリを考慮する場合は、TRUNCATEのタイミングや処理方法を工夫することも検討しましょう。
上記 SQL を実行することで、ステージング用のテーブルで重複が発生していた場合でも正常にデータが追加されている場合でも問題なく本番用 users テーブルにデータを反映することができます。
実行結果
実装例にて定義した内容で以下CSVに対して処理を実行すると結果は以下のような流れになります。
id,name 1,Alice 2,Bob
1回目のジョブ実行 : users_staging に Alice, Bob が入り、SQL 実行後 users に反映。
2回目のジョブ実行 : users_staging にまた Alice, Bob が入るが、SQL で更新のみ行われ、重複は発生しない。
select * from users; 1 | Alice 2 | Bob
最終的な users テーブルの状態に関しても問題なくデータが追加されていることがわかります。
おわりに
いかがでしたでしょうか。
AWS Glue ジョブで Amazon S3 から Amazon Redshift に直接データを流し込むと一見シンプルで便利そうに見えますが、今回紹介したようにジョブの再実行時に同じレコードが重複してしまうという落とし穴があります。
このような場合、無闇に AWS Glue ジョブを問題視して設定を複雑にするよりも今回のように
- AWS Glue 側には単純にデータロード処理だけを担わせる
- 重複排除や更新判定は Amazon Redshift 側の SQL 処理に担わせる
というような役割分担をさせることでデータの整合性をシンプルかつ確実に担保できるだけでなく、エラーが起こった場合の原因切り分けがしやすくなるというメリットがあります。
今回紹介した設計はAWS の公式ドキュメントやナレッジでも推奨される「データウェアハウスにおける大規模データロードのベストプラクティス」の一つで、「安定して再実行できるETL基盤を作る」ための基本形だといえると思います。
実際のプロジェクトやAWSのデータエンジニア資格の試験問題にもケースとして取り上げられる問題なのでぜひ参考にしてみて下さい!
{kind=link}